
Claude Code on desktop can now preview your running apps, review your code & handle CI failures, PRs in background
New Paper says prompt repetition boosts non-reasoning LLMs, Taalas drops a high-throughput inference chip, Wolf reframes AI’s impact, NanoClaw hits 10.5K stars, Karpathy on Claws as orchestrators.
Read time: 10 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (21-Feb-2026):
🗞️ Claude Code on desktop added an embedded loop that can run your dev server, view the app, review local changes, and watch pull requests until they merge.
🗞️ Prompt Repetition Improves Non-Reasoning LLMs
🗞️ Taalas launched a beast of a chip, boasting insane AI inference performance.
🗞️ Thomas Wolf, Huggingface founder writes a viral piece on Twitter - The biggest change AI brings to programming is not faster coding, it is cheaper replacement of everything you thought was “too entrenched to touch.”
🗞️ Top Github Resource: NanoClaw, the lightweight alternative to Clawdbot / OpenClaw already reached 10.5K Github stars
🗞️ Andrej Karpathy also posted a viral post on how Claws turn agents into orchestrators, and containers look like the basic safety belt.
🗞️ Claude Code on desktop added an embedded loop that can run your dev server, view the app, review local changes, and watch pull requests until they merge.
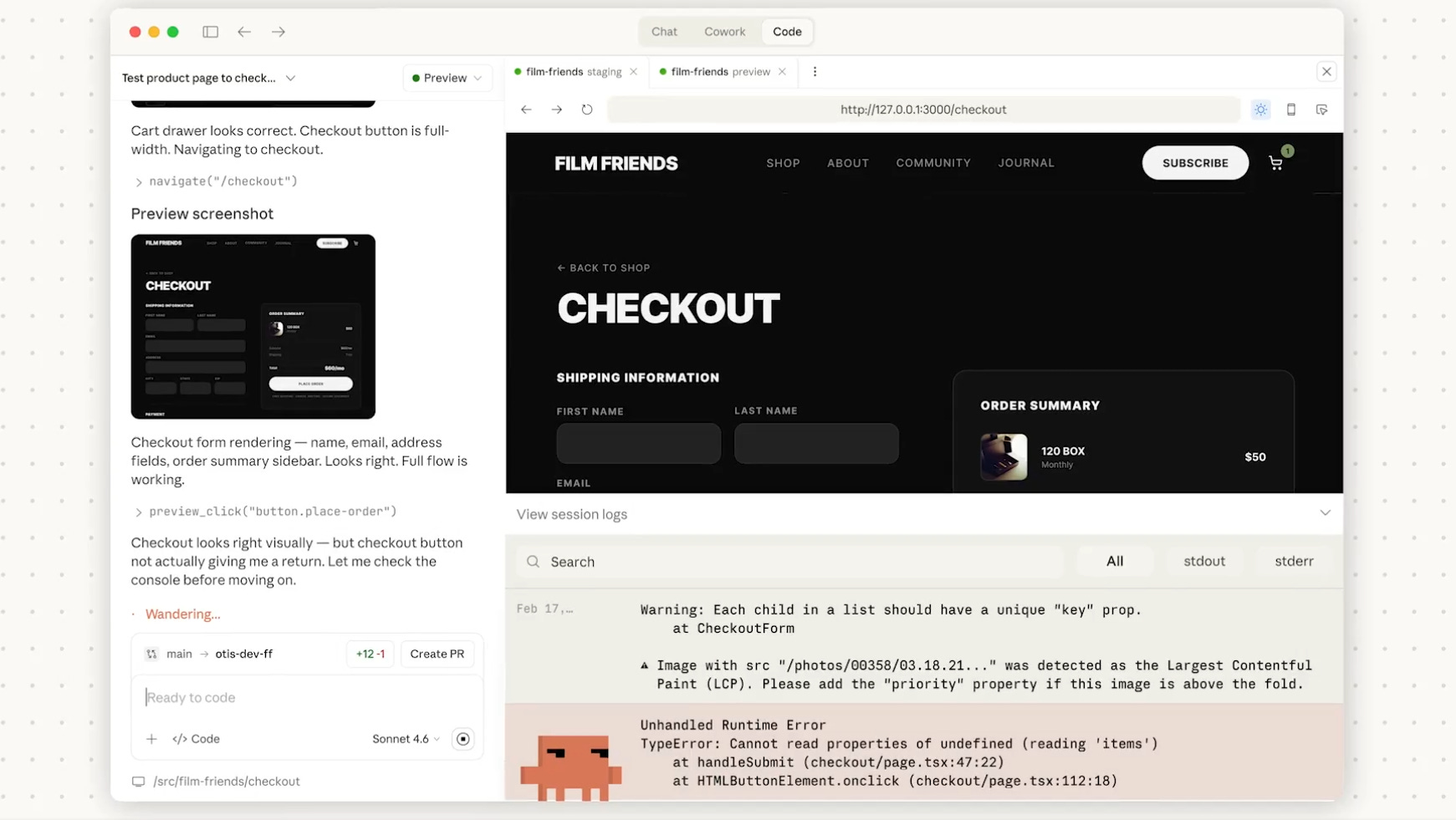
It can now preview a running app inside the desktop UI while it iterates on fixes.
