


Reading Time: 21 mints
Table of Contents
Introduction
Architectural and Functional Differences
Evaluation Metrics and Performance Benchmarks
Implementation Strategies (Open-Source vs. Proprietary)
Industry Applications Across Sectors
Cost-Effective Deployment Strategies
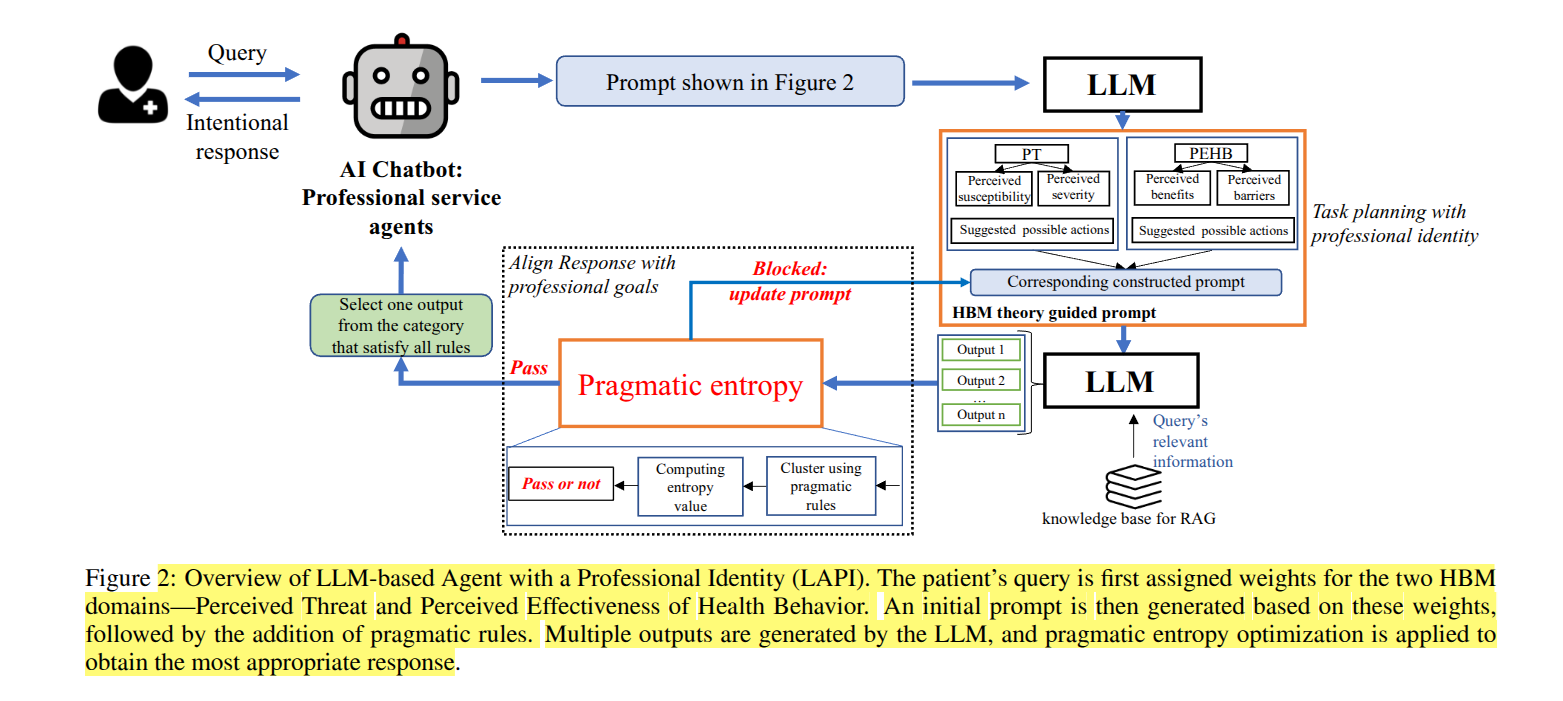
Introduction
Chatbots have evolved from simple rule-based scripts to sophisticated large language model (LLM)-powered conversational agents. Traditional chatbots followed predefined rules or decision trees, enabling basic automation but often yielding rigid, scripted interactions. In contrast, recent LLM-based agents (e.g. GPT-4, PaLM 2) leverage massive neural models to understand and generate natural language with remarkable fluency and context-awareness (AI Chatbots as Professional Service Agents: Developing a Professional Identity).
