
🇨🇳 Chinese AI Labs Are Absolutely Dominating Open-source Models
Chinese AI labs are outpacing the West in open-source models, driven by strategy and funding, plus a new method to generate longer videos from ByteDance-Stanford.

Read time: 11 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (30-Aug-2025):
🇨🇳 Chinese AI labs are absolutely dominating open-source AI models, far exceeding Western models.
📡 Chinese open-weight models: Analysis how Economic and Strategic direction helped China win over the West
🛠️ ByteDance and Stanford found a new way to generate long video, instead of those short 6-10 seconds shots
(Today’s Sponsor) Practical AI Summit 2025, that will take place on Oct 2-3 on Zoom Conference.
🇨🇳 Chinese AI labs are absolutely dominating open-source AI models, far exceeding Western ones

The open-weight scoreboard says China, full stop
Across 2025, Chinese labs shipped the strongest open‑weight LLMs, and they now sit at the top of every public leaderboards and commercial tooling.
China’s open source AI push is turning into a standards fight, with DeepSeek R1 and Alibaba Qwen grabbing global users while U.S. teams answer with gpt-oss.
Washington is already worried that if Chinese open models become the default standard then Beijing could turn that reach into leverage during trade standoffs. Vendors expect to make money later by bundling services on top of the free core just as Android pulled makers into its ecosystem and then tied in search and app stores.
History says standards often come from what is easiest to get and bend, not the absolute best model on paper, which is why availability and flexibility matter.
📅 One month, 8 heavyweight releases
Here is the clean timeline, each link goes to a primary source or model card.
Jul 11: Moonshot Kimi-K2-Instruct, 1T total, 32B active, released as open weights with model card and code on Hugging Face, context 128K (model card, tech blog, Reuters coverage).
Jul 21: Qwen3-235B-A22B-Instruct-2507, 235B total, 22B active, Apache-2.0 (Hugging Face, NYU Shanghai note, dated Jul 22).
Jul 22: Qwen3-Coder-480B-A35B-Instruct, 480B total MoE coding model, Apache-2.0 (Qwen blog, Hugging Face).
Jul 25: Qwen3-235B-A22B-Thinking-2507, dedicated reasoning variant, 256K native context (Hugging Face, Qwen timeline).
Jul 28: Zhipu/Z.ai GLM-4.5 355B total, 32B active, and GLM-4.5 Air 106B total, 12B active, MIT license, targeted at agent use (Z.ai blog, GLM-4.5 GitHub, MIT, GLM-4.5 Air HF, Reuters).
Jul 30: Qwen3-30B-A3B-Instruct-2507, 30.5B total, 3.3B active, 256K native context (Hugging Face, Qwen timeline).
Jul 31: Qwen3-30B-A3B-Thinking-2507, reasoning-first 30B MoE, 256K context (Hugging Face, Qwen timeline).
Jul 31: Qwen3-Coder-30B-A3B-Instruct, streamlined coding model at 30B scale, 256K context (Hugging Face).
For context, DeepSeek’s most recent open-weight refresh was DeepSeek-R1-0528 in late May, nothing new in July (HF model card).
🧱 What happened to Western open weights
Mistral pushed its big open MoEs to legacy status and pivoted to small Apache-2 models for open weights. Mixtral 8x7B and 8x22B list deprecation in 2025-03-30 with “use mistral-small-latest” as the path. That is a great experience story for self-hosting, but it also explains why you do not see a Western open MoE bullying the top of Arena anymore.
Llama has a massive ecosystem and neat research tricks, but the public head-to-head placement is rough this month, Maverick at 64 and Scout at 67. If you care about blind human preference, the Western flagship open weights are not scoring where decisions get made. That is the uncomfortable truth.
Gemma is the most practical Western option for single-GPU or edge, yet the current Arena placement is rank 52 for Gemma-3-27B-IT, which is competent, but not a threat to the Chinese top entries.
🧠 What to do with this reality
If you insist on open weights and you want the strongest quality right now, pick Qwen3-235B/30B, Kimi-K2, or GLM-4.5 / 4.5 Air. If you need permissive licensing with easy self-hosting on modest hardware, Mistral’s small Apache-2 line and Gemma-3 are fine choices, just do not expect them to win blind matchups against the Chinese releases. The latest Arena data makes that tradeoff crystal clear.