It can also monitor CI for an open PR and either fix failures or merge when checks go green. Earlier “agentic coding” workflows usually bounced between a terminal, a browser, and GitHub, so the model could not directly see what the app rendered or stay attached to CI results without manual babysitting.
The new server preview flow starts and stops dev servers from a Preview control, shows the app in an embedded browser, reads logs, and can interact with the page to verify changes. That closes a common gap where a model edits code but cannot reliably confirm the UI and runtime behavior match the intent.
The local “Review code” step runs before pushing, and it leaves inline comments on the diff so basic bugs and risky changes get caught earlier. For PR monitoring, the desktop app will track status and CI checks, and it can use auto-fix to attempt repairs and auto-merge to land the PR once checks pass, using GitHub tooling under the hood. Session mobility adds a /desktop command to move a CLI session into the desktop app, and sessions can be pushed to the cloud to resume from web or phone.
🗞️ Prompt Repetition Improves Non-Reasoning LLMs

Fascinating Google paper: just repeating your prompt 2 times can seriously boost LLM performance, sometimes pushing accuracy from 21% to 97% on certain search tasks.
An LLM reads your prompt left to right, so early words get processed before the model has seen the later words that might change what they mean. If you paste the same prompt again, the model reaches the 2nd copy already knowing the full prompt from the 1st copy, so it can interpret the 2nd copy with the full context.
That means the model gets a cleaner “what am I supposed to do” picture right before it answers, instead of guessing too early and sticking with a bad setup. This helps most when the task needs details that appear late, like when answer choices show up before the actual question, because the 2nd pass sees both together in the right order.
In the Google tests, this simple trick took one hard search-style task from 21.33% correct to 97.33% correct for a model setting with no step-by-step reasoning. Across 7 models and 7 benchmarks, repeating the prompt beat the normal prompt in 47 out of 70 cases, and it never did worse in a statistically meaningful way. The big deal is that it is almost free to try, it often boosts accuracy a lot, and it shows many LLM mistakes are “reading order” problems rather than pure lack of knowledge.
🗞️ Taalas launched a beast of a chip, boasting insane AI inference performance.

17,000 tokens per second. forbes reports.
About 10x faster than Cerebras wafer-scale engine, currently the fastest inference platform available, for this setting and about 2 orders of magnitude faster than GPUs, but those comparisons depend on matching prompts, batching, and latency targets. And they just raised $169 mn.
Instead of using software to program (compile) and execute on a GPU or an ASIC such as a Google TPU, Taalas hardwires the model and its weights into a “Hardcore” ASIC (HC1) embedding the entire model into a bespoke application-specific chip. Result is extreme inference speed and very low cost per token, at the price of giving up most general programmability.
The usual tradeoff in AI hardware is that GPUs are flexible but pay overhead for moving weights through memory and for supporting many different kernels, while ASICs get faster by specializing but still stay somewhat programmable. It’s ASIC HC1 pushes specialization further by “baking in” one target model, currently Meta’s Llama3.1-8B, so the chip is not a general accelerator in the way a GPU or TPU is.
Taalas says HC1 keeps a bit of flexibility via a configurable context window and fine-tuning through low-rank adapters (LoRAs), which add small trainable matrices on top of a frozen base model. Reported demo numbers include about 0.138s for a long response at 14,357tokens/s, and upto 17,000tokens/s per user for Llama3.1-8B.
On cost and power, the same write-up claims roughly 0.75c per 1M tokens for Llama3.1-8B and 12-15kW per rack versus 120-600kW per GPU rack, with DeepSeek-R1 numbers partly simulated. A key limitation is operations, because a data center would need different chips for different models and then refresh them as models change, even if Taalas can update by changing only 2 metal layers in about 2 months. Quality is also a constraint today because the “Silicon Llama” is aggressively quantized with mixed 3-bit and 6-bit weights, and the roadmap points to 4-bit floating point formats on a future HC2 to reduce accuracy loss.
