
🐋 DeepSeek is so back with its new IMO gold-medalist model, DeepSeekMath-V2.
DeepSeekMath-V2 crushes math, NVIDIA drops Orchestrator-8B quietly, DeepMind blends film with AI reasoning, and Ilya Sutskever calls for deeper research beyond scaling.

Read time: 6 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (27-Nov-2025):
🐋 DeepSeek is so back with its new IMO gold-medalist model, DeepSeekMath-V2.
🏆 NVIDIA’s Thanksgiving is the silent drop of an Orchestrator model. nvidia/Orchestrator-8B
Google DeepMind released a new video Thinking Game Film.
🧠 OpenAI cofounder, Ilya Sutskever says scaling compute is not enough to advance AI: ‘It’s back to the age of research again’
🐋 DeepSeek is so back with its new IMO gold-medalist model, DeepSeekMath-V2.
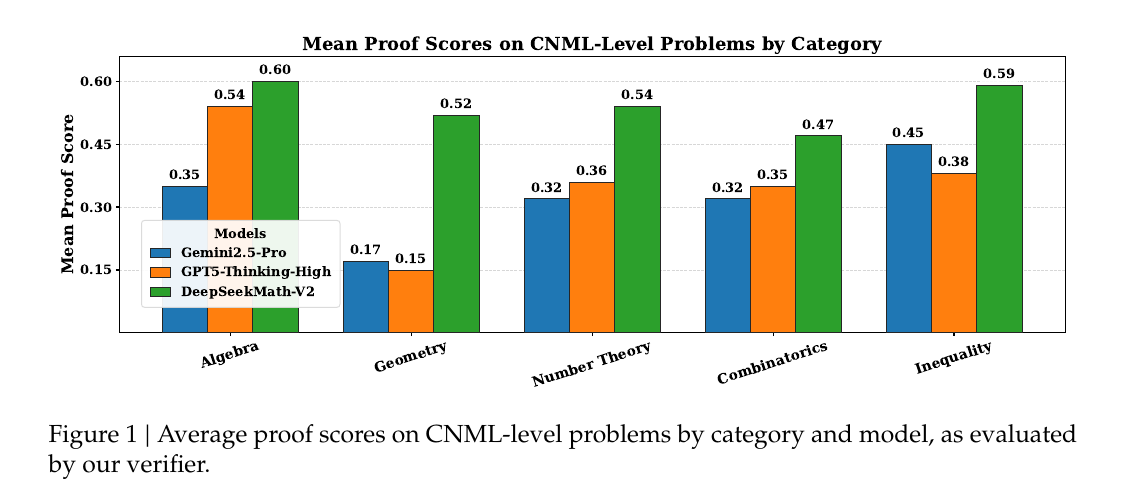
The first open source model to reach gold on IMO. Now, we can literally freely download the mind of one of the greatest mathematicians —to study, adjust, speed up, and run however you want. No limits, no censorship, no authority reclaiming it.
On the DeepSeek V2 Paper
They use 1 model to write full proofs and another model to judge whether the reasoning really holds together.
The verifier ignores just checking the final answer and instead reads the whole solution, giving 1 for rigorous, 0.5 for basically correct but messy, or 0 for fatally flawed, so training can still learn from solutions that contain the right idea even when some steps are shaky.
With this approach, DeepSeekMath V2 hits 118/120 on Putnam 2024 and gold level performance on IMO 2025 problems.
Standard math training often rewards a model only when the final number matches, so it can get credit with broken or missing reasoning.
To change that, the authors train a verifier model that reads a problem and solution, lists concrete issues, and scores the proof as 0, 0.5, or 1.
They then add a meta verifier model that judges these reviews, rewarding only cases where the cited issues appear and the score fits the grading rules.
Using these 2 reviewers as reward, the model is trained as a proof generator that solves the problem and writes a self review matching the verifier.
After many such loops, the final system can search over long competition solutions, refine them in a few rounds, and judge which of its answers deserve trust.
