
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning

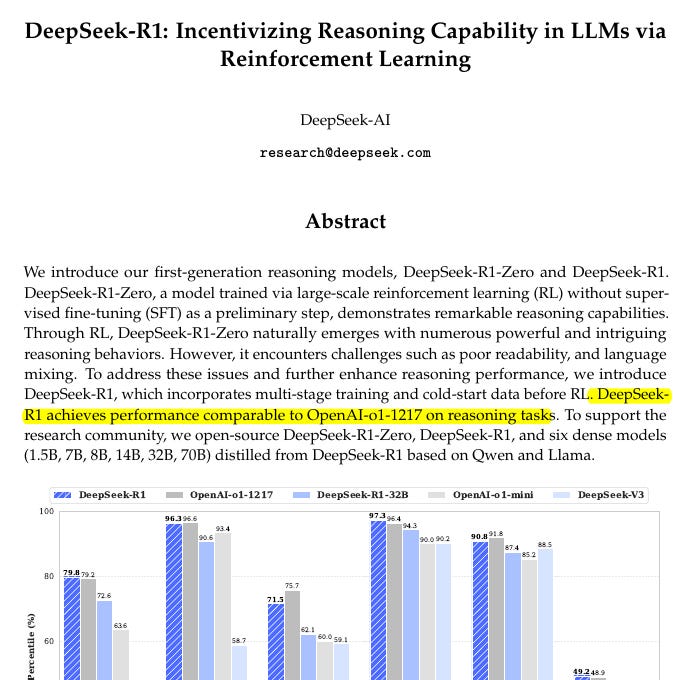
DeepSeek-R1 is here, and let me tell you, it’s not just another LLM—it’s a rule-breaking, RL-pioneering powerhouse that flips the script on traditional training. Not only did they open-source the models, but they also dropped the blueprint for their entire training pipeline.
Typically, researchers employ both process-level and outcome-level reward models, often referred to as “Process Reward Model (PRM)” and “Outcome Reward Model (ORM).” The idea is that the ORM checks the final answer for correctness while the PRM checks each step of the chain-of-thought. This method allows reinforcement learning to incorporate feedback at a more granular level, potentially refining each intermediate step. Additionally, approaches like LaTent Reasoning Optimization (LaTRO) treat the chain-of-thought as a latent variable, where the model basically learns that a correct chain-of-thought leads to a higher likelihood of producing the correct answer, reinforcing that hidden reasoning path. Another strategy is to perform supervised fine-tuning (SFT) on explicit reasoning traces, feeding the model large collections of annotated multi-step solutions.
In contrast, DeepSeek sidesteps these complexities and simply does reinforcement learning on tasks with verifiable answers (for instance, math or coding tasks that can be checked automatically), and the model learns to generate effective chain-of-thought reasoning just from that end-to-end RL setup.
Pure Reinforcement Learning: No SFT, No Problem

First things first: DeepSeek-R1-Zero, the younger sibling in this duo, skips supervised fine-tuning (SFT) entirely. This “cold start” is like throwing a rookie into the deep end of the pool and watching them become Michael Phelps. Inspired by AlphaZero, it trains purely with reinforcement learning (RL) to figure out reasoning tasks without hand-holding or human demonstrations.
Cold-Start in DeepSeek-R1-Zero
Cold-start refers to training a model without relying on Supervised Fine-Tuning (SFT) as a preliminary step. In this approach, the model begins training from its initialized state using Reinforcement Learning (RL) alone, without any prior exposure to curated datasets or human-labeled examples.
The absence of SFT means the model is not guided by pre-existing patterns or heuristics derived from human-created data. Instead, it learns reasoning capabilities entirely through interactions with an RL environment, driven by reward signals. These reward signals are designed to provide feedback on the correctness (accuracy rewards) and structural adherence (format rewards) of the model’s outputs.
The advantage of a cold-start approach is its focus on the model’s capacity to self-learn reasoning strategies from scratch, making it more adaptable to novel tasks. However, it also introduces challenges, as early RL training phases can be unstable and prone to inefficiencies without the structured guidance that SFT typically provides. To address this, rule-based rewards are used in DeepSeek-R1-Zero to ensure consistent optimization during training.
The secret sauce? Rule-based rewards. They ditched the learned reward models.

