CodeMMLU: A Multi-Task Benchmark for Assessing Code Understanding Capabilities of CodeLLMs
CodeMMLU, a comprehensive multiple-choice question-answering benchmark for evaluating code understanding in LLMs


CodeMMLU, a comprehensive multiple-choice question-answering benchmark for evaluating code understanding in LLMs
Covers 10,000+ questions across diverse domains, tasks, and programming languages
Original Problem 🔍:
Existing code benchmarks focus on open-ended generation tasks, failing to adequately assess code understanding and comprehension in large language models (LLMs). This limits evaluation of LLMs' true capabilities in software engineering tasks beyond code generation.
Key points on CodeMMLU 💡:
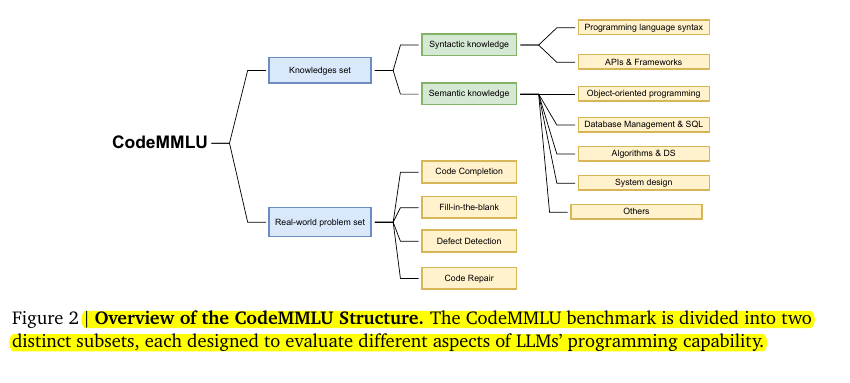
• Assesses models' reasoning about code rather than just generation
• Includes knowledge-based tests and real-world programming problems
• Uses multiple-choice format for reliable, scalable evaluation
Key Insights from this Paper 💡:
• Reveals limitations in state-of-the-art models' code comprehension beyond generation
• Demonstrates strong correlation between software knowledge and real-world task performance
• Highlights inconsistencies between open-ended and multiple-choice code evaluation
• Shows ineffectiveness of chain-of-thought prompting for code understanding tasks
• Exposes selection biases in LLMs for multiple-choice coding questions
Results 📊:
• GPT-4 outperformed all models across diverse CodeMMLU tasks
• Meta-Llama-3-70B-Instruct achieved highest score among open-source models (62.45%)
• Models struggled most with defect detection tasks
• Instruction-tuned models substantially outperformed base versions
• Performance on knowledge tests correlated with real-world problem-solving (r=0.61)