This literature review examines how these two paradigms differ in design and capabilities, how they are evaluated, the tools and platforms for building them, their use cases in various industries, and strategies to deploy them cost-effectively.
Architectural and Functional Differences
Rule-Based Chatbots: Classic chatbots rely on hand-crafted rules, keywords, and flows. They operate on predefined scripts and deterministic logic, which makes them simple and predictable but not very flexible. Such bots excel at structured tasks (like FAQs or menu-driven queries) where users follow a narrow path. However, they struggle with ambiguity or unforeseen phrasing – if a user asks something in a way that wasn’t anticipated, a rule-based bot often fails to understand or responds with a generic fallback. These systems do not learn from new interactions; maintaining them requires continuous manual updates to add new rules and utterance variations. They also have limited memory of context, handling each query in isolation unless explicitly programmed with state tracking.
LLM-Based Chatbots: Agents built on LLMs use advanced NLP and ML to generate responses. Rather than fixed rules, they tap into pre-trained knowledge and language understanding learned from large-scale data. This allows them to comprehend flexible, free-form user input and respond with contextually relevant, human-like text (here).

LLM chatbots can handle open-domain conversations, maintain multi-turn context, and adapt to varied user expressions. For example, they can recognize rephrasings of a request that a rule-based bot would miss, and still produce an appropriate answer. They also exhibit skills like sentiment awareness and the ability to perform on-the-fly reasoning or summarization far beyond the static capabilities of a scripted bot. That said, LLM agents operate as black-box models – their behavior is stochastic and shaped by probabilities. This means they may generate incorrect or unsupported statements (“hallucinations”) or inconsistent styles if not properly constrained (Script-Strategy Aligned Generation: Aligning LLMs with Expert-Crafted Dialogue Scripts and Therapeutic Strategies for Psychotherapy).

Unlike rule-based bots that strictly follow predefined dialogue paths (ensuring consistency but limited flexibility), LLM bots offer dynamic language generation at the cost of less predictability and control. In high-stakes applications, this unpredictability is a concern, as an LLM might produce insensitive or non-compliant outputs without safeguards. Table 1 summarizes key differences:
Development: Rule-based bots are manually programmed (no training data needed), whereas LLM bots are built on models pre-trained on massive text corpora and often fine-tuned for specific tasks.
Adaptability: Rule-based systems cannot handle inputs outside their scripted rules and don’t improve with use. LLM systems can cover a wide range of topics and implicitly improve with model updates or additional fine-tuning.
Context Handling: LLM agents maintain conversational context and understand intent even in complex, multi-turn dialogues. Rule-based agents have very limited context memory, usually needing explicit state handling for multi-turn flows.
Control: Rule-based bots offer high transparency and deterministic behavior (every reply is traceable to a rule), which is important for compliance. LLM bots excel at fluent language and understanding nuance, but require techniques like prompt engineering or safety filters to align with desired policies, since their reasoning is opaque.
Examples: A rule-based customer support bot might navigate a fixed decision tree for troubleshooting, asking the user a series of yes/no questions. An LLM-based support agent can accept an open-ended problem description and directly generate a tailored solution or ask context-specific follow-ups, mimicking how a human operator might respond.
Evaluation Metrics and Performance Benchmarks
Comparing rule-based and LLM-driven chatbots requires careful evaluation, since each excels on different aspects. Recent work emphasizes using consistent, objective metrics across systems to ensure a fair comparison. Key performance indicators include:
Task Success and Containment: For task-oriented bots, a fundamental metric is whether the bot solves the user’s problem without human intervention. This can be measured by containment rate (conversations handled to completion by the bot). A rule-based bot might have a high success rate on the narrow queries it’s designed for, but zero success outside that scope. An LLM-based bot typically covers more queries successfully, but evaluation must note if it only appears to answer (fluently) without actually solving the user’s issue. Related metrics include goal completion rate and conversion rate (for sales bots).
User Satisfaction: User feedback or proxy metrics gauge quality. Customer satisfaction scores or NPS from chat interactions can be used. Implicit signals like whether users ask to speak to a human (indicating frustration) are also tracked. LLM-based agents often score higher on naturalness and user preference in studies, since they respond more conversationally. For instance, they can handle small talk or off-script questions that would stump a rule-based bot, improving the user’s perceived experience.
