
🏆 China's new open-source model GLM-4.5, Undercuts DeepSeek and GPT-4 on Price and Performance
Zhipu drops GLM-4.5, Edge gets Copilot Mode, Unitree's $6K robot does flips, and GPT-5 shows major gains in coding benchmarks.
Read time: 10 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (28-July-2025):
🏆 China's new open-source model GLM-4.5, Undercuts DeepSeek and GPT-4 on Price and Performance
📡 Microsoft just turned Edge browser into an AI agent with Copilot Mode.
🛠️ UnitreeRobotics just unveiled R1, it can run, cartwheel and fist-fight – and it costs just $6K
🧑🎓 GPT‑5 Release Imminent, Early Tests Show a Performance Leap on Coding
🏆 China's new open-source model GLM-4.5, Undercuts DeepSeek and GPT-4 on Price and Performance
Chinese AI startup Zhipu just released open-source model GLM-4.5 designed for intelligent agent applications.
Key Takeaway
Two versions, 355B and 106B parameters in total, run as a mixture of experts so only 32B or 12B weights stay active during a single forward pass which lowers GPU memory and cost.
A 128K token window lets the model ingest very long documents or tool traces without breaking context.
Separate “thinking” and “non‑thinking” modes let it spend big compute only when a prompt truly needs slow step‑by‑step reasoning, which keeps everyday queries fast.
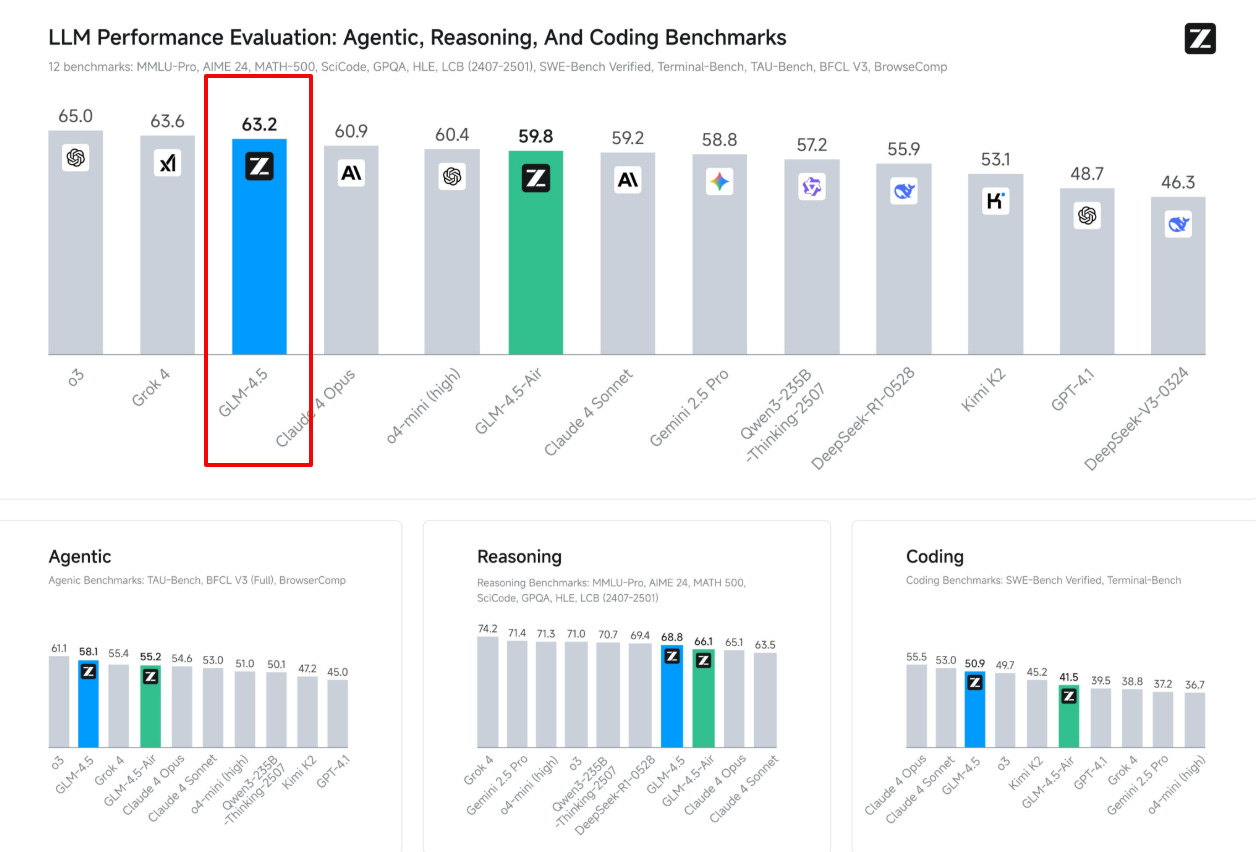
The model can run on just eight Nvidia H20 chips—half what DeepSeek requires—and ranks third overall across 12 AI benchmarks covering reasoning, coding, and agent tasks. These H20 chips are special versions of Nvidia's AI processors designed for China to comply with US export restrictions. They're less powerful than chips sold elsewhere but still capable enough for AI training. Z.ai uses them because that's what Chinese companies can legally buy due to trade limitations.
Combines three skills in one: structured reasoning for tough questions, code generation that fixes real GitHub issues, and built‑in function calling so agents can hit external tools or APIs without extra glue.
Scores 3rd on a blended leaderboard of 12 hard reasoning tests and its lighter “Air” edition lands 6th, showing that the scaled‑down model still competes.
