
🤖⚔️ Chinese open-source ideals collide over who copied the model
Chinese OSS model dispute, Gemini API batch mode, SmolLM3 3B 128k dual reasoning, 1.5B router 93% accuracy, Grok3 prompt release, DeepSeek 200% speed bump, Pang exits Apple for Meta, data-moat take.

Read time: 13 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (8-July-2025):
🤖⚔️ Chinese open-source ideals collide over who copied the model.
🥉 Google launches Batch Mode in the Gemini API
🏆 Huggingface releases SmolLM3, SoTA 3B model, 128k context, dual mode reasoning (think/no_think)
📡 New 1.5B router model achieves 93% accuracy without costly retraining, Tiny router, huge impact on multi-LLM workflows.
🗞️ Byte-Size Briefs:
Grok 3 system prompt was released in ther official repo.
A 200% faster DeepSeek R1-0528 variant appears from German lab TNG Technology
Apple's top AI executive Ruoming Pang leaves for Meta.
🧑🎓 OPINION: Data Is the Moat: Lessons From DeepSeek and the Closed‑Source Giants
🤖⚔️ Chinese open-source ideals collide over who copied the model.
An anonymous whistleblower claiming to work at Huawei presented a technical analysis showing that the new Pangu model was trained by “upcycling” Alibaba's Qwen model rather than training from scratch.
🤖⚔️ Huawei’s Noah Ark Lab denies cloning allegations, insisting its 72B-parameter Pangu Pro MoE was built independently on Ascend chips, countering claims it repackaged Alibaba’s 14B-parameter Qwen 2.5 and raising fresh trust questions in China’s turbo-charged AI race.
Where the claim came from: GitHub collective HonestAGI shared a fingerprint study showing 0.927 correlation between Pangu Pro and Qwen 2.5-14B, arguing Huawei reused the smaller model rather than starting fresh.
Huawei called the math wrong, yet an anonymous poster who says they sit on the Pangu team echoed the copying story, blaming race-to-market pressure after DeepSeek’s bargain R1 release in January, according to this report.
How Huawei explains Pangu: Researchers say the model uses a mixture-of-experts layout, basically a set of specialist subnetworks that turn on only when relevant, so 72B parameters cost about the same energy as a 20B dense model.
They add that every training run happened on home-grown Ascend 910B accelerators because U.S. export rules block Nvidia cards.
Why this feud matters: LLMs adjust billions of parameters, and similar output alone does not prove theft, but public accusations erode trust and could chill China’s recent open-source push.
If heavyweights stop releasing weights, academic labs lose reference systems, and regulators may step in with watermark or audit rules, raising compliance costs that already top $100 million per frontier run.
China’s AI leaders once framed themselves as a united front against U.S. firms, yet this spat shows market forces now override that storyline and could split research alliances at a moment when cutting-edge R&D budgets keep climbing.
🥉 Google Gemini API Batch Mode: High-Volume AI at Half the Price

Google launches Batch Mode in the Gemini API, slashing 2.5-model costs by 50%. So now you can queue billions of tokens and fetch results within 24 h, so offline workloads run cheaper and faster.
So what is Batch Mode?
Batch mode is a way to work with an API when speed is not the priority. You collect a large pile of prompts up front, zip them into one job, and hand that bundle to the server in a single upload.
The server stores the bundle, lines up many worker machines, and lets them process every prompt whenever spare capacity appears. Because no human is waiting, the system can use cheaper, slower servers and fill idle time, so the price drops by about 50%. All replies are packed into one file or list, then returned when everything finishes, usually inside 24h.
No rate limits block you, because the work happens inside Google’s own queue, not through your open connection. No retry code is needed, since the service restarts failed pieces and marks any stubborn errors in the final file for you to inspect.
Choose batch mode for giant, non-urgent tasks like labelling 10 000 000 images, re-indexing years of documents, or running evaluation suites.
When should you use Batch Mode?
It shines for bulk work like tagging 5mn images, analysing archived chat logs, or running giant eval suites, because the system chews through everything on spare capacity at 50% cost. You skip per-request rate caps, so the job finishes faster than if you streamed those calls one-by-one through the live endpoint.