Ground-Truth Rewards in DeepSeek-R1-Zero
DeepSeek-R1-Zero avoids using learned reward models because they are prone to reward hacking, where the model exploits flaws in the reward design to maximize scores without improving actual performance. Instead, it relies on ground-truth rewards, which are based on objective, rule-based criteria.
For example, accuracy rewards verify the correctness of outputs, such as ensuring that mathematical solutions match expected results or that code successfully compiles and passes predefined test cases. Additionally, format rewards enforce adherence to a specific output structure, such as requiring intermediate reasoning steps to be enclosed within <think> tags.
By focusing on deterministic, rule-based feedback, the training process remains reliable and avoids the pitfalls of subjective or inconsistent evaluations associated with learned reward models.
GRPO: The Lean, Mean RL Machine

Say hello to Group Relative Policy Optimization (GRPO), DeepSeek’s leaner, meaner alternative to Proximal Policy Optimization (PPO).
Group Relative Policy Optimization (GRPO) is a reinforcement learning algorithm that enhances the reasoning capabilities of LLMs. Instead of relying on a value function model, GRPO compares groups of answers to determine how to improve the model's performance .
GRPO is basically PPO on a diet—it gets rid of the critic network entirely and replaces it with Monte Carlo estimates of rewards from multiple sampled outputs. For every question, the model generates a batch of responses, calculates their rewards, and uses the group’s average to normalize the optimization process. No value function means less memory hogging and simpler implementation.
Why does this matter? Because LLMs and value functions go together like oil and water. Traditional RL methods struggle with the non-deterministic chaos of language generation. GRPO sidesteps that mess and keeps the focus sharp on the actual rewards.
How GRPO Works in DeepSeek-R1

DeepSeek-R1 utilizes a multi-stage training approach that includes a "cold-start" phase with curated data and reinforcement learning . In the cold-start phase, the model is fine-tuned on a small dataset of structured Chain-of-Thought (CoT) examples to establish a stable initialization . This is followed by the application of GRPO to unsupervised text generation tasks that require reasoning without explicit human guidance. The training process uses rule-based reward models that focus on different aspects of the model's output:

Accuracy rewards: These evaluate whether the response is correct, for example, by checking if a math solution is accurate or if a LeetCode problem compiles successfully .
Format rewards: These assess the format of the response, encouraging the model to present its reasoning process in a clear and structured manner .
By using GRPO with these reward models, DeepSeek-R1 learns to generate responses that are not only accurate but also well-organized and easy to understand. Interestingly, during the training process, DeepSeek-R1 exhibited "emergent properties" such as self-reflection and exploration behaviors . These properties suggest that GRPO can lead to the development of more sophisticated and autonomous reasoning capabilities in LLMs.
Emergence of self-reflection and exploration behaviors: When RL Gets Funky
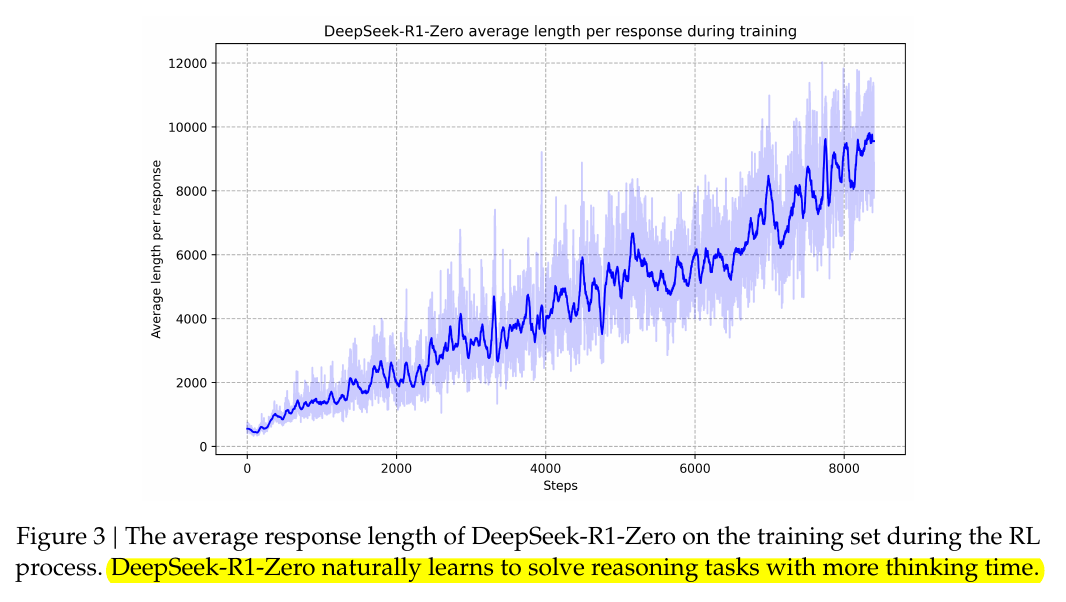
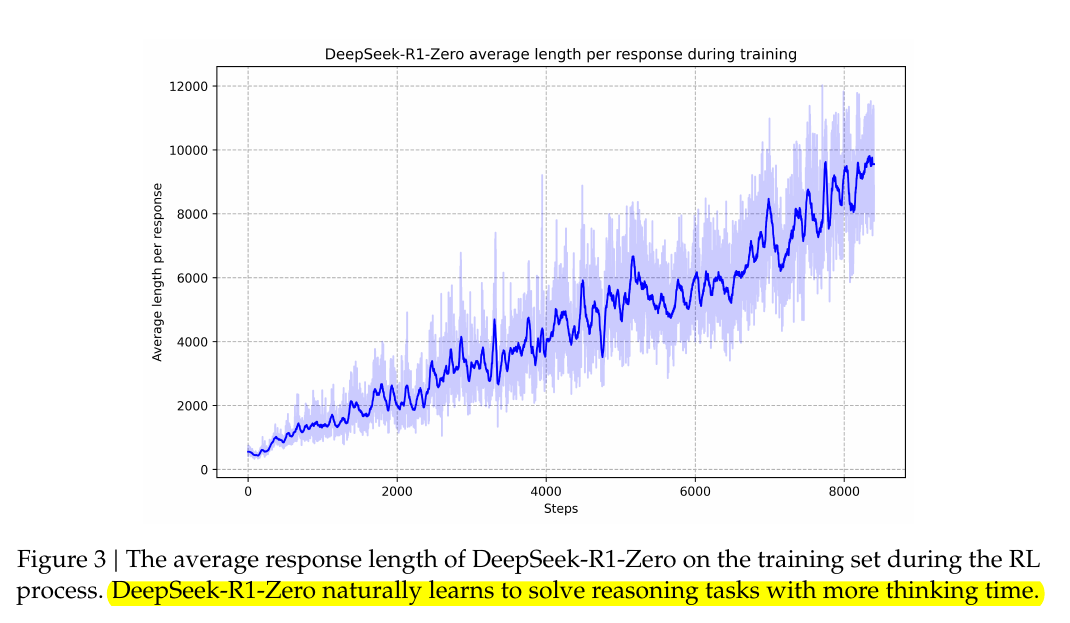
Emergent behaviors in DeepSeek-R1-Zero are driven by the model’s direct interactions with a reward-based environment. When it attempts to solve math or coding tasks, it receives a reward if it reaches a correct answer. Early in training, it often guesses short reasoning paths. But as it notices that deeper, more carefully reasoned outputs yield higher rewards, the policy gradient nudges it to expand its chain-of-thought.
Inside the network, these long outputs become self-reinforcing: once a few extended solutions happen to succeed, their higher reward signals cause the next policy update to favor even more thorough attempts. This chain reaction makes the model systematically allocate more tokens to “thinking time,” and it also refines its text by revisiting and correcting errors. Because no one instructs it on how or when to backtrack, that self-reflective behavior emerges purely from reward maximization.

