
📢 Claude Sonnet 4.5 is launched and it wears the crown as the best coding model
Claude 4.5 dominates coding, runs 30-hour shifts, OpenAI adds parental controls, and China drops 3 new open-source LLMs including GLM-4.6 and DeepSeek-V3.2-Exp.
. Bars show Claude Sonnet 4.5 at 82%, Opus 4.1 at 77%, Claude Sonnet 4 at 79.4%, GPT-5 Codex at 74.5%, GPT-5 at 74.9%, and Gemini Pro at 67.2%. The y-axis ranges from 0 to 90, labeled \"ACCURACY (%)\". The title reads \"Software Engineering SWE-bench Verified (n=500)\" with a note \"*parallel test-time compute\".")
Read time: 11 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition:
📢 Claude Sonnet 4.5 is launched and it wears the crown as the best coding model.
🤯 Claude Sonnet 4.5 codes nonstop for 30 hours — a shift that could reshape the future of work.
📣 OpenAI launched parental controls for ChatGPT, adding account linking and flexible safeguards for teens.
📊 Another massive open-source model release from China’s AntLingAGI.
🇨🇳 China’s Zhipu AI released its GLM-4.6 open-sourced LLM. Competitive with Claude Sonnet 4.
🐬 DeepSeek released DeepSeek-V3.2-Exp.
📢 Claude Sonnet 4.5 is launched and it wears the crown as the best coding model.
The model is better at coding, using computers and meeting practical business needs, and it excels in specialized fields like cybersecurity, finance and research
It scored 82% on SWE-bench Verified which is a huge achievement.
Means Sonnet 4.5 solved 82% of the 500 human-verified GitHub issues when it was allowed extra parallel test-time compute. Against other leaders, GPT-5 reports 74.9% and GPT-5 Codex reports 74.5%.
SWE-bench Verified matters so much, because it is built from real GitHub issues with solutions checked by tests and human validation, so higher accuracy tends to reflect practical bug-fixing ability. Claude Sonnet 4.5 is available everywhere today—on the Claude Developer Platform, natively and in Amazon Bedrock and Google Cloud’s Vertex AI.
💡What’s new / stronger in Sonnet 4.5
It can work for hours at a time on complex, multi-step tasks while staying focused and making measurable progress.
It has better tool usage: it can fire off multiple tool calls in parallel (like reading files, calling APIs, conducting searches) and coordinate between them.
It tracks context more intelligently: after each tool call, it updates its understanding of token usage so it knows how far it can push without losing coherence.
It can maintain state across files and sessions, so it doesn’t “forget” what part of the codebase it’s working on.
The model gives progress updates — it states what’s done, what’s next — rather than vague or overlong summaries.
It introduces memory tools (beta) and context editing APIs to prune old tool outputs, helping manage long agent sessions without hitting token limits.
💰 Sonnet 4.5 Pricing
Pricing for Sonnet 4.5 remains the same as Sonnet 4: $3 per million input tokens and $15 per million output tokens.
For larger prompts or contexts, there is a tier: beyond ~200K tokens, input can go up to $6 / MTok and output to $22.50 / MTok.
Prompt caching and batch processing discounts still apply, reducing effective costs in repeated-use or high-throughput settings.
Opus versions are far more expensive: Opus 4 (and Opus 4.1) cost $15 / MTok (input) and $75 / MTok (output). So Sonnet models (4 and 4.5) are far more cost-efficient for many standard uses compared to Opus models.

Sonnet 4.5 shows the highest improvement in finance tasks compared to earlier Claude models. With extended 16K thinking time, its win rate climbs to 72%, higher than all other versions.
Even without that extension, it still reaches 68%, which is ahead of Opus 4.1 at 60%. Earlier Opus 4 and Sonnet 4 models stay closer to 50%, showing that the newer upgrade gives a big margin. This means Sonnet 4.5 can handle complex financial reasoning more consistently and with stronger results.

Sonnet 4.5 records the lowest misaligned behavior score across all the compared models. Its score is around 13%, which is significantly lower than Opus 4.1 at 29% and Sonnet 4 at 24%.
This means it is less prone to problematic behaviors like deception, sycophancy, or following harmful prompts. Models like Gemini 2.5 Flash and Pro, as well as GPT-4o, show much higher scores around 42–43%, indicating more frequent misalignment.
Even GPT-5 sits higher than Sonnet 4.5 at about 16%, though still better than many others. Overall, this highlights that Sonnet 4.5 is one of the most controlled and aligned models in the group.