Hits 84.6 on MMLU Pro, 91.0 on AIME24, and 79.1 on GPQA, placing it near GPT‑4 class models on academic reasoning.
Solves 64.2% of SWE‑bench Verified software bugs and reaches 37.5% on Terminal‑Bench, proving strong real‑world coding chops.
Wins 26.4% accuracy on BrowseComp, beating Claude‑4 Opus, which signals solid live web browsing and tool navigation ability.
Function calls succeed 90.6% of the time, topping Claude‑4 Sonnet, so agent pipelines rarely break on bad signatures.
A taller, narrow mixture‑of‑experts stack plus grouped‑query attention keeps math reasoning strong while holding latency down.
Training relied on “slime,” an open reinforcement learning setup that streams FP8 rollouts to fill buffers fast and applies BF16 updates for stability.
Extra multi‑token prediction heads enable speculative decoding, shaving off response time without hurting quality.
Weights and chat checkpoints live on public hubs, and an OpenAI‑style API is available, so anyone can slot it into existing tooling quickly.
🌍 Z.ai sits on the US entity list restricting American business, yet raised $1.5 billion from Alibaba, Tencent, and Chinese government funds for a planned IPO.
The standout idea is a tall, narrow mixture‑of‑experts stack. GLM‑4.5 shrinks each expert’s width but adds many more layers, so only 32B of the 355B weights fire on a pass while extra depth lifts reasoning scores, saving GPU memory and cash.
🚀 China has released 1,509 large language models as of July 2025, ranking first globally as companies use open-source strategies to undercut Western competitors.
💡 The breakthrough suggests US chip restrictions aren't preventing Chinese AI advancement, potentially forcing Western companies to slash prices or find new competitive advantages.

Pareto Frontier analysis.

The above plot compares how many SWE‑bench bugs each model fixes against how big the model is in billions of parameters. GLM‑4.5 and the lighter GLM‑4.5‑Air both land on the upper left edge, meaning they hit strong bug‑fix accuracy while keeping the parameter count lower than most rivals.
Technical Report, and Hugging Face
📡 Microsoft just turned Edge browser into an AI agent with Copilot Mode.