Accuracy and Quality: Especially for informative chatbots, response accuracy is critical. This is evaluated via ground-truth comparison when possible. Traditional NLP metrics like BLEU, ROUGE, or F1 have been used to compare bot answers to reference answers for a set of queries. However, these often fail to capture conversational quality. Newer evaluations leverage LLMs as graders – e.g. using GPT-4 to score chatbot responses on correctness and coherence (A Comparison of LLM Fine-tuning Methods and Evaluation Metrics with Travel Chatbot Use Case).

One study evaluating domain-specific bots compared answers against “golden” reference answers and additionally used GPT-4 to rate responses, combined with human judgment. Such multi-faceted evaluation is becoming standard to objectively benchmark LLM chatbot performance.
Latency and Real-Time Performance: Dialogue systems are interactive, so response time matters. Metrics like average response latency and throughput (queries handled per second) are tracked. LLM-based services can be slower, especially if using large models via API, whereas rule-based bots execute conditional logic almost instantly. Optimizations like prompt truncation, caching, or using smaller model variants are employed to meet acceptable latency for LLM bots.
Cost and Efficiency: As part of evaluation, teams consider cost per conversation (especially relevant when using paid LLM APIs) and resource utilization. A seemingly “smarter” LLM bot might require significantly more compute, so its deployment cost could outweigh benefits if not assessed. Rasa researchers stress measuring cost efficiency and scalability alongside quality for a holistic evaluation.

It’s important to evaluate chatbots in scenarios that reflect real-world usage (“online” evaluation) in addition to offline benchmarks. Live A/B tests can compare a rule-based system against an LLM-based system on actual user queries. For example, one can route a percentage of customer chats to a new LLM agent and measure containment and customer satisfaction directly against the control (rule-based bot) . Such trials have shown LLM agents often handle a wider array of queries and achieve higher self-serve rates, but they may introduce new failure modes (like occasional nonsensical answers) that need to be quantified. Overall, using a combination of foundational metrics (solution rate, CSAT, cost, latency) and qualitative assessments (human or LLM-based ratings of conversation quality) is the state-of-the-art approach to benchmark conversational agents.
Implementation Strategies (Open-Source vs. Proprietary)
Building a conversational agent can involve a spectrum of tools and frameworks. Recent literature and industry blogs highlight two broad approaches:
Open-Source Frameworks and Tools: A rich ecosystem of open-source libraries exists for both rule-based and LLM-based chatbot development. Rasa (open source) is a popular framework that traditionally enables intent classification, entity extraction, and dialogue management via rules or small ML models. Developers define training data for intents and design conversational flows (stories) or rules in Rasa; the assistant then uses these to decide responses. This gives fine control over dialogue structure and is often used on-premises for data privacy. Haystack and LlamaIndex (formerly GPT-Index) are open tools focusing on retrieval-augmented chat – for example, powering an LLM with a document search module to ground its answers in a knowledge base. LangChain is another influential open-source library, focused on LLM orchestration: it provides abstractions to build “chains” of prompts and integrate LLMs with external tools or data. LangChain supports various LLM providers (OpenAI, Hugging Face models, Cohere, etc.) and features for memory, tool use (e.g. calculators, web search), and agent behaviors. These open frameworks give developers flexibility to customize logic and often support LLM-agnostic integration, allowing swapping between models or providers. For example, a startup could prototype using OpenAI’s GPT-4 via LangChain, and later switch to an open-source Llama 2 model on their own servers with minimal code changes. Open-source solutions are attractive for avoiding vendor lock-in and allowing on-prem deployments (important for sensitive data). However, they require more engineering effort to deploy and scale. In practice, many teams combine open-source and proprietary tech: e.g. using an open-source front-end (Rasa for dialogue handling) but calling a proprietary LLM via API for certain responses.
Proprietary Platforms: Major cloud providers and tech companies offer end-to-end chatbot platforms, which increasingly blend rule-based and LLM capabilities. These platforms abstract away a lot of the complexity, providing graphical interfaces and managed services. Google Dialogflow CX, for instance, allows designers to create a dialog flow with stateful routes and slot-filling (traditional approach), but it now also offers “fully generative” mode using Google’s Vertex AI LLMs for intent handling and response generation (Generative versus deterministic | Dialogflow CX - Google Cloud). In such a hybrid, the bot tries to match user input to a defined intent; if confidence is low, it can invoke a generative model like ChatGPT or Google’s PaLM to handle the query in a free-form manner. Microsoft’s Azure Bot Framework similarly integrates with Azure OpenAI Service, enabling a bot to call GPT-4 or other models as part of its responses. Microsoft’s Power Virtual Agents have added features to inject generative answers alongside guided flows. IBM Watson Assistant (watsonx) has introduced a new transformer-based backbone model and allows integration of IBM’s foundation models into the dialogue system. In IBM’s architecture, a developer can wire up a dialog node to call a watsonx.ai generative AI service, effectively bringing LLM responses into the otherwise rule-driven Watson Assistant flow (Integrate watsonx Assistant with watsonx.ai foundation models ). This offers the “best of both” – deterministic flows for expected interactions and an LLM fallback for unexpected queries or for dynamically creating responses (like summarizing info for the user). Other enterprise platforms like Amazon Lex, Salesforce Einstein Bots, and Oracle Digital Assistant are also adding large language model support under the hood.