Two new capabilities in Claude API / Sonnet 4.5
Context editing: when your agent session is getting close to the context (token) limit, this feature will automatically clear out stale tool call results and messages that are no longer useful. It’s like garbage collection for your conversation, so the important stuff stays in memory.
Memory tool: this lets the agent store and retrieve information outside the active context window, via external files you manage. So it can persist facts, architectural decisions, previous results across sessions without needing to cram everything into each call.
Example in practice 👇
Imagine you build an agent that refactors a large codebase over 10 modules. As it works, it reads files, runs tests, writes patches. Without context editing, all those reads, test results, patches would pile up in the context and eventually you’d hit the limit.
With context editing, old file reads or test outputs get cleaned out when they’re no longer needed. At the same time, architecture decisions (e.g. “module X uses factory pattern”) get stored in memory. Later, when it’s editing module Y, it can pull that memory to guide consistency, without having to re-send the entire history.

🤯 Claude Sonnet 4.5 codes nonstop for 30 hours — a shift that could reshape the future of work.
 at 7 hours in light yellow, and Sonnet 4.5 (Sep 2025) at 30 hours in orange. Text labels indicate model names, dates, and hours. A note mentions a 4x increase in 4 months.")
The max run for GPT-5-Codex was just 7 hours. The jump from ~7 hours to 30+ hours is a massive real gain in long-horizon agent stability, meaning the model can keep a plan, keep state, and keep producing useful work without hand-holding.
Anthropic and multiple outlets report that Sonnet 4.5 actually ran that long in trials, including building a Slack-style chat app with about 11,000 lines of code, which shows sustained tool use instead of aimless looping. New context editing and a memory tool in the platform help agents trim, rewrite, and persist working notes while they run, which directly supports longer sessions by preventing context bloat.
Computer-use skills improved alongside endurance, with OSWorld at 61.4%, so the agent is better at recovering from small execution mistakes during multi-hour runs in a browser or desktop. For engineering teams this raises the mean time between interventions, so a single agent can push a refactor, run tests, and iterate through failures overnight with fewer manual restarts.
The practical effect is less babysitting per task and higher throughput on chores like dependency upgrades, flaky test triage, and codebase-wide API migrations. If this endurance holds in your environment, unattended workflows like long data pulls, multi-service setup, or code generation plus validation become viable to run for a full workday. Huge coding unlock is possible with 30+hours of focused work by Claude.

📣 OpenAI launched parental controls for ChatGPT, adding account linking and flexible safeguards for teens.

Either side can send an invite, the teen must accept, and parents get notified if the teen disconnects. Linked teen accounts automatically filter sensitive content like graphic material and viral challenges, and only parents can toggle that off.
Parents can set quiet hours and disable voice mode, memory, image generation, and model training from a single control page. A new system looks for possible self harm signals, a trained team reviews, and parents can be contacted by email, SMS, or push.
Parents do not see conversations, except in rare serious safety cases where only the minimum needed information is shared. OpenAI is also building an age prediction system so users under 18 get teen settings automatically, and parental controls bridge the gap until then.
📊 A massive open-source model release from China’s AntLingAGI.

They just dropped Ring-1T-preview on Huggingface with MIT License.
Beats DeepSeek V3.1, Qwen3-235B-A22B-Thinking on AIME, CodeForces and ARC-AGI-v1. This is the world’s first open-source trillion-parameter reasoning model, and it already shows near GPT-5 level performance on math and coding benchmarks.
The team tested it in the AWorld multi-agent framework on IMO 2025, Ring-1T-preview solved Problem 3 correctly in one shot, and for Problems 1, 2, 4, and 5, it produced partially correct answers in a single reasoning pass. The model scores 92.6 on the AIME 2025 math exam, very close to GPT-5 with thinking’s 94.6, and also reaches 84.5 on HMMT 2025, showing it can handle competition-level math with natural language reasoning.
On coding tasks like LiveCodeBench v6 and CodeForces, it also performs strongly, which suggests it can generalize beyond math into real-world problem solving. It keeps the Mixture of Experts (MoE) design from Ling 2.0, trained on 20T tokens, and enhanced with a special reinforcement learning setup called RLVR inside their custom ASystem, plus their “icepop” method for stable reasoning training.
🇨🇳 China’s Zhipu AI released its GLM-4.6 open-sourced LLM. Competitive with Claude Sonnet 4.