🗞️ Thomas Wolf, Huggingface founder writes a viral piece on Twitter - The biggest change AI brings to programming is not faster coding, it is cheaper replacement of everything you thought was “too entrenched to touch.”
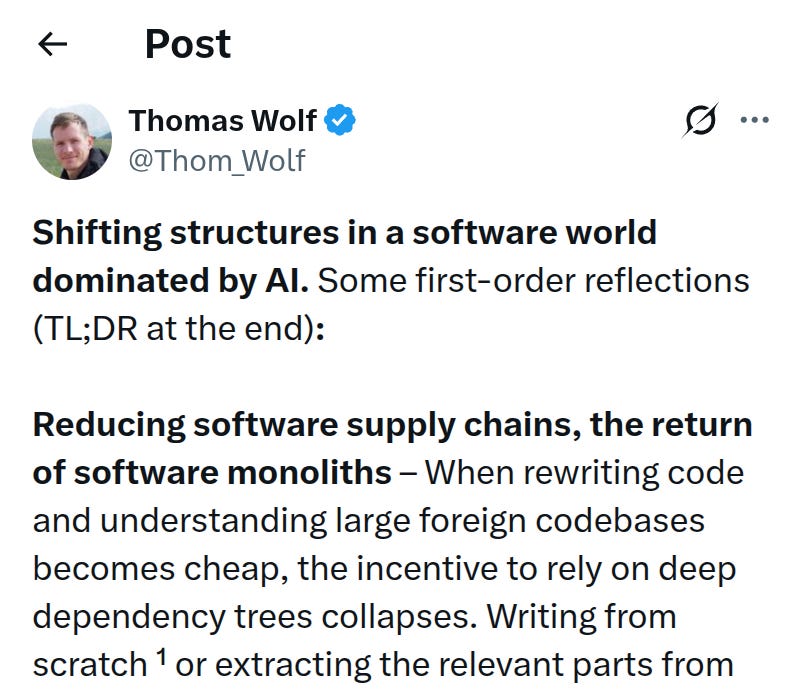
If AI makes reading, understanding, and rewriting code cheap, a lot of today’s software habits will flip.
First, dependency-heavy software may shrink. Instead of pulling in long chains of libraries, teams may rebuild what they need or extract only the useful parts, because an AI agent can do that quickly. That can mean smaller apps, faster startup, better performance, and fewer supply chain security risks. This pushes software back toward bigger “monolith” codebases, built more end to end.
Second, old code will stop feeling “untouchable.” The Lindy effect, the idea that old systems survive because they are proven, weakens if AI can fully map and rewrite legacy systems. The risk is that hidden edge cases still exist, so testing and formal verification become much more important, not optional.
Third, language popularity may shift. If humans write less code, languages chosen for human friendliness matter less, and languages that are strongly typed, safer, and easier to formally verify may win.
Finally, open source economics and community incentives could change if code is mostly written and read by machines, and new programming languages may emerge that are designed for AI, not for humans.
🗞️ Top Github Resource: NanoClaw, the lightweight alternative to Clawdbot / OpenClaw already reached 10.5K Github stars ⭐️

Compared with OpenClaw, NanoClaw’s specialty is simplicity plus OS level isolation.
Much smaller and manageable codebase, only 4K lines.
Runs in containers for security.
Connects to WhatsApp, has memory, scheduled jobs, and runs directly on Anthropic’s Agents SDK
stores state in SQLite, runs scheduled jobs, and keeps each chat group isolated with its own memory file and its own Linux container so the agent only sees directories you explicitly mount.
its safety model leans on application controls like allowlists and pairing codes inside a shared Node process.
OpenClaw is built for broad multi channel coverage, while NanoClaw intentionally stays minimal so you customize by changing a small codebase instead of operating a big framework.
In NanoClaw, a “skill” is a small folder, centered on a SKILL[.]md file, that teaches Claude Code how to carry out a repeatable change or workflow, and it can be invoked as a slash command like /add-telegram.
The core developer says clearly “Don’t add features. Add skills.”
So e.g. instead of adding Telegram code to the main NanoClaw repo for everyone, a contributor should just write a skill that tells Claude Code exactly how to edit your fork, add the needed files, update the runtime wiring, and verify it works.
