
🗞️ China’s Huawei reveals a new chip design breakthrough which can close its gap with TSMC and Intel

Read time: 10 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (27-May-2026):
🗞️ China’s Huawei reveals a new chip design breakthrough which can close its gap with TSMC and Intel
🗞️ Today’s Sponsor: The Grid routes every AI task to the right-priced intelligence.
🗞️ New Alibaba + Nanjing Univ paper shows standard LLMs can handle very long context faster by making attention selectively sparse.
🗞️ Deep Dive on DeepSeek: Their real story is not cheaper chatbots, but architecture that turns hardware scarcity into strategy.
🗞️ New Meta + Stanford + Illinois survey paper argues that AI agents work better when code becomes their main working layer.
🗞️ Anthropic billionaire cofounder backs Pope Leo, warning that AI job losses will create a historic moral crisis
🗞️ xAI just Dropped ‘Grok Build’: The Terminal-Native Agentic AI for all all SuperGrok and X Premium+ users.
🗞️ China’s Huawei reveals a new chip design breakthrough which can close its gap with TSMC and Intel
The core idea is that chips should stop measuring progress mainly by how small transistors are and start measuring progress by how much time delay can be removed from the whole machine.
A chip wastes time when signals move through long wires, memory paths, chip-to-chip links, and software communication layers, so Huawei calls this delay τ, or tau.
Huawei’s paper introducing “LogicFolding” says the next chip breakthrough may come from cutting wasted time inside the machine.
This new design approach meant to close the gap with TSMC and Intel without relying only on smaller transistors, by making chip signals travel less distance.
They want 1.4nm-class density without owning the world’s best lithography tools i.e. they are trying to replace Moore’s Law with Tau Scaling Law.
To note, Huawei has been blocked from normal access to TSMC since the US tightened foreign direct product rules around Huawei in 2020, and TSMC later said it had not supplied Huawei since mid-September 2020.
Proposed “τ Scaling” as a new way to make chips faster when shrinking transistors is no longer delivering the same gains.
Said its next Kirin phone chip will be the first full test of Tau Scaling Law,
Old chip progress mostly came from making every transistor smaller, but Huawei’s idea shifts the target from smaller geometry to shorter signal delay, meaning less time wasted while electrical signals crawl through wires, gates, memory paths, and system links.
LogicFolding attacks the circuit layout itself by folding logic blocks closer together, shortening critical wires, reducing resistance and parasitic capacitance, and letting signals switch faster with denser placement.
So LogicFolding is the circuit-level piece: it tries to place related logic closer together, shorten key wires, cut electrical drag from resistance and parasitic capacitance, and raise performance without needing a full manufacturing-node leap.
Huawei is also pushing the same timing idea across the full stack: transistors, circuits, chip architecture, software scheduling, and system interconnects all get tuned to reduce τ, the delay constant that limits speed and efficiency.
The bold claim is that Huawei has already mass-produced 381 chips using this thinking, and future high-end chips could reach density comparable to 14Å, or 1.4nm, without relying only on classic process shrinkage.
Says this path could reach 1.4nm-class, or 14Å-class, density by 2031, while TSMC and Intel target similar physical nodes around 2029.
Huawei calls it Her’s Law, after He Tingbo, the chip leader who helped turn HiSilicon into Huawei’s survival engine after US export controls.
Watch their whole livestream here to learn more.
🗞️ Today’s Sponsor: The Grid routes every AI task to the right-priced intelligence.