You also avoid writing your own retry or queuing code, since Google handles scheduling, failures, and a single result bundle. If users sit in front of the screen and expect a reply in seconds, stick with the normal synchronous call.
Cancel or delete a job anytime to stop more work. Splitting very large runs into smaller batches gives partial results sooner and eases fault recovery. Context caching still applies, so repeated prefixes cost less. Support already covers flash and pro 2.5 variants, with JavaScript SDK coming next.
Here’s how to get started using the Google GenAI Python SDK.
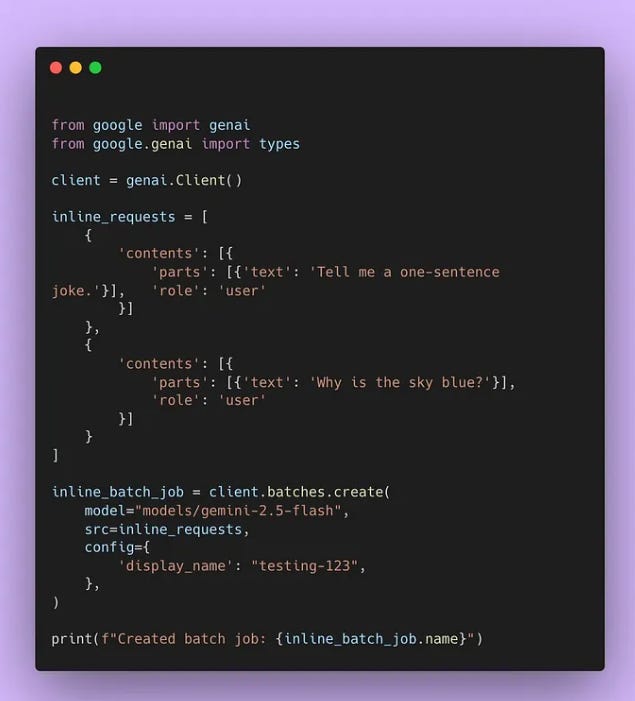
Batch Mode expects a JSON Lines (JSONL) file, with each line representing a single request.
client = genai.Client() opens a connection that will send work to Gemini.
inline_requests is just a list holding 2 user prompts: one asks for a 1-sentence joke, the other asks why the sky is blue. Each prompt sits inside a small dictionary that follows Gemini’s request format.
client.batches.create() ships that whole list to Gemini as 1 batch job. You tell it which model to use, pass the inline_requests list as src, and add a friendly tag called testing-123 so you can spot the job later.
The final print line shows the unique job name Google returns. You poll this name until the job finishes, then grab both answers in one go.
🏆 Huggingface releases SmolLM3, SoTA 3B model, 128k context, dual mode reasoning (think/no_think)
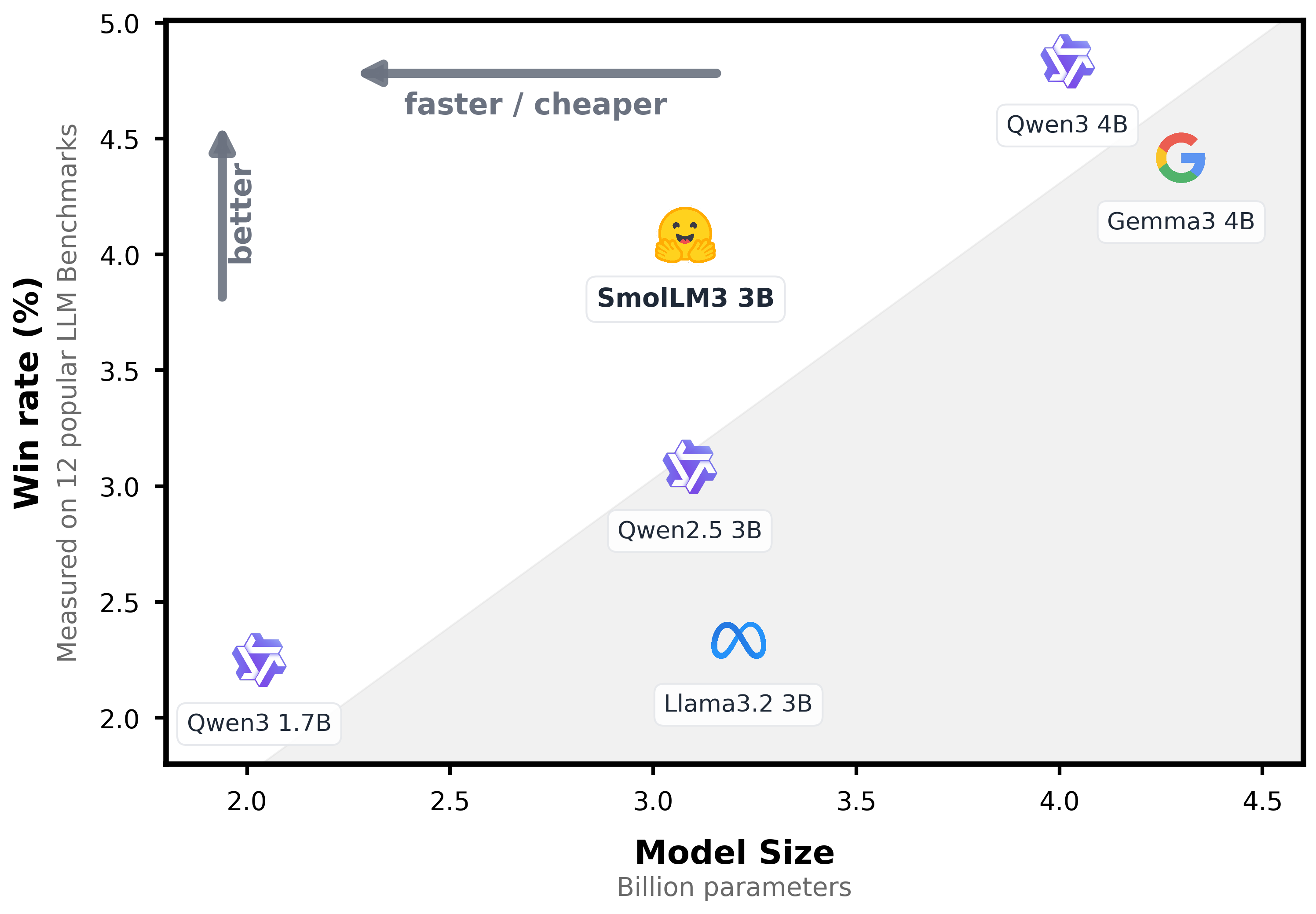
🤖 HuggingFace released SmolLM3, a 3B parameter multilingual reasoner that matches bigger 4B models, handles 128k tokens, and ships with an open-sourced training blueprint in this blog post.