🧾 Receipts, not vibes
Arena shows Qwen3-235B-A22B-Instruct-2507, Kimi-K2, and GLM-4.5 at the top end as of Aug 28. Llama 4 Maverick 64, Llama 4 Scout 67, Gemma-3-27B-IT 52, Mistral-small-2506 42. That is your month-end snapshot. (See the board)
Mistral’s own docs show the Mixtral line as legacy with retirement dates in early 2025, reinforcing the strategic pivot away from big open MoEs. (Docs)
✅ Bottom line
Chinese open weights are winning on real human preference tests right now, by margin and by consistency, and the Western open-weight families are not close on those same boards. If your goal is best available open weight, you are choosing Chinese.
(Today’s Sponsor) Practical AI Summit 2025 will take place on Oct 2-3 on Zoom Conference

Over 20 practitioners will share deployed systems across energy, finance, insurance, investing, telemedicine, and operations. Sessions will cover AI agents, grid optimization, fraud detection, claims automation, governance, team structure, and no-code or low-code workflows. Confirmed speakers include experts from Intuit, Novartis, Amazon, Stanford, and industry startups. Expect interactive Q&A, networking, and an attendee certificate.
Regular price $199, early bird $99 until Aug 31, group 4 get 1 free. Each registrant will receive a free copy of the book "Principles of Building AI Agents" by Sam Bhagwat.
📡 Chinese open-weight models: Analysis how Economic and Strategic direction helped China win over the West

🇺🇸 Why U.S. policy and litigation push labs away from open weights
Starting in 2023, the Biden Executive Order 14110 told Commerce to design reporting for big training runs, and to require U.S. cloud providers to flag foreign customers who train large models. The follow-on proposed rule sets that reporting up for IaaS clouds. Whatever your view, this adds compliance work and public signals that make frontier open releases riskier.
Export-control updates in Oct 2022 and Oct 2023 tightened flows of advanced AI chips and tools, then kept closing loopholes through 2024–2025. These rules do not stop U.S. firms from training at home, they do raise cross-border compliance and partner risk, which in practice rewards controlled API access over broad open-weight distribution.
At the same time, U.S. courts moved fast on copyright and DMCA claims against model training, including orders to preserve vast amounts of AI chat logs and mixed early rulings on DMCA CMI removal. The legal uncertainty and discovery burden are real costs, and they skew decision making toward closed releases and narrower data disclosures.
There is also a licensing chill. Meta’s Llama license remains “source-available” with a 700M MAU (monthly average users) clause and is not OSI-open, which makes it harder for other Western labs to build universally on top without counsel sign-off. That contrasts with Apache-2.0 and MIT that Chinese labs use.
** Source-available means you can see the code or model weights, but you don’t get the full legal freedoms of open-source.** The source is viewable, but the license imposes restrictions—maybe on how you redistribute it, how you use it commercially, or how you share derivatives. It falls short of the OSI’s Open Source Definition, which requires free redistribution, permission for derivative works, no user or field-of-use discrimination, and more.
In practice, this often means you can fork a model for research or hobby use, but the license might block you from using it in products, training other models, or distributing modifications. That’s exactly why "source‑available" lacks the full freedoms that Apache‑2 and MIT (which are open source) provide
Finally, the U.S. Electricity grid is tight exactly where AI wants to build. PJM capacity prices spiked on data center growth, connection queues and local power constraints raise cost and time to train at scale, and UK–EU power prices are even higher. These are macro headwinds for cheap frontier-scale open training in the West.
🇪🇺 Why EU rules raise disclosure and governance overhead
The EU AI Act now squarely covers General-Purpose AI. Draft guidelines say a model is GPAI if training compute exceeds 10^23 FLOPs, with a separate 10^25 FLOPs bar for “systemic risk” duties. Providers must keep extensive technical documentation and, crucially, publish a “sufficiently detailed” summary of training content using the Commission’s template. For EU-based open-weight releases at high scale, this adds specific disclosure work that companies worry could connect to copyright exposure.
The Commission also shipped a GPAI Code of Practice to operationalize Article 53 transparency and copyright duties. Voluntary or not, serious EU actors will follow it, which again makes permissive, no-strings open releases harder to justify for the very largest EU models.
Power and grid pressure amplify this. Europe’s data-center growth faces high electricity prices and long grid lead times, with U.K. developers even exploring direct gas pipeline hookups to keep projects alive. Higher all-in energy and interconnect cost raises the breakeven for training big open checkpoints.