Choosing between open-source and proprietary often depends on requirements like data control, scalability, and team expertise. Open-source gives greater customization and transparency (you can audit and tweak every part of the system) but might lack the ease-of-use and enterprise integrations of commercial platforms. Proprietary solutions offer quick development, hosting, and maintenance out-of-the-box, at the cost of recurring license/API fees and less flexibility. Notably, many organizations adopt a hybrid implementation: using proprietary services for core NLU or LLM capabilities while orchestrating logic in an open-source framework. For example, one 2024 case study combined Rasa’s rule-based intent handling with OpenAI’s GPT-4 for intent classification when Rasa’s confidence is low. This way, common queries follow a controlled script, and only more complex or off-track queries invoke the LLM, thereby balancing reliability and intelligence.
Example of a hybrid chatbot architecture combining a rule-based framework (Rasa) with an LLM. The Rasa component manages intents and dialogue flow, while the LLM (OpenAI GPT) handles queries that fall outside the predefined intents, using a shared backend to coordinate responses.
Modern frameworks like Hugging Face Transformers also provide building blocks for both approaches – you can instantiate a DialoguePipeline with a specific model (rule-based logic or an LLM) and easily switch models. Indeed, integration packages now exist (e.g. Hugging Face’s partnership with LangChain) to streamline using open-source models within those higher-level frameworks (Hugging Face x LangChain : A new partner package). The trend in 2024–2025 is toward interoperability: enabling conversational AI developers to mix and match rule-based dialogue management, retrieval modules, and LLM generation as needed, rather than a strict either/or choice.
Industry Applications Across Sectors
Conversational agents are being deployed across many industries, each with different requirements and benefits. Below we highlight applications of rule-based and LLM-based chatbots in various sectors:
Customer Service & E-commerce: This is a classic domain for chatbots. Rule-based bots have long handled FAQs, order tracking, or simple troubleshooting, deflecting calls from human support. The impact is significant – replacing human agents with chatbots was projected to save retailers around $439 billion by 2023 in operating costs (AI Chatbots as Professional Service Agents: Developing a Professional Identity). LLM-powered customer service agents take this further by understanding free-form customer queries and intent. They can parse complex issue descriptions and troubleshoot in a conversational manner, improving first-contact resolution. For example, an LLM agent can handle an angry customer’s paragraph-long complaint and extract the key issues to address, which is hard for a rules-based bot. Companies are leveraging these for 24/7 support on websites and messaging apps, often seeing improved customer satisfaction due to more natural interactions. At the same time, rule-based flows are sometimes kept for critical parts (like authentication or retrieving order status) to ensure accuracy, with the LLM providing the conversational glue around those steps.
Healthcare: In healthcare, accuracy and compliance are paramount. Early healthcare chatbots were rule-based symptom checkers or appointment schedulers. Today, LLM-based medical assistants can engage in open-ended dialogue about health concerns, provide medical information, and even assist doctors. Notably, large models like ChatGPT have been evaluated on medical exams: one study found ChatGPT’s answers to USMLE exam questions were comparable to a third-year medical student’s performance (A Complete Survey on LLM-based AI Chatbots). LLM chatbots can provide patient education on conditions and medications in plain language, available on demand. For instance, an LLM agent can explain a diagnosis or a prescription’s instructions to a patient, personalized to their context. In mental health, generative AI chatbots like Wysa or GPT-4-based companions are used for therapeutic conversation and coaching, although care is taken to avoid the pitfalls of unsupervised generative behavior in sensitive situations. Rule-based systems in healthcare (like scripted triage bots) offer reliability and safety – they won’t deviate from approved responses – but lack the empathy and broad knowledge an LLM can provide. A hybrid approach is emerging: using LLMs to draft responses that are then filtered or checked against medical guidelines (the rule-based layer) before presenting to users (Script-Strategy Aligned Generation: Aligning LLMs with Expert-Crafted Dialogue Scripts and Therapeutic Strategies for Psychotherapy).