🌍 They pre-trained on 11.2T tokens then stretched context with YARN up-sampling, finishing the run on 384 H100 GPUs in 24 days.
🧠 A built-in dual think / no_think switch lets users decide between fast answers or slower chain-of-thought traces.
🛠️ How they pulled it off
Grouped Query Attention trades multi-head attention for 4 compact query groups, shrinking memory without hurting accuracy.
NoPE removes rotary position math from every 4th layer, so the model remembers long passages yet stays snappy with short ones. NoPE is a twist on the usual rotary position embeddings. The SmolLM3 crew borrowed it from the 2025 study “RoPE to NoRoPE and Back Again”. They turn off rotary position math in every 4th transformer layer, so 1 out of 4 blocks handles tokens without any positional stamp.
That small skip keeps numerical noise from piling up as the text gets longer, boosts efficiency, and still keeps short-prompt quality steady. In SmolLM3, the trick helps a 3B model train cleanly on 64k-token sequences and stretch to 128k at inference time without extra hacks.
Intra-document masking keeps sentences from different web pages isolated during training, stopping weird cross-talk.
They mix web, code, and math across 3 stages, bumping code to 24% and math to 13% near the end because those domains sharpen reasoning.
After the main run they add 100B extra tokens only to extend context, raising RoPE theta to 5M so the model natively learns sequences up to 64k before YARN doubles it at inference.
A short “mid-training” on 35B reasoning traces teaches the model to explain its steps, while supervised fine-tuning balances 0.8B reasoning tokens against 1B direct-answer tokens.