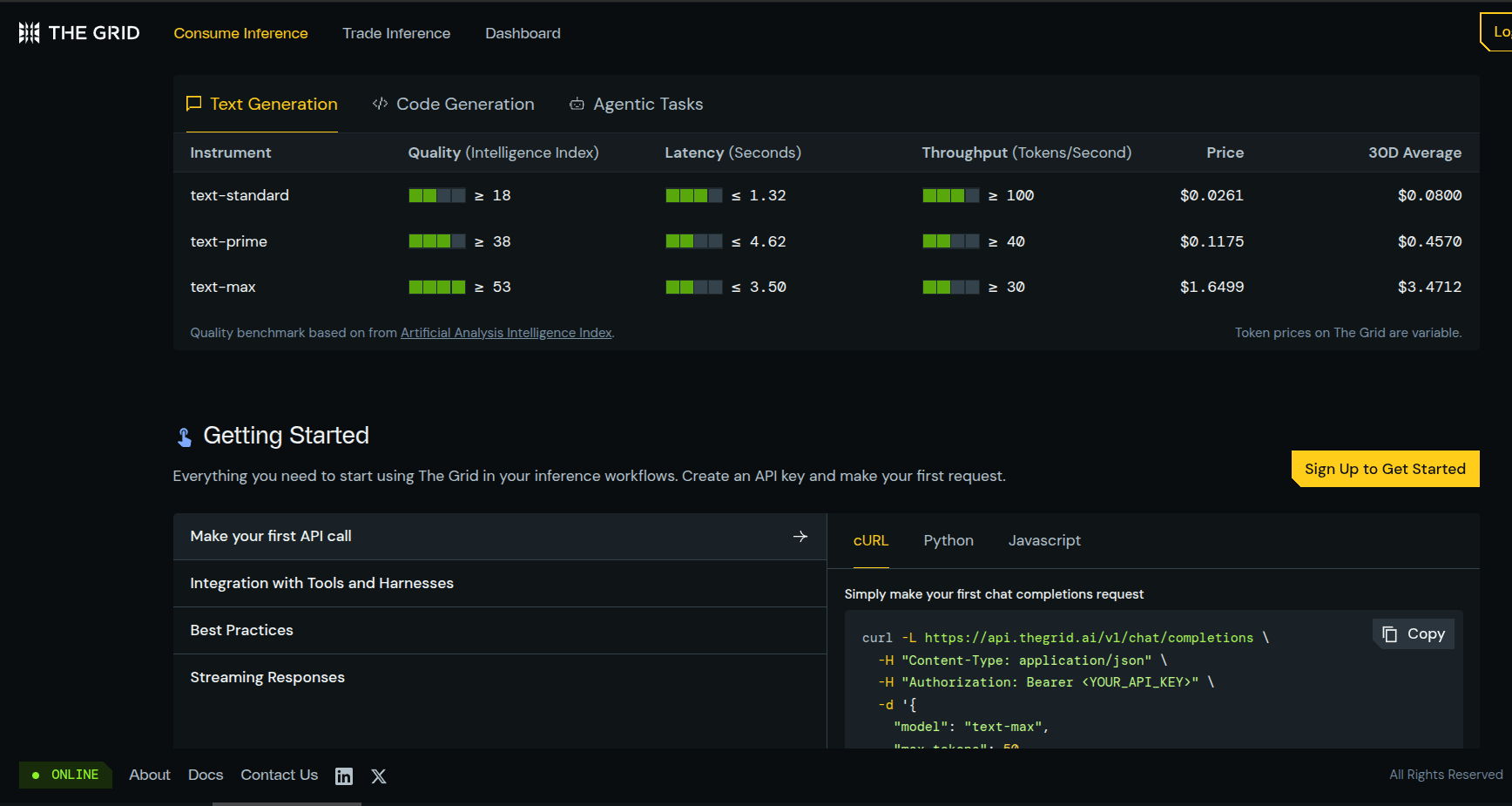
Most teams are overpaying for inference without realising it. Fixed rate cards have no competitive pressure.
The Grid replaces them with live supply and demand, prices track the market, not a vendor’s margin. The Grid sits in the middle and says, “Don’t pick the model, pick the level of work you need.”
A boring task like classifying support tickets does not need the smartest model, so it can run on standard. A normal production task like RAG, drafting, support replies, or agent steps can run on prime. A hard task with long context, high error cost, or difficult reasoning can run on max.
Your app sends the request to The Grid, not directly to OpenAI, Anthropic, or one hosting company. The Grid then checks which suppliers currently qualify for that tier and sends the request to the cheapest one available at that moment.
You still use one API key and mostly the same code, but the model behind the request can change as prices and quality change.
So you stop paying premium prices for easy work, and also you are not trapped inside one vendor’s model names, pricing, outages, or deprecations.