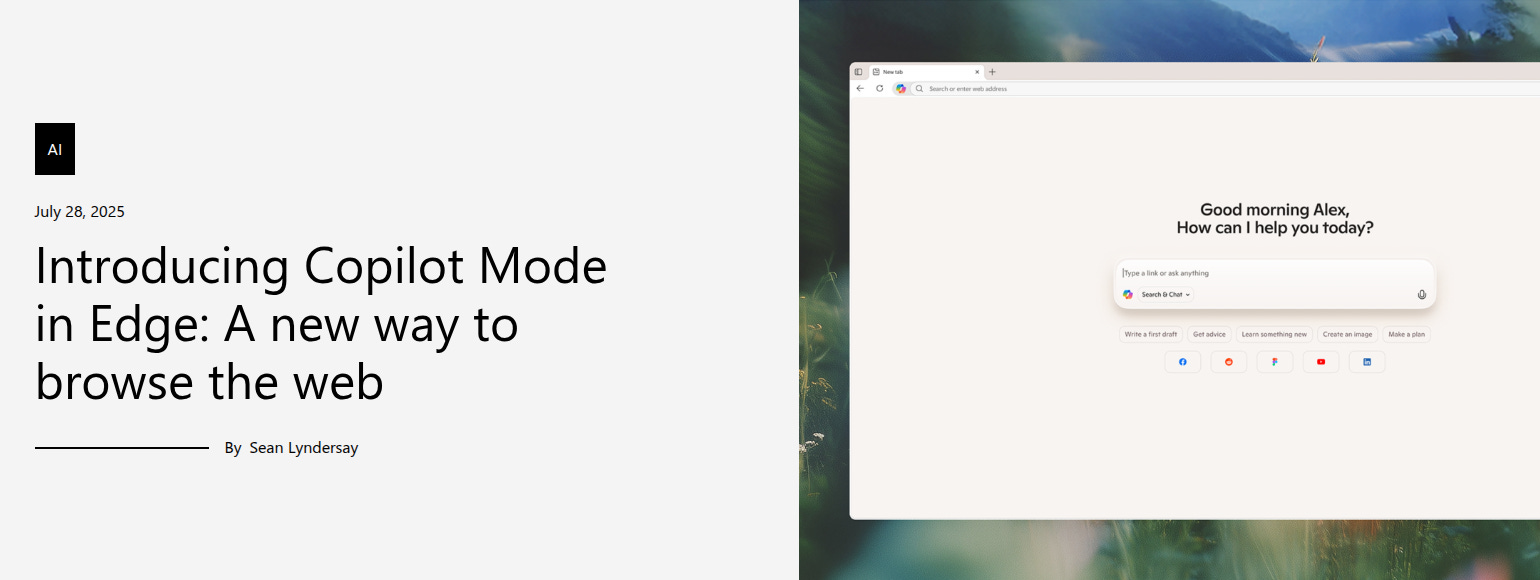
Microsoft introduces Copilot Mode in Edge, which allows users to browse the web while being assisted by AI. The idea is that the AI can become a helper that can understand what the user is researching, predict what they want to do, and then take action on their behalf.
Copilot Mode turns Edge into an AI navigator that reads your tabs, answers queries and carries out routine clicks. Windows and Mac users can enable it free for a limited time.
Copilot sees every open tab, builds context and surfaces comparisons without constant page jumping. Natural voice commands let it open pages, scroll or pick products, trimming keyboard work.
Soon it may book rentals after checking weather, using history and saved logins you approve. Data stays local unless you switch sharing on, matching Microsoft’s standard privacy guardrails.
Once enabled, Edge users will be presented with a new tab page where they can search, chat, and navigate the web with Copilot’s assistance. When visiting a specific web page, they can also turn to Copilot for more help. For example, Microsoft shows how someone might ask the AI companion if a recipe they’re viewing could be made vegan instead, and the Copilot suggests substitutions.
This type of question is something users might ask an AI chatbot today, but this saves the step of having to paste in the content they want to reference.
What stands out a bit more is how Copilot can play the role of a research partner. If you give it access, it can read through all the tabs you have open to figure out what you're working on. That could be really helpful when you're doing things like comparing products or checking prices across different travel sites. AI chatbots already help with these things, but putting this directly into the browser might cut down the back-and-forth and make it smoother.