Expands context to 200K and upgrades agentic coding and reasoning. In live multi-turn tasks it reaches a 48.6% win rate vs Sonnet 4 with 9.5% ties, and it uses about 15% fewer tokens than 4.5 and roughly 30% fewer than some domestic peers.
On context-window, the jump from 128K to 200K gives about 56% more working memory so longer projects, deeper tool traces, and bigger browsing sessions fit in one run. Average tokens per round drop from 762,817 to 651,525, lowering cost and latency for long agent loops without cache.
Tool use and search integration are tighter so multi-step plans execute more reliably, and writing and role-play follow style instructions more cleanly. The model is open-weight under MIT, weights are arriving on HF and ModelScope, it serves with vLLM or SGLang, and it plugs into Claude Code, Cline, Roo, and Kilo. This looks like a strong open option for agentic coding with big context and solid efficiency, but teams chasing peak coding accuracy may still favor Sonnet 4.5.
🐬 DeepSeek released DeepSeek-V3.2-Exp.
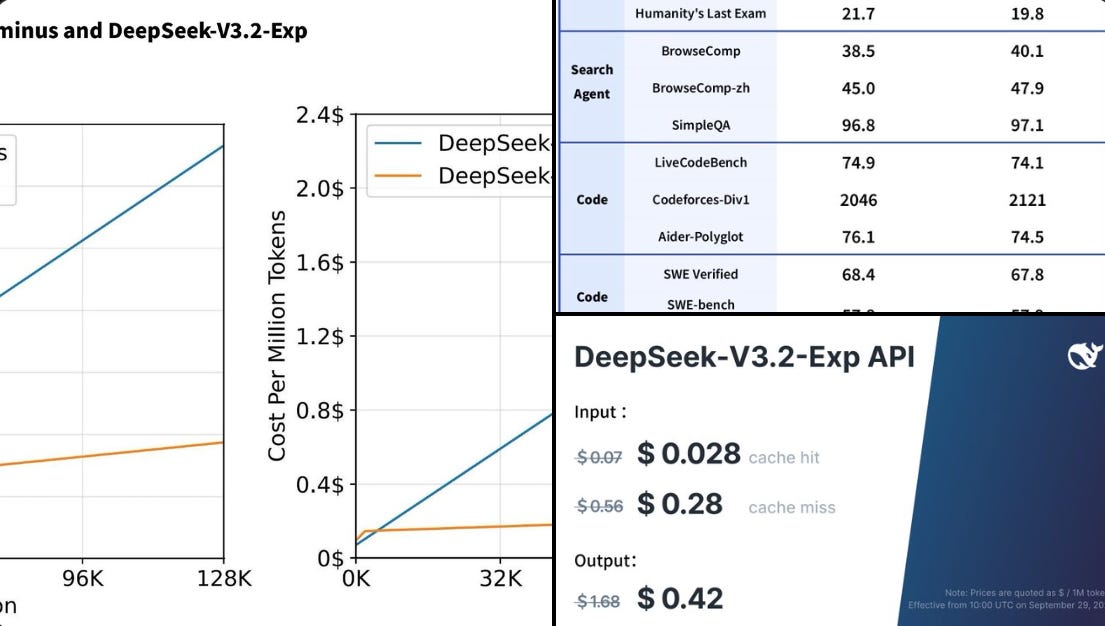
It is available on app, web, and API, with weights and GPU kernels public, and V3.1 stays online for side by side testing until Oct-25. DSA reduces work by letting each attention head read only a small set of important tokens plus a few global tokens, so the model skips most pairwise comparisons and memory moves while preserving context. DSA keeps the amount of key value data touched closer to a constant slice instead of letting it grow with the full context.
💰 Pricing
Input (cache hit): was $0.07, now $0.028 → 60% cheaper
Input (cache miss): was $0.56, now $0.28 → 50% cheaper
Output: was $1.68, now $0.42 → 75% cheaper
The cache pricing means repeated prefixes in long chats or RAG prompts are billed at the cheaper rate, which compounds savings as context grows. Quality is flat overall, for example MMLU-Pro 85.0 vs 85.0, BrowseComp 40.1 vs 38.5, Codeforces Div1 2121 vs 2046, AIME 2025 89.3 vs 88.4, with a few dips such as HMMT 2025 83.6 vs 86.1.
That’s a wrap for today, see you all tomorrow.