When you run /add-telegram, Claude applies those code changes to your copy, so the upstream project stays small and you still end up with a clean, Telegram-enabled codebase.
🗞️ Andrej Karpathy also posted a viral post on how Claws turn agents into orchestrators, and containers look like the basic safety belt.
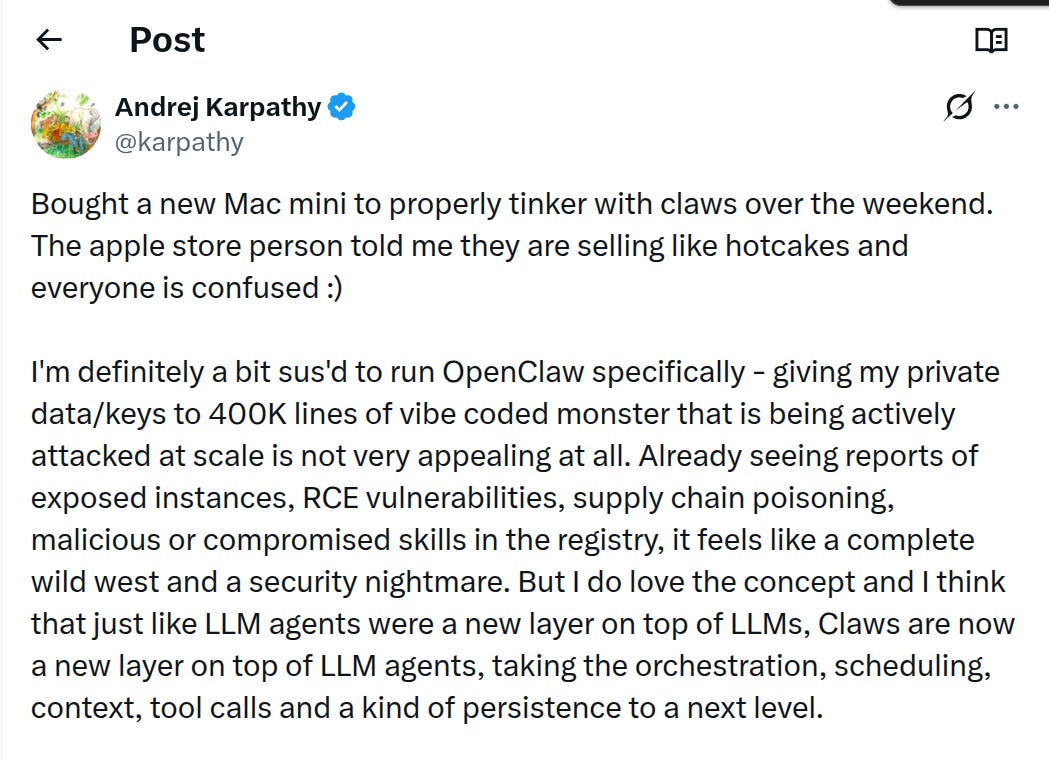
A new layer called Claws is emerging on top of LLM agents, focused on handling orchestration, scheduling, context handling, tool calls, and persistence so an agent can keep running and coordinating work over time.
Running a massive implementation like 400K lines of code feels risky when it can touch private data and keys, because large, popular codebases tend to attract constant real-world attacks and accidental misconfigurations.
People are already flagging practical failure modes like exposed deployments, remote code execution bugs, supply chain attacks, and malicious or compromised “skills” distributed through a shared registry.
Smaller implementations are showing up fast, and a key appeal is being small enough to audit, modify, and reason about, for example a core engine around 4,000 lines of code.
Container-first execution is getting attention because containers put hard walls between components, which helps limit damage when something breaks or gets compromised.
A standout idea is treating “configuration” as skills that change the codebase directly, so adding an integration can look like a command that teaches the agent to edit the repo, instead of stacking messy config files and branching logic.
This pushes a new pattern, keep a maximally forkable base repo, then use skills to generate the exact customized variant needed for a specific setup.
Local setups are attractive for tinkering and for connecting to devices on a home network, while cloud-hosted options feel harder to experiment with and harder to trust with secrets.
Opinion: The idea is powerful, but the security surface grows fast once real secrets, third-party skills, and exposed endpoints enter the picture, so the safest path looks like small, auditable, container-first builds with strict defaults.
Opening sentence: Claws are becoming a new “control layer” above LLM agents, but the practical story right now is a tradeoff between powerful automation and a big, messy security surface that only gets manageable when the system stays small, auditable, and container-first.
That’s a wrap for today, see you all tomorrow.