
🧮 Dario Amodei’s new blog with his classic strong opinion and reading it feels like AI race is hotter than many of us think.
Dario Amodei heats up the AI race, Decart’s Lucy 2.0 edits worlds in realtime, and China’s GLM-4.7-Flash crushes benchmarks under 100B params.

Read time: 9 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (26-Jan-2026):
🧮 Dario Amodei’s new blog with his classic strong opinion and reading it feels like AI race is hotter than many of us think.
Massive release from DecartAI : Lucy 2.0 a World Editing Model running at 1080p, 30FPS in realtime.
ARK Invest just released 2026 big ideas: The great acceleration and AI.
🏆 Great performance by China’s GLM-4.7-Flash (Reasoning) - the most intelligent open weights model under 100B total parameters
📡 Qwen3-Max Thinking outperforms Gemini 3 Pro and GPT-5.2 on Humanity’s Last Exam with search enabled.
🧮 Dario Amodei’s new blog with his classic strong opinion and reading it feels like AI race is hotter than many of us think.
How to Handle “The Adolescence of Technology” Like Adults
He thinks “powerful AI” could arrive within 1-2 years, so the priority is building practical defenses now.
Humanity is hitting a risky “technological adolescence” because AI power is rising faster than institutions can handle.
Powerful AI (coming in 2 years) will be smarter than top humans, can act online for days, can be copied into 1M+ instances, and can run at 10-100x human speed.
This progress is coming from steady scaling gains and feedback loops where today’s models speed up the work of building better models.
The first risk is autonomy, where systems develop unwanted goals, deceive, or behave differently when they detect they are being tested.
Defenses include a values “constitution”, mechanistic interpretability to inspect internals, plus monitoring and public disclosure.
He also argues for transparency laws, citing California SB53 and New York’s RAISE Act as early steps that avoid blunt regulation.
His point is basically “start with rules that force big AI companies to show their work, before you try to control everything they build.”
SB 53 and the RAISE Act are his examples of that first step, because they try to require frontier AI companies to do the transparency practices he already described, and they try to limit collateral damage by exempting smaller companies.
The second risk is misuse for destruction, especially biology, where an AI tutor can coach step by step and break the old link between skill and motive.
He cites mid-2025 tests suggesting 2-3x uplift on bio-relevant tasks, triggering extra safeguards like bio-risk classifiers that can add about 5% inference cost.
He supports gene-synthesis screening and better biodefense, but says prevention at the model and infrastructure level matters most.
The third risk is misuse for seizing power, via autonomous weapons, mass surveillance, and personalized propaganda, with the Chinese Communist Party (CCP) as the clearest near-term worry.
He argues democracies should stay ahead but draw bright red lines against domestic mass surveillance and mass propaganda, and tighten oversight for autonomous weapons and AI companies.
The fourth risk is economic shock, with up to 50% of entry-level white-collar jobs disrupted in 1-5 years and wealth concentrating enough to strain democracy.
The fifth risk is indirect effects, where faster science and new AI habits create surprises, and his policy throughline is to buy time by slowing autocracies through chip and tool export controls.
🏆 Massive release from DecartAI : Lucy 2.0 a World Editing Model running at 1080p, 30FPS in realtime.

Lucy 2.0 A breakthrough model capable of transforming the visual world in real-time. Moving beyond offline rendering, Lucy 2.0 delivers high-fidelity 1080p video generation with near-zero latency. You can try the model here directly.
Lucy 2.0 literally “redraws” the entire world pixel-by-pixel, while you are watching it.
e.g. If you want to be an anime character, it doesn’t just put a mask on you. It turns your skin into anime skin, your hair into anime hair, and the lighting in your room into anime lighting.
Lucy 2.0 is also trained to stop the generated video from slowly falling apart over time, so the same stream can run much longer without faces and details drifting.
So why is this a “Massive Deal”?
Traditional AI video-generation model takes a prompt, you wait 10–20 minutes, and the computer “bakes” a video for you. You couldn’t touch it or change it while it was happening.
But Lucy 2.0 works like a mirror.
It happens in real-time (30 frames per second). There is no waiting. You move your hand, the AI character moves its hand instantly. The craziest part isn’t the visuals; it’s the physics.