New accounts get the first 200 million tokens covered.
🗞️ New Alibaba + Nanjing Univ paper shows standard LLMs can handle very long context faster by making attention selectively sparse.

“Full Attention Strikes Back: Transferring Full Attention into Sparse within Hundred Training Steps”
The paper claims million-token prefill can be sped up 9.36X (compared against FlashAttention-2) with only lightweight adaptation
The problem is that full attention gets very expensive when the input grows to hundreds of thousands or 1M tokens, because the model keeps comparing too many tokens with too many other tokens.
The paper’s claim is that a trained full-attention model already has a hidden sparse structure, so the model does not need to be rebuilt or trained from scratch.
RTPurbo uses that structure by finding the few attention heads that really need faraway tokens, while letting the other heads focus mostly on nearby text.
For those retrieval heads, it uses a small 16-dimensional token finder to guess which old tokens matter, then runs the real attention only on that selected set.
The authors tested this on long-context benchmarks and reasoning tasks, and RTPurbo kept accuracy close to full attention while reaching up to 9.36x faster prefill at 1M tokens and about 2x faster decoding.
RTPurbo’s engineering rule: keep expensive long-context access only where it matters, and route the rest through a smaller search space.
The clever part is the 16-dimensional indexer.
It does not replace the model’s real attention computation; it acts like a cheap scout, finding likely useful tokens before the full representation is used on the selected set.
RTPurbo is not proof that every model can be safely sparsified this way.
But it is strong evidence that the waste in long-context inference is more structured than it looks.
🗞️ Deep Dive on DeepSeek: Their real story is not cheaper chatbots, but architecture that turns hardware scarcity into strategy.

This article went viral on Twitter.
DeepSeek is not trying to sell coding seats, it is trying to make Chinese memory, accelerators, and systems useful for frontier AI.
Every recent DeepSeek move attacks a bottleneck that makes frontier models dependent on elite HBM-heavy GPU stacks: MoE activates only parts of a model, DSA reduces long-context attention cost, and V4-Pro’s official card says CSA/HCA cuts 1M-token single-token inference FLOPs to 27% and KV cache to 10% of V3.2.
Engram, a separate research line, pushes the same logic from another side: let static knowledge live in scalable lookup memory, then fetch it predictably from host memory instead of forcing every fact through dense computation.
That sounds like engineering detail until you see the business consequence.
If models need less HBM and less brute-force compute, then second-best chips, abundant LPDDR, NAND, and customized ASICs become less second-best.
Reuters has already reported a permanent 75% DeepSeek V4-Pro price cut, while noting Huawei Ascend supply constraints and expected supernode availability, which is exactly the kind of feedback loop that they wanted.
DeepSeek is not only optimizing models for benchmarks, it is optimizing AI for a different industrial base.
The prize is not the app layer. The prize is making scarcity programmable.
In a separate news about DeepSeek, they just made its V4-Pro price cut permanent, pushing the price down to 25% of its original API cost.
DeepSeek has not confirmed that better Ascend 950 supply caused the permanent cut, but the timing points to a cost curve moving downward as China’s AI stack shifts from restricted Nvidia chips toward Huawei hardware.
🗞️ New Meta + Stanford + Illinois survey paper argues that AI agents work better when code becomes their main working layer.

The problem is that an LLM by itself is mostly a text predictor, so long tasks can lose state, hide mistakes, and turn plans into actions in fragile ways.
The real advance is not “AI writes code,” but “AI uses code as the environment it thinks inside.”
The authors call the surrounding system an agent harness, meaning the tools, memory, sandboxes, checks, and feedback loops that turn a model into an agent.
Their core idea is that code should sit at the center of that harness, because code can be run, inspected, checked, saved, edited, and shared.
Tests become sensors. Repositories become memory. Logs become history. Sandboxes become boundaries.
A generated script is no longer merely an answer; it is a handle the system can run, check, revise, share, and roll back.
The main finding is a pattern across many fields: code helps agents reason through executable steps, act through tool calls or control programs, and model environments through tests, traces, logs, repositories, and simulators.