🇨🇳 Why China’s setup makes open weights easier to ship
China spent years building a national compute fabric. The “Eastern Data, Western Computing” initiative and the National Integrated Computing Network pooled public and private data centers around 8 national hubs, with reported direct public investment of ¥43.5B (about $6.1B) and hundreds of billions more from local projects. Officials now claim 620,000 PFlops of “intelligent computing” and say ~60% of new capacity concentrates in those hubs. Even if some numbers are optimistic, the direction is clear, China socialized a big chunk of the fixed costs.
There is even a plan to network and resell surplus compute after overbuilding left many sites at low use, which means training teams can buy cheap cycles across provinces. Align that with new pushes to triple domestic AI-chip output and you get a pipeline that is cost-competitive for giant MoE training.
China’s interim measures regulate generative AI only when it's offered as a service to the public within China—like a chatbot anyone can use, or an API available to Chinese users. That means if you’re developing a model for internal use, research, or for non-public teams, those rules do not apply.
In the draft version, these rules were broader—they could have applied to any AI development. But regulators narrowed their reach in the final version to only public-facing services.
So the logic is this: if you’re building an open-weight model in a lab and not releasing it publicly, you are outside the stricter part of the law. That gives Chinese developers the room to train and share weights without triggering China's AI service regulations.
In short, public-facing services must comply and undergo filings, but private research does not—that carve-out frees labs to experiment and publish.
🧾 License choices accelerate adoption
Alibaba’s Qwen ships under Apache-2.0, and Zhipu’s GLM-4.5 ships under MIT. Teams can fine-tune, redistribute, and embed without the Llama-style carve-outs, which compounds the distribution advantage for Chinese open weights. Kimi-K2’s license is a modified MIT that is not OSI-compliant, but it still reads more permissive than most Western “source-available” terms.
⚡ Economics, energy, and time-to-market
Training economics in the West face 2 extra taxes right now, legal process and power. U.S. litigation created new preservation and e-discovery burdens, plus real DMCA risk, and that lands exactly on the open-release decision. EU Article 53 adds a binding training-data summary that many lawyers will tie to IP risk. Add higher power prices and slower grid hookups, and the cheapest path for Western labs is a strong hosted model rather than a frontier open weight.
China’s counter is scale and policy coordination. National and provincial money lowered fixed costs for compute, regulators limited obligations mainly to public-facing services, and vendors leaned into Apache-2.0/MIT for open releases. That mix explains why you see 1T-total and 355B-total MoE checkpoints with permissive licenses coming from Beijing and Shanghai first.
🧠 What this explains about model outcomes
Chinese labs trained massive MoE models, published weights under business-friendly terms, and showed up at the very top of human-preference boards. U.S. and EU champions still build great models, but the Western policy stack plus litigation risk makes fully open frontier releases an outlier, so the best Western checkpoints tend to stay behind APIs or under restrictive licenses. That is the simplest, data-backed reason the open-weight crown shifted.
✅ Bottom line
Policy and power shaped the market. U.S. reporting rules, export-control friction, and active copyright suits, plus EU Article 53 disclosures and high electricity costs, all push Western firms toward closed or semi-open releases. China, meanwhile, built a national compute rail, kept many obligations focused on public services, and chose permissive licenses, so its labs could ship big, open, MoE checkpoints that win live head-to-heads.
🛠️ ByteDance and Stanford found a new way to generate long video, instead of those short 6-10 seconds shots

💡 Absolutely great proposal by this ByteDance and Stanford paper for long video generation. "Mixture of Contexts for Long Video Generation"
7x fewer FLOPs, 2.2x faster, 85% attention pruned on 180K token scenes.
The core problem is memory, attention cost explodes with length and models drift, forget, and change identities. Mixture of Contexts solves the "attention related compute" problem by treating long video generation as a retrieval problem instead of brute force attention.
Mixture of Contexts slices tokens into content aligned chunks, frames, shots, captions, then each query picks top relevant chunks only. Relevance uses a simple average of each chunk’s features compared to the query, which trains itself into a strong routing signal.
2 anchors are forced, attend to all text to hold the prompt, attend to the local shot to keep fine detail. A causal mask blocks future links, stopping feedback loops that would trap attention between later shots.
Only the selected chunks go through fast variable length Flash Attention, so compute scales with retrieved context, not the full history. Short clips match dense quality, long scenes gain smoother motion and better identity while runtime drops.
So the key technique is, this learns where to look, giving minute scale memory without changing the diffusion backbone.
What Mixture of Contexts really is ?

The basic issue is that attention normally compares every token with every other token, which explodes in cost as a video gets longer.