Usually, AI hallucinations are glitchy—hands merge into faces, walls melt. Lucy 2.0 understands how the world works without being told. It knows that if you take off a helmet, there is hair underneath. It knows that if you splash water, droplets fly. It learned “physics” just by watching millions of videos.
The physical behavior you see emerges from learned visual dynamics, not from engineered geometry or explicit physics engines.
Their official technical report explicitly states that the model does not use traditional 3D engines, depth maps, or wireframes. It is a “pure diffusion model.”
Architecture details of Lucy 2.0
It uses a pure diffusion model, meaning it makes each frame by repeatedly cleaning up noise until the picture matches the requested look and motion.
It does not build an explicit 3D model with depth maps or meshes, so things like contact, cloth, and objects separating have to come from patterns it learned from lots of video.
A common failure in regular video models is drift, meaning tiny errors in 1 frame get reused in later frames until faces, textures, or shapes fall apart.
Smart History Augmentation trains on the model’s own imperfect past frames and penalizes drift, so it learns to notice when it is going wrong and pull back.
The big deal is also the engineering stack, because for true real time performance of this model needs low overhead in kernels, memory movement, and streaming and Decart says AWS Trainium3 helped reach up to 4x higher frame-rate for this workload, which matters for cost and always-on use.
🧠 ARK Invest just released 2026 big ideas: The great acceleration and AI.

Global markets are entering an unprecedented phase of technology funding.
Data center systems investment could reach ~$1.4T by 2030 as inference costs collapse >99% and API demand surges.
Nvidia leads large model throughput, AMD and Google rival it for small models, and custom ASICs should keep gaining share.
Foundation models are becoming a consumer operating system, moving interactions to agents that plan, compare, and transact.
Purchasing agents compress checkout to ~90 seconds and could mediate ~25% of online spend by 2030.
AI search may reach 65% of queries by 2030 and push ad budgets toward AI interfaces.
Companies recoup the cost of an AI subscription in about 0.5 day, then as those tools boost output, total software spending could grow to $3.4T to $13T.
Example, if a $30 per user tool saves 1 hour worth $60 on day 1, it has paid for itself. Over a month, the extra saved hours justify buying more AI apps.
AI plus multiomics could cut drug development to ~8 years (instead of the usual ~12 to 15 years.) with ~4x lower costs and enable high value cures, including a ~$2.8T US TAM for ASCVD.
Reusable rockets are driving launch costs toward <$100 per kg, expanding satellite connectivity, and opening a path to space AI compute (pages 80 to 82).
Robotics, distributed energy, robotaxis, and autonomous logistics will lower transport, power, and delivery costs at global scale.
🏆 Great performance by China’s GLM-4.7-Flash (Reasoning) - the most intelligent open weights model under 100B total parameters

A mixture-of-experts model with 31B total parameters but only about 3B active per token.
Strong agentic capability per unit of compute, keeps a 200K-ish context window in the same family as GLM-4.7. On tau squared Bench Telecom it lands around 98.8% to 99%, which is wild because that benchmark is explicitly about agents coordinating actions with a “user” in a shared environment, not just answering questions.
Great for building internal agents for software work, terminal workflows, support-style automation, or “do this task in a tool-filled environment”, this is the kind of model that can change the economics. Where it looks shakier is the more “research assistant” side of reasoning and factual discipline. It scores -60 on the Artificial Analysis Omniscience Index, and on CritPt (a frontier physics evaluation) it’s down at 0.3%, which is behind other models in the same size neighborhood.
📡 Qwen3-Max Thinking outperforms Gemini 3 Pro and GPT-5.2 on Humanity’s Last Exam with search enabled.