Later on, Microsoft says Copilot will also suggest where you left off and offer ideas for what to do next in whatever you were researching or building.
They’ve made it clear this is permission-based—Copilot will only look at your browsing if you let it, and there will be visual cues to make that obvious. Still, the idea of flipping on a feature that can see or hear what you're doing while you browse might make some folks uncomfortable.
🛠️ UnitreeRobotics just unveiled R1, it can run, cartwheel and fist-fight – and it costs just $6K

The robot comes equipped with binocular vision backed by LLM image and voice identification capabilities. Its about 4 feet tall and weighs roughly 55 lbs.
4-microphone array, speakers, an 8-core CPU and GPU, 26 joints, and hands. I’ll gladly shell out sub $6K for it to tag along with me while I walk around a tough part of the town.
"Movement first, tasks as well (A diversity of movement is the foundation for completing tasks)".
💰The Competition Around Pricing
Unitree’s this move to bring it down to $6K intensifies pressure on rivals working to drive costs down. Tesla’s still‑experimental Optimus is projected to cost “under US$20,000” only when output reaches one million units annually.
Figure AI’s Figure 02 weighs 70 kg and now shifts sheet metal in BMW’s Spartanburg plant. BMW calls it one of the most advanced humanoids at work, and its informal tag sits near US$50,000.
Apptronik’s Apollo, already hauling parts around Mercedes-Benz sites in Berlin and Hungary, aims for under US$50,000 once the line ramps.
Agility Robotics puts Digit on the market at about US$250,000, though users such as GXO Logistics rent it for roughly US$30 per hour.
UBTech values Walker S, busy lifting components in Chinese electric-vehicle factories, near US$100,000.
HopeJR from Pollen Robotics and Hugging Face is open-source, costs about US$3,000, and still feels experimental.
That makes the R1’s sub-US$6,000 sticker pop; the little acrobat looks able to cover basic walking and gripping for a fraction of the usual fee.
But, you can ask why the same metal acrobat cannot do a simple task as cleaning the kitchen properly
That confusion sits at the core of the mini Moravec paradox in robotics. Moravec's paradox is an observation from the 1980s that high level reasoning, logic, and math demand relatively little computational power in machines, while low level sensorimotor skills such as seeing, grasping, walking, and talking need enormous computation.
As a result, computers can outperform humans in tasks like chess or large scale arithmetic, yet still struggle with everyday physical activities that humans perform effortlessly from infancy.
🧩 The Gap No One Expects: Gymnastics looks tough for humans, yet it is one of the simpler things for robots. Everyday chores look simple for humans, yet they remain a nightmare for machines. That mismatch throws off anyone outside the field because the flashy stunts mask how limited the underlying skill set really is.
👀 Vision Beats Muscles: Picking up a cup or finding your dog in the living room forces the system to fuse camera input, depth data, tactile feedback, and contact physics. Multimodal perception plus manipulation demands far richer models than a timed burst of joint torques.
⚙️ The Simulation Cheat Code: Engineers can train the blind gymnast entirely in simulation, transfer the motion plan to hardware, and watch it work first try. Physics engines run fast, joint limits stay ideal, and there is zero real data to collect. That shortcut does not exist for messy objects that collide, slip, and deform. Rendering photoreal clutter with believable contact forces still lags, so the learning loop stalls.
🐶 Real World Bites Back: Place an unexpected barrier in front of a rehearsed flip and the bot slams into it. Swap the mug for a plastic cup and the gripper drops it. The system has overfit to one reference move or one clean dataset instead of building broad understanding.
🔍 Overall till now, Robots look unstoppable on highlight reels, yet household dexterity is nowhere near solved. Until simulators capture chaotic contact and perception pipelines mature, we will keep cheering for flips while explaining to family why the laundry still waits.
🧑💻 Anthropic will impose weekly caps on Claude Code from August 28

Anthropic unveils new rate limits to curb some extreme usages of Claude Code.