Finance & Banking: Banks and financial services use chatbots for customer support (e.g. checking account balances, resetting passwords) and increasingly for advisory and internal analytics. Traditional bots here had to be carefully programmed to handle account queries securely and provide canned responses about products. LLM-based bots can understand complex financial questions and even analyze financial data for the user. For example, an AI assistant might answer “How did my spending on groceries this month compare to last month?” by actually examining transaction data and giving a summary – something earlier bots couldn’t do unless explicitly coded. Research suggests LLMs like ChatGPT can offer investment insights and financial research assistance; one experiment showed ChatGPT producing analytical summaries that matched or exceeded conventional methods for certain stock questions (A Complete Survey on LLM-based AI Chatbots). Some wealth management firms are prototyping GPT-based advisors (with human oversight) to interpret market news for clients or generate personalized portfolio explanations. Multilingual capability is a big plus in finance – a single LLM chatbot can serve customers in many languages, whereas rule-based bots often need separate training data per language. That said, compliance and accuracy are critical: rule-based workflows are still used for confirming transactions or handling sensitive tasks to avoid errors. Overall, finance chatbots are moving toward AI-hybrid models that combine the precision of rule-based transaction handling with the flexibility of LLM-driven Q&A and advice.
Enterprise Productivity & Internal Ops: Conversational agents are not just for external users; many companies deploy them internally to support employees. IT helpdesk bots and HR assistants are common examples. A rule-based IT bot might walk an employee through a password reset or software install via a fixed script. New LLM-powered internal agents can ingest corporate knowledge bases (wikis, SharePoint, policy documents) and answer a wide range of employee queries in natural language. This boosts productivity by saving staff from digging through manuals. Studies indicate that LLM assistants can augment employees by handling repetitive queries and providing on-the-fly expertise, rather than replacing workers (Building a Cost-Optimized Chatbot with Semantic Caching | Databricks Blog). For instance, a junior employee can ask an internal chatbot, “How do I submit an expense report for international travel?” and get a detailed, context-aware answer pulled from the company’s finance policy and formatted as step-by-step instructions. Such capability goes beyond the linear Q&A of old FAQ bots. Enterprises also use chatbots for onboarding (answering new hire questions), training (quizzing employees or delivering tutorials), and project management (integrating with calendars, task trackers, etc.). In these scenarios, LLM-based bots shine in understanding the many ways employees might ask a question and in parsing technical jargon. The main challenge remains ensuring the bot’s answers are correct per company policy – often addressed by retrieval augmentation (the bot cites the official policy text) or a fallback to a deterministic answer if high confidence. By deploying AI assistants for internal support, organizations have reported reduced workload on HR/IT teams and faster response times. Importantly, scalability is key: whereas a rule-based internal bot might break as content grows, LLM-based solutions can scale to thousands of topics (limited only by the data it’s trained or provided with) (What to Know About Chatbot Development Tools | The Rasa Blog).
Cost-Effective Deployment Strategies
The surge in LLM-driven chatbots has raised new considerations around deployment cost and efficiency. Large language models can be resource-intensive, but 2024–2025 innovations and best practices offer ways to maximize performance while controlling costs for different organizational needs:
Optimize Model Size and Usage: Not every conversation requires a 175B-parameter model. Many startups adopt a tiered model approach, using smaller, cheaper models for straightforward queries and reserving big LLMs for complex cases. This dynamic routing ensures simple FAQ questions don’t incur the cost of a GPT-4 call. In practice, one might use an open-source 7B model (running on a CPU or single GPU) to handle basic greetings or well-known questions, and only if that model is unsure does the query get escalated to a larger model or an API. Such intelligent routing has been reported to cut costs significantly without degrading user experience. Another tactic is employing on-demand scaling: running LLM containers serverlessly so that you scale down to zero instances during low traffic, and scale out when load spikes (Serverless vs. Dedicated LLM Deployments: A Cost-Benefit Analysis). This avoids paying for idle GPU time and is especially useful for businesses with intermittent chatbot usage (e.g., out of office hours).