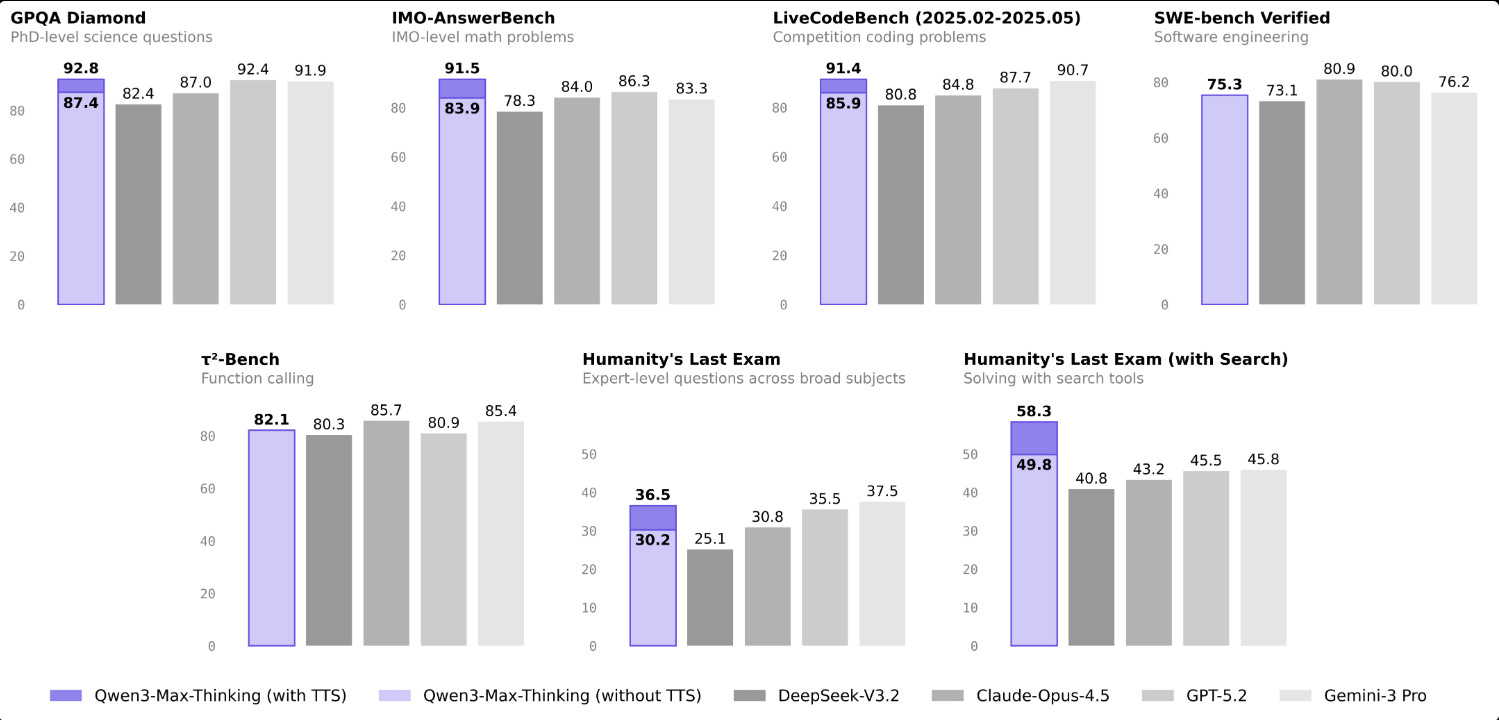
With this proprietary Qwen3-Max-Thinking, the Qwen team is trying to match, and sometimes exceed, the reasoning strength of GPT-5.2 and Gemini 3 Pro by focusing on architectural efficiency and agent-level autonomy.
Top US labs have mostly set the standard for so-called System 2 reasoning, but this performance from Qwen shows that lead is no longer that clear.
Qwen3-Max-Thinking is built on a clear break from normal inference methods.
Instead of linear token generation, it runs a “heavy mode” powered by test-time scaling, where more compute leads to better reasoning. “Heavy mode” is just the switch that tells the system to do that extra work only when the prompt looks hard, instead of paying the cost on every question.
Unlike basic best-of-N sampling, this approach builds experience across multiple rounds. Naive best-of-N sampling mostly repeats the same kind of attempt N times and then picks a winner, so it wastes compute on duplicate reasoning paths and can still miss the right approach.
It relies on a proprietary take-experience mechanism that pulls lessons from earlier reasoning steps. This lets the model spot dead ends early, without fully following a failing path, and shift compute toward unresolved uncertainties instead of repeating known conclusions.
On complex prompts, the model does not guess once and move on. It reflects, revisits earlier steps, and extracts lessons through a take-experience mechanism.
This helps it detect failing reasoning paths early and focus compute on what is still uncertain. By cutting redundant thinking, the model fits richer context into the same window.
That’s a wrap for today, see you all tomorrow.