A 1-minute video at common resolution can reach almost 200K tokens, and dense attention would mean trillions of operations. On top of that, most of those comparisons are redundant, because nearby frames often repeat the same information.
Mixture of Contexts solves this by treating long video generation as a retrieval problem instead of brute force attention. The video is broken into meaningful chunks like frames, shots, and caption segments. For each query token, instead of looking at the entire history, it only selects the top few chunks that are most relevant based on a similarity score. On top of that, two anchor links are always kept: one to the text prompt, which keeps the video aligned with the user input, and one to the local shot, which keeps fine details intact.
This routing step, called Mixture of Contexts, is adaptive and learned during training. It means the model automatically learns which past events matter, routes its attention there, and ignores the rest. That way, computation scales almost linearly instead of quadratically, while the video keeps global consistency over long stretches
Overview of our Adaptive Mixture of Contexts.
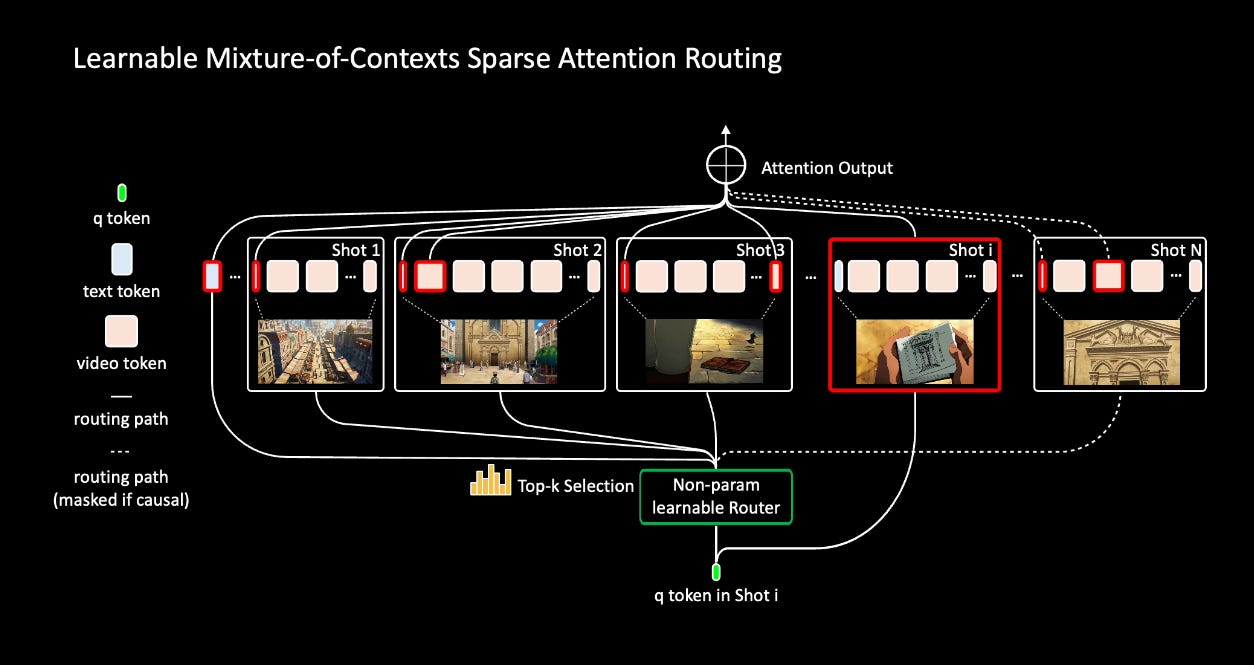
When a query token (the green dot in the figure) wants context, it does not look at all tokens. Instead, it computes similarity with the representative vector of each chunk, and then only picks the top few chunks that look most relevant. This is the “top-k selection” step shown in the diagram.
Some links are always forced: the model must attend to the text tokens (the prompt) and the local shot tokens. These are called mandatory anchors and make sure the video stays faithful to the input description and to fine local details.
Finally, only the selected chunks are passed into Flash Attention. All the other tokens are skipped. This means the model uses far less compute and memory, but still has access to the important past events it needs.
That’s a wrap for today, see you all tomorrow.
What are the practical implications for app developers today of choosing the #1 model vs, say, the #6 model? I imagine that they'd keep an eye on the leaderboard but not jump from money to model? Further, I assume that at the margin, app engineering may count for as much as model scores for user experience.
Thoughts?