Overall, the system is trained from human graded contest solutions and then many rounds of model written proofs, automatic reviews, and a meta verifier that watches for bad reviewing, all running on a huge mixture of experts language model inside an agent style loop that keeps proposing, checking, and refining proofs, which the authors argue is a general template for turning chat oriented language models into careful reasoners on structured tasks beyond math.
🏆 NVIDIA’s Thanksgiving is the silent drop of an Orchestrator model. nvidia/Orchestrator-8B
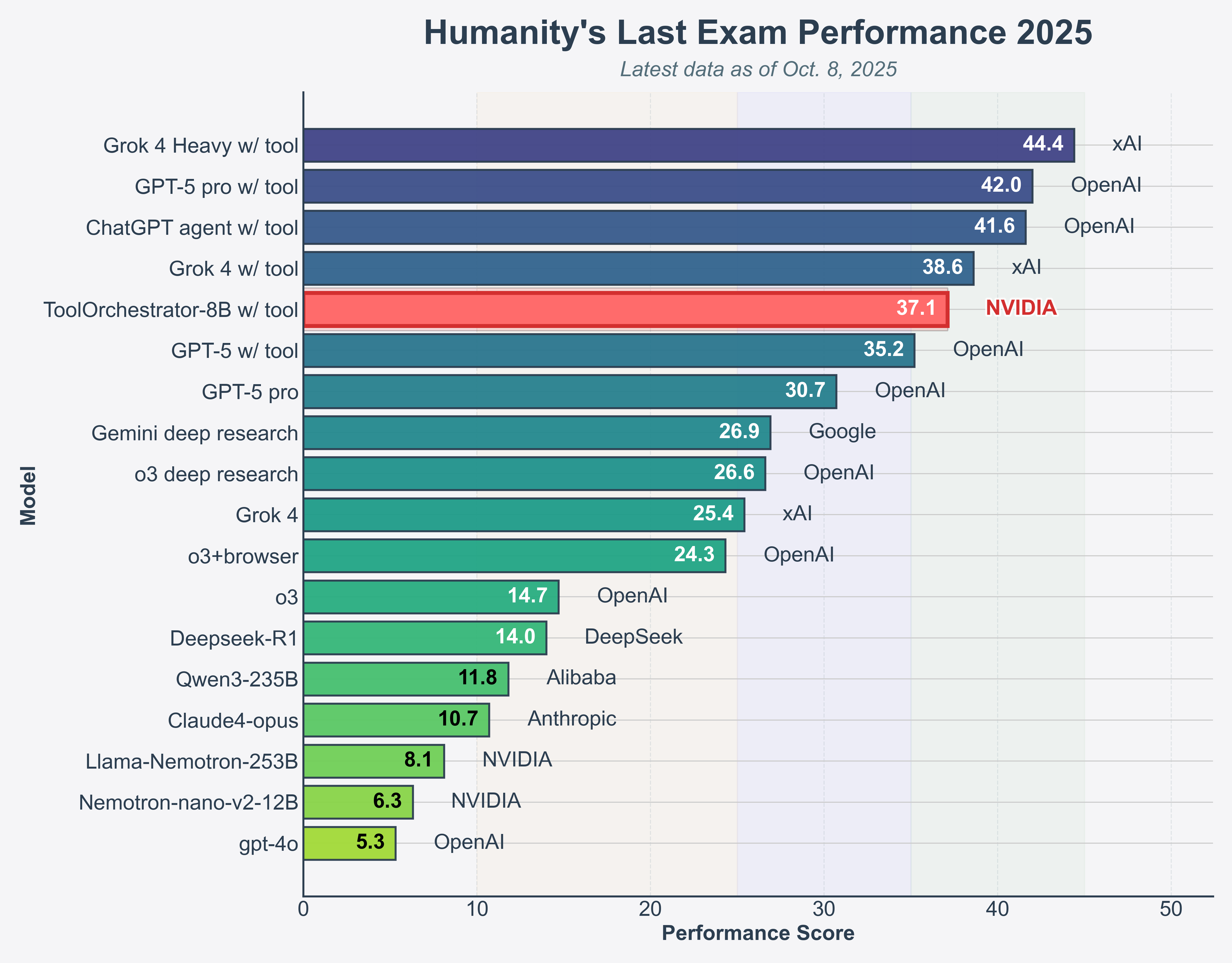
This is such a massive and silent drop by nvidia Orchestrator-8B.
