COAT: Compressing Optimizer states and Activation for Memory-Efficient FP8 Training
1.54x end-to-end memory reduction vs BF16.


1.54x end-to-end memory reduction vs BF16.
With COAT (Compressing Optimizer States and Activations for FP8 Training) 💡
Nearly lossless performance across LLM pretraining/fine-tuning and Vision Language Model training
Squeezes FP8 training memory by optimizing both optimizer states and activations
🎯 Original Problem:
Current FP8 training frameworks don't fully optimize memory usage. They keep optimizer states and activations in higher precision, wasting valuable GPU memory during training of large models.
🛠️ Solution in this Paper:
• COAT (Compressing Optimizer States and Activations for FP8 Training) introduces:
Dynamic Range Expansion: Aligns optimizer state distributions with FP8 range
Mixed-Granularity Activation Quantization: Uses per-tensor quantization for linear layers and fine-grained for non-linear layers
Group Scaling: Efficient per-tensor scaling balancing performance and precision
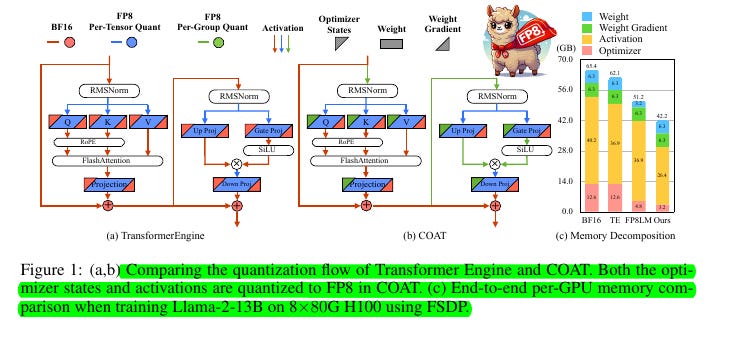
FP8 precision flow for both forward and backward passes
💡 Key Insights:
• FP8's representation range is under-utilized when quantizing optimizer states
• Second-order momentum is more sensitive to quantization than first-order
• Non-linear layers account for ~50% of memory footprint in Llama models
• Quantizing across token axes hurts accuracy in layernorm operations
📊 Results:
• 1.43x training speedup compared to BF16
• Enables full-parameter training of Llama-2-7B on single GPU
• Doubles batch size in distributed training settings
🛠️ The key technical innovations of COAT
Dynamic Range Expansion - Aligns optimizer state distributions with FP8 representation range to minimize quantization error by using an expand function that better utilizes FP8's full dynamic range.
Mixed-Granularity Activation Quantization - Uses per-tensor quantization for linear layers and fine-grained quantization for non-linear layers to optimize memory usage while maintaining accuracy.