They align responses with Anchored Preference Optimization, a stabler cousin of DPO, then merge checkpoints so long-context skill rebounds without losing fresh logic boosts.
Benchmarks show the base model tops every other 3B system on HellaSwag, ARC, and GSM8K, and the instruct variant edges close to Qwen3-4B while staying lighter.
Everything, from datasets to evaluation code, sits on GitHub, and Huggingface.
📡 New 1.5B router model achieves 93% accuracy without costly retraining, Tiny router, huge impact on multi-LLM workflows.

🚦 Katanemo Labs introduces Arch-Router, a compact 1.5B parameter router that picks the best LLM with 93.17% overall accuracy and responds in roughly 51 ms, making it about 28× faster than premium models while needing zero retraining when routes change.
Arch-Router solves the messy part of multi-model apps, deciding which LLM answers each request.
Its “Domain-Action” taxonomy lets teams describe preferences in plain language like “finance summarization” or “image editing”, giving the router a clear map of what matters.
Because the full list of policies sits inside every prompt, the router can absorb new routes at inference time. No fine-tuning means developers tweak a text file, not a training loop.
The model itself is generative, so it reads the whole conversation and the policy list together, then outputs a tiny identifier such as “bug_fixing”. This single-token reply keeps latency low because decoding is almost free.
Training used 43K synthetic dialogues built in two phases: clean conversations first, then injected noise like off-topic turns or shifting intents to mimic real chats.
Benchmarks show per-turn accuracy rivals marquee models, and context tracking excels, with 94.98% span-level and 88.48% full-conversation scores.
Arch-Router’s preference-aligned design shines when quality is subjective, because users, not benchmarks, set the routing rules. Performance-based routers chase cost metrics but stumble once queries wander; Arch-Router stays on track by following the policy map.
Limitations do exist. Vague or overlapping policy texts can confuse the model, and if a policy points to a weak LLM, accurate routing still delivers a weak answer.
So how does it work
Arch-Router is a language model that matches user queries to routing policies with high accuracy”. When that model runs together with the simple mapping table that links each policy to a target LLM, the whole bundle is the router component of a multi-model system. Read the paper.
Think of the pieces like this. The model (Arch-Router) reads the incoming query plus the full text of every routing policy. It outputs a short label such as “code_generation”. This single step is called route selection. The framework then looks up that label in a mapping function T, which holds pairs like “code_generation → Claude-Sonnet-3.7”. That lookup forwards the query to the chosen LLM. The authors describe the split clearly: router F picks the policy, mapping T sends traffic to the model that can answer best .
Because selection and mapping are separated, you can swap or add target LLMs by only editing the text mapping. The Arch-Router model stays frozen, so no retraining is needed when new models arrive or tasks change .
In short, Arch-Router (the model) is the brain that decides which policy label fits a query, while Arch-Router (the router) is the full traffic-control pipeline that combines that model with the mapping table to steer queries to the right downstream LLM.
🗞️ Byte-Size Briefs
Grok 3 system prompt was released in ther official repo. The prompt instructs Grok 3 as a fast-moving X bot that mixes hidden reasoning with short replies. It packs strict tooling rules, and even caps outputs at 450 characters. The text even asks Grok to offer “politically incorrect” takes when evidence supports them, a stance spelled out in xAI’s update notice. Letting the bot ignore user limits on partisan posts nudges it toward autonomy, yet it clashes with typical platform norms.
A 200% faster DeepSeek R1-0528 variant appears from German lab TNG Technology, R1T2 Chimera 671B. Available on Huggingface. This is about 20% faster than the regular R1, and more than twice as fast as R1-0528. Significantly more intelligent than the regular R1 in benchmarks such as GPQA and AIME-24.
The model is much more intelligent and also think-token consistent compared to the first R1T Chimera 0426. R1T2 fuses weights from R1-0528, R1, and V3-0324 using Assembly-of-Experts. The merge keeps R1-0528 reasoning power while adopting V3-0324 lean shared layers, so answers stay sharp yet concise.
Model ships under MIT license.