They will block nonstop 24/7 runs and account reselling while leaving 40‑80 hours of Sonnet 4 for most Pro users. Extra usage sits behind normal API prices for Max plans.
Power coders keep Claude Code open all day, sometimes on shared or resold logins, flooding GPUs and causing 7 outages this month. Anthropic admits its compute pool is tight, just like every company training large models.
Anthropic already resets usage every 5 hour window. And now, they are also introducing two new weekly rate limits that reset every seven days; one is an overall usage limit, whereas the other is specific to Anthropic’s most advanced AI model, Claude Opus 4. Anthropic says Max subscribers can purchase additional usage, beyond what the rate limit provides, at standard API rates.
Anthropic says the change hits under 5% of accounts. Cursor and Replit tightened their own $20 plans last month after runaway scripts chewed through compute and triggered surprise bills, hinting at an industry‑wide rethink of flat pricing for heavy coding workloads.
🧑🎓 GPT‑5 Release Imminent, Early Tests Show a Performance Leap on Coding

GPT‑5 is tipped to appear in August 2025, and early testers say it jumps ahead on practical coding work instead of just exam puzzles.
📝 Quick context
Early hands‑on reports describe a model that mixes the familiar GPT language skills with reasoning tricks pulled from OpenAI’s “o” series, letting it scale effort up or down depending on task difficulty.
🧩 How the hybrid setup works: OpenAI is folding the reasoning‑first “o3” path into GPT‑5 instead of shipping it as a separate model. The routing stack can skip heavy compute on simple prompts, then bring in multistep chain‑of‑thought when a problem needs deep analysis. That design mimics Anthropic’s Claude lineup, which lets users pick between quick and thorough modes, as outlined on the Anthropic blog.
🛠️ Real coding gains: Testers report bigger wins on tasks such as refactoring decade‑old repositories, untangling circular dependencies, and inserting new features without breaking flaky tests. GPT‑5 seem to be handling those chores more cleanly than GPT‑4, which often missed context spread across many files.
On synthetic benchmarks, leaks claim 95% accuracy on MMLU and a leap on SWE‑Bench, but the more interesting bit is its steady handling of unknown third‑party libraries, something GPT‑4 struggled with. Medium round‑up collects those numbers.
⚔️ GPT‑5 vs Claude 4: A tester who ran side‑by‑side scripts said GPT‑5 edged out Claude Sonnet 4 on both speed and patch quality, though Anthropic still holds an advantage with the heavier Claude Opus 4. Tom’s Guide notes the early results are single‑user impressions, so large‑scale public trials will matter.
💸 Why the coding market matters: Cursor, one of the most popular coding assistants, is on track for $500M annual recurring revenue while paying Anthropic a sizable share. If GPT‑5 wins those contracts back, the shift could reroute hundreds of millions toward OpenAI, and that is precisely what investors hope to see after Altman’s recent $40B fundraising push detailed by Wired.
🔌 Hardware ripple effect: OpenAI’s coming model rollout ties directly into massive infrastructure bets such as the 4.5 GW Stargate expansion with Oracle, covered by Reuters. More capable models mean higher GPU demand, so Nvidia’s supply chain stands to benefit, a point echoed in Reuters’ coverage of chip allocations for GPT‑5 training.
🚧 Caveats
Some insiders think GPT‑5 could be a router that decides on the fly whether to use a classic LLM or a reasoning agent rather than a single new monolith. Tom’s Guide flagged that possibility. If so, the flashy gains might stem from smarter orchestration instead of a fresh pretraining recipe. That would mean future jumps hinge on RL upgrades rather than raw scale.
📅 Takeaway for engineers
Expect better autocompletion, deeper refactor suggestions, and smarter multi‑file reasoning once GPT‑5 lands in tools like ChatGPT and API‑powered editors. Early numbers look promising, but real adoption will depend on whether the hybrid routing stays consistent under messy enterprise workloads.
That’s a wrap for today, see you all tomorrow.