“On the Humanity’s Last Exam (HLE) benchmark, ToolOrchestrator-8B achieves a score of 37.1%, outperforming GPT-5 (35.1%) while being approximately 2.5x more efficient.”
Orchestrator-8B is the router model, and ToolScale is the training playground that teaches it how to route between tools and models.
ToolScale is a big synthetic dataset full of multi-step tasks where an agent has to choose between tools like search, code, APIs, and other LLMs, see their prices and latencies, call them in some sequence, and finally produce a good answer.
Each example in ToolScale basically says “here is the user query, here are the available tools with their costs, here is a good sequence of tool calls and responses, and here is the final answer that balances quality, speed, and money.”
Instead of 1 giant LLM, Orchestrator-8B decides whether to respond itself or call tools like search, code, APIs, or other LLMs, and Group Relative Policy Optimization teaches a policy that balances accuracy, speed, cost, and user preferences.
ToolScale is a synthetic dataset where another LLM builds domain databases and tool APIs, then generates multi-turn tasks and ground-truth tool traces under many tool and pricing setups so the orchestrator learns realistic, cost-aware tool use.
On Humanity’s Last Exam, FRAMES, and tau-squared Bench, this Qwen3-8B-based orchestrator beats tool-augmented GPT-5, Claude Opus 4.1, and Qwen3-235B-A22B while calling expensive models less often, handling unseen tools and pricing schemes, and being released for research under an NVIDIA license.
So it proves that a small orchestrator sitting over a tool stack can reach frontier-level agent performance with much tighter control over compute and money than a single massive model.
Because ToolScale encodes different tool sets, different pricing schemes, and lots of realistic tool traces, Orchestrator-8B learns cost-aware, latency-aware, accuracy-aware routing instead of just “always call the biggest model.”
Google DeepMind released a new video Thinking Game Film.

Moving beyond games, the team successfully applied their AI architecture to biology with AlphaFold, which solved the 50-year-old protein folding problem and eventually released over 200 million protein structures to accelerate global medical research. The team utilized complex games like Go and StarCraft II not for entertainment, but as controlled, data-rich testing environments to train reinforcement learning agents to master intuition and strategy without pre-programmed rules.
🧠 OpenAI cofounder, Ilya Sutskever says scaling compute is not enough to advance AI: ‘It’s back to the age of research again’

Key Takeaweys from the viral interview on Dwarkesh Patel podcast with Ilya Sutskever
Ilya Sutskever believes the tides of the AI industry will have to shift back to the research phase. Big funding headlines dominate, yet daily life has not transformed at the same pace. The gap between model evals and real economic impact likely comes from RL that optimizes for benchmarks, not broad generalization. Models can ace hard tests, then miss basics like stable bug fixing. The core bottleneck is generalization, not raw scale.
Pre-training powered the last era. That recipe is hitting limits, so we are shifting from “age of scaling” to “age of research.” More compute helps, but the question is how to use compute productively, not just how to add more. Value functions that give earlier, reliable feedback can make RL far more sample efficient. Humans get this via emotions and internal signals that shape decisions continuously.
Continual learning will be central. Think less about a model that knows everything on day 1, think about a fast learner that enters the world, picks up skills on the job, and improves quickly. Broad deployment will compound learning across many instances. This can drive rapid economic growth, although the world’s physical and institutional friction will set the tempo.
Safety will hinge on incremental release, real feedback, and industry coordination. Strong alignment targets should focus on caring for sentient life, not just pleasing benchmarks. Power should be capped where possible. Expect multiple frontier AIs, specialization by domain, and market pressure that spreads capability, with meaningful differences emerging from RL choices rather than near-identical pre-training.
Forecast: human-level learning ability in models in 5-20 years. The winners will crack reliable generalization, efficient value shaping, and continual learning at scale. The right question is no longer “How big,” it is “How fast can it learn the right thing, and stay aligned while doing it?”
That’s a wrap for today, see you all tomorrow.