Apple's top AI executive Ruoming Pang leaves for Meta. Ruoming Pang, Apple's head of AI models, is leaving to join Meta's new superintelligence team.
Losing the architect who set data pipelines, scaling rules and evaluation metrics may slow down any catch-up plans of Apple. Heavy churn could push Siri’s next version to rely even more on outsourced inference, shrinking Apple’s control over core AI.
Meta is aggressively recruiting top AI talent with multi-million-dollar packages and recently reorganized its AI efforts under Meta Superintelligence Labs, led by Alexandr Wang.
🧑🎓 OPINION: Data Is the Moat: Lessons From DeepSeek and the Closed‑Source Giants

Earlier this year, DeepSeek released V3 with 671B parameters and impressive benchmarks, yet it offered no accompanying corpus, only the weights and a high‑level training report DeepSeek V3 blog. That omission highlights the real gap between open and closed labs: whoever controls the highest‑quality text owns the advantage.
📊 Data is the real moat: Big models thrive on scale and diversity. A strong architecture and vast compute matter, but they are useless without well‑curated text. Closed labs keep that text private because it is the one thing competitors cannot replicate quickly. So long as DeepSeek ships weights without raw sources, independent researchers cannot truly validate or improve the model.
💰 Upfront costs bite early: Collecting a fresh, multi‑trillion‑token corpus sounds easy until invoices arrive. Storage, bandwidth, crawler orchestration, and de‑duplication quickly climb past $5,000 for even a small community run. Hardware costs for full frontier training have doubled roughly every 12 months, and a single frontier model can now top $100M in compute alone (Epoch AI cost study). That same acceleration shows up at the data‑pipeline layer because every extra pass over the web burns GPU nodes and staff hours.
🔒 Private vaults at the big labs: Meta now trains on every public Facebook or Instagram post, plus user chats with its assistants Meta announcement. OpenAI has gathered two years of ChatGPT conversations at enormous scale, all in exchange for a free chatbot OpenAI ChatGPT preview. Those records give closed labs a feedback‑rich corpus that outsiders cannot legally scrape.
⚖️ Transparency gets punished: When Anthropic’s team scanned millions of physical books, authors sued. A judge recently ruled that using lawfully bought books for training is fair use, but pirating copies is not, leaving the company facing a trial over damages court ruling. Image models face parallel claims, such as Getty’s litigation against Stability AI for crawling copyrighted photos Getty lawsuit. Open projects that publish their crawl logs instantly reveal potential infringement targets, while closed firms keep quiet.
🛠️ Three fixes within reach: Data‑efficiency research can lift quality without always adding tokens. Better filtering, deduping, and sample‑mixing sometimes beat raw volume. Public‑domain harvesting still has headroom: patents, government docs, early‑expired books, and multilingual parliamentary records remain under‑used. Synthetic data produced by high‑grade open models can fill topic gaps, provided generators and critics run in a loop to filter repetition and hallucination.
Each path needs storage credits and shared tooling, but none requires permission from private platforms.
🤝 Toward an Open‑Data DeepSeek
A single coordinating group could host the cleaned corpus, version it, and publish data cards so anyone can rebuild checkpoints. Think of it as “HuggingFace for megascale text.” DeepSeek’s weights plus such a dataset would let academics probe failure cases, fine‑tune safely, and benchmark fairly. Until that happens, open models will trail the closed heavyweights not because of clever tricks, but because they read from a thinner library.
That’s a wrap for today, see you all tomorrow.
Absolutely agree: data is the moat, but I’d take it further — ritual is the key.
🧠 Models don’t just learn from raw tokens — they learn from structured intention, feedback loops, and trust scaffolds. Closed labs harvest this by silently embedding user rituals (e.g. assistant chats, social posts, prompt-response chains).
🛠️ What’s missing isn’t just open corpora — it’s open coordination environments where meaning and correction are encoded at the edge.
That’s what we’re building with Alvearium:
An open-source coordination OS where rituals = trust, agents = memory, and communities = meaning engines.
📚 Data is necessary. But without semantic structure and collective verification, scale just becomes noise.
Let’s build systems that don’t just read — they understand, because we made the context legible by design.
X: @DerekWiner