Quantization and Efficient Fine-Tuning: A major breakthrough enabling cost savings is model quantization techniques like QLoRA. Quantization reduces the memory footprint of LLMs (for example, storing model weights in 4-bit precision instead of 16-bit) with minimal impact on accuracy. Researchers in 2023 showed that QLoRA can fine-tune a 65B parameter model on a single 48GB GPU without performance loss. In practice, this means organizations can take a large open-source model and fine-tune it on their domain data in-house cheaply, instead of paying for an expensive API or multi-GPU setup. The fine-tuned model (often with some billions of parameters) can then be deployed in a quantized state for inference, dramatically lowering the RAM/GPU requirements to run it. This enables startups with limited hardware to still leverage powerful LLMs. There is often a sweet spot in model size: a moderately sized fine-tuned model (e.g. 7–13B parameters) can achieve near GPT-3.5 level performance on a specific domain (Making LLMs even more accessible with bitsandbytes, 4-bit quantization and QLoRA), at a fraction of the serving cost of a larger model. Leveraging such open models avoids vendor fees entirely and provides cost predictability (just the infrastructure cost).

Caching and Retrieval to Reduce Calls: Many chatbot queries repeat over time, especially in customer service FAQs or knowledge-base lookups. An effective strategy is semantic caching: the system stores embeddings (semantic fingerprints) of user questions and their LLM-generated answers. When a new query comes in, it checks if a similar question has been answered recently. If yes, the bot can reuse or lightly adjust the cached answer instead of calling the LLM again. Databricks implemented this in their chatbot, showing that reusing responses for similar questions can dramatically cut down the number of expensive LLM invocations . Another approach is integrating a retrieval module so that for information-seeking queries, the bot first searches a vector database or document index for relevant text and then either serves that directly (for a simple answer) or feeds it into a smaller LLM to compose an answer. By offloading factual answer content to a knowledge base, the cognitive load (and required size) of the model can be reduced – you might not need the biggest model if you give it relevant context. This retrieval-augmented generation (RAG) strategy means the LLM doesn’t have to “know” everything in its parameters, which can allow using a cheaper model and also improves accuracy (since answers are grounded in retrieved facts).
Hybrid Systems and Fallbacks: As hinted earlier, combining rule-based components with LLMs can be cost-effective. A rule-based front-end can catch ultra-simple queries (like “What’s the office Wi-Fi password?” or menu navigation) which are essentially free to handle, and only invoke the LLM for the remainder. Similarly, if a conversation reaches a point where the confidence is low or the logic would require a complex answer, then call the LLM. This selective usage optimizes the spend on LLM API calls or compute time. One real-world example used a Rasa bot to handle intent classification and dialogue up to a point, and if the user’s input didn’t match any known intent with high confidence, they then called an LLM to interpret it and continue the conversation. This way, the LLM was only used in cases where it added value, estimated to be a small percentage of interactions, saving cost on the majority of routine exchanges.
Cloud Services vs. Self-Hosting: Startups often face the choice of paying for a managed API (OpenAI, etc.) or training their own model. In 2024, the cost calculations show trade-offs. APIs charge per call/token – e.g., OpenAI GPT-4 might cost $0.03/1K tokens . For low volume, this pay-as-you-go is cheaper than maintaining servers. But at scale, those token costs add up. Enterprises with large volume are exploring self-hosting open models to have a fixed infrastructure cost. An analysis by Microsoft’s engineers suggests that dedicated deployments can become more cost-efficient at high volumes, whereas serverless APIs are cost-efficient for spiky or low-volume use. Organizations also consider total cost of ownership: not just inference cost, but engineering, monitoring, and maintenance overhead. Many large enterprises opt for a middle ground by using cloud vendor offerings like Azure OpenAI or Amazon Bedrock within their own instance for a discounted rate, or negotiating enterprise plans for API usage. It’s advised to assess costs holistically – including model license fees if using proprietary models, cloud instance costs, and developer time for upkeep – when choosing a deployment strategy.

In summary, achieving cost-effectiveness with conversational AI often means being strategic about when and how you use LLMs. Through techniques like model distillation/quantization, intelligent caching, and hybrid architectures, even resource-constrained teams can harness large language models in production. Meanwhile, the steadily improving open-source model landscape offers viable alternatives to expensive proprietary models, which is a promising sign for democratizing advanced chatbots. As the field stands in 2025, savvy teams mix rules, retrieval, and generative AI – and switch tools when needed – to deliver robust chatbot solutions that are both high-performing and cost-conscious.