Behind the scenes, Group Relative Policy Optimization (GRPO) further amplifies this effect. By sampling multiple outputs and comparing their rewards, the training algorithm increases the probability of any longer chain-of-thought that produces the right solution. Over thousands of training steps, those patterns compound until “aha moments” and more elaborate reasoning approaches appear on their own. This intrinsic adaptation does not come from explicit instructions; it arises naturally from the structural dynamics of reinforcement learning.
DeepSeek-R1: From Chaos to Clarity

Here’s where DeepSeek-R1 steps in to clean up the chaos. The problem with DeepSeek-R1-Zero? It’s a little rough around the edges—outputs could be messy, readability wasn’t great, and it loved to mix languages like a multilingual DJ. To fix this, the DeepSeek team kicked off training with a cold start phase using curated long Chain-of-Thought (CoT) examples. These examples act as a stabilizer, giving the model a more structured foundation before diving into full-scale RL.
Once the cold start is out of the way, DeepSeek-R1 goes back to its RL roots, but with a few extra tricks. One of them is a language consistency reward to penalize those multilingual mashups. Sure, this might ding performance slightly, but it aligns better with what humans actually want—coherent, readable reasoning.
After RL, the team ran rejection sampling on the outputs to curate a dataset of high-quality reasoning trajectories. They then fine-tuned the model on this dataset, iterating back and forth between RL and supervised fine-tuning. It’s like training a Jedi: trial by fire, reflection, and refinement until it’s ready to face the galaxy.
Distillation: Big Brains in Small Packages
And that is how,"DeepSeek-R1-Distill-Qwen-1.5B outperforms GPT-4o and Claude-3.5-Sonnet on math benchmarks with 28.9% on AIME and 83.9% on MATH"

Deepseek also dropped 6 distilled versions of R1 on Huggingface.
DeepSeek-R1, DeepSeek-R1-Zero, and their distilled models, based on Llama and Qwen architectures