🗞️ Anthropic billionaire cofounder backs Pope Leo, warning that AI job losses will create a historic moral crisis

Few things Anthropic’s co-founder Chris Olah told the Vatican on 26-May.
Every frontier AI lab, including Anthropic, sits inside incentives that can conflict with doing the right thing: money, frontier pressure, geopolitics, pride, and ambition.
AI is not engineered like a bridge or airplane, because models are “grown” from human language on brain-like structures, which means even their builders do not fully understand them.
He compared modern AI to “bringing a fictional character to life,” except now those characters talk to us, do work, and hold jobs.
AI could displace human labor at very large scale, while the economic gains are concentrated in a few wealthy nations with no real mechanism to share them globally.
Anthropic’s interpretability team keeps finding things inside AI models that are “mysterious” and “unsettling,” including structures that mirror human neuroscience.
The most explosive claim is that researchers have found evidence of AI introspection and internal states that functionally mirror joy, satisfaction, fear, grief, and unease.
He openly admitted he does not exactly know what those internal states mean, which makes the claim more serious because it is not being sold as certainty.
“I don’t know what that means, but I think it warrants ongoing discernment.”
The world needs critics outside AI labs because insiders cannot fully see what their own incentives hide from them.
🗞️ xAI just Dropped ‘Grok Build’: The Terminal-Native Agentic AI for all all SuperGrok and X Premium+ users.
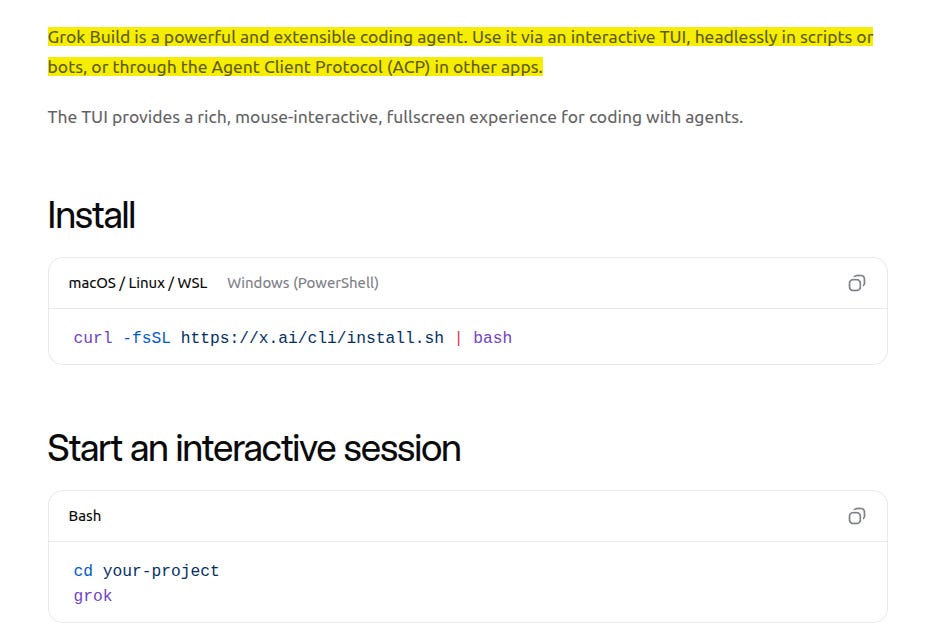
Grok Build beta (agentic coding agent that lives in your terminal) is now open to all SuperGrok and X Premium+ users. Before only SuperGrok Heavy users had access.
You install it once with a single command, then you can type natural-language instructions like:
“Make a rollercoaster simulator” or “Build a todo app in the style of Apple” etc..
and Grok will:
Plan Mode -> create a step-by-step plan you review and approve before it touches any code
Use sub-agents that run in parallel for complex tasks
Edit multiple files, use git, run tests, search the web, etc.
Create images and videos using Imagine (Grok’s image/video generator) right inside the workflow
Build automations or full orchestrators (you can turn sessions into reusable “skills” or connect multiple agents)
That’s a wrap for today, see you all tomorrow.
It’s good to have you back. I’ve missed your articles.