So, this is where’s the kicker: DeepSeek-R1 didn’t stop with the flagship models. They distilled all that reasoning prowess into smaller, more efficient versions like Qwen and Llama. These compact models inherit the reasoning chops of their larger counterparts without needing the RL-heavy training process. For instance, the distilled DeepSeek-R1-Qwen-7B punches well above its weight class, outperforming much larger models like GPT-4o on math and coding benchmarks.
Distillation in this context involves using a larger, more capable model (the full Deepseek-R1 in this case) to train smaller models by transferring knowledge. This is done by feeding the smaller models the larger model's logit distributions (token probabilities) instead of just the final answers. The smaller models learn not only the correct output but also the nuanced token-by-token probabilities, enhancing their reasoning and generalization capabilities.
Unlike traditional fine-tuning, distillation includes a focus on how each token's likelihood distribution is adjusted by the teacher model. For example, if the teacher generates "I like to walk my [dog]," it provides a probability distribution over every possible next word (not just "dog").
→ Distillation techniques applied to DeepSeek-R1 generated smaller dense models, from 1.5B to 70B parameters. The DeepSeek-R1-Distill-Qwen-32B is straight SOTA, delivering more than GPT4o-level performance, showcasing that smaller models can achieve exceptional reasoning capabilities when derived from larger, well-trained models.
What’s fascinating is how distillation sometimes beats RL when applied directly to smaller models. Instead of burning compute on massive RL pipelines, you let the big model do the heavy lifting and then shrink-wrap its insights into a smaller, faster package. It’s like turning a NASA supercomputer into a pocket calculator that still solves rocket equations.
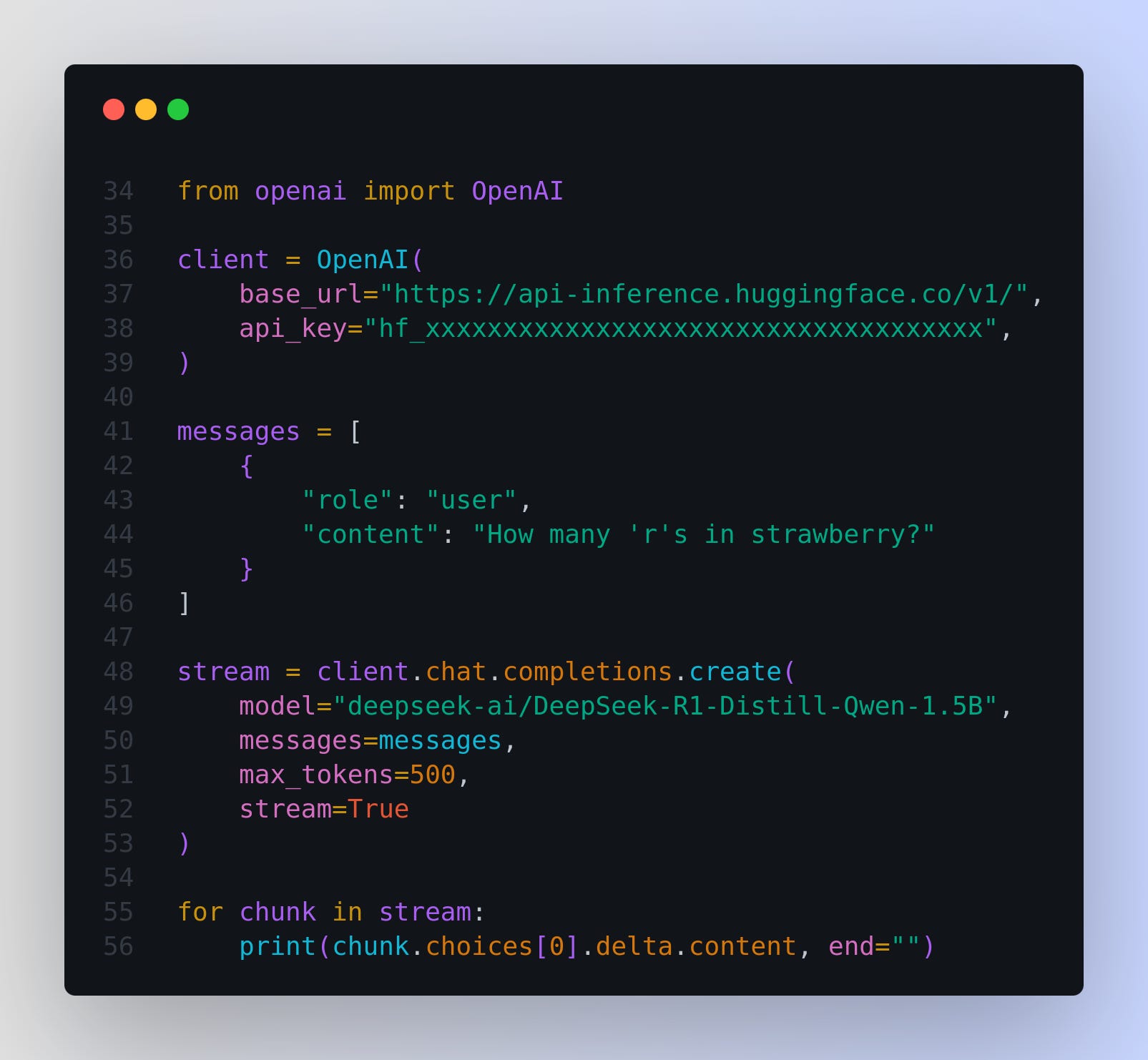
You can eazily run DeepSeek R1 distillation of Qwen 1.5B with this script.
First install `pip3 install -U openai`
I like the authors’ transparency about certain methods that did not work in their attempts.
They explain that using Monte Carlo Tree Search (MCTS)—inspired by game-playing algorithms like AlphaGo—did not scale effectively to open-ended text generation because the branching factor is too large, and the system quickly becomes unwieldy.

The very interesting thing about the paper is it demonstrates that a surprisingly small setup can achieve dramatic gains in accuracy on tasks like the AIME math competition, where a model might jump from near-random (e.g., 0.2%) to around 85% accuracy just by direct RL with a verifiable check. The authors do not feed any teacher solutions or reference reasoning steps, so the model discovers longer chain-of-thought because doing so earns higher reward. This direct feedback loop allows the base model to develop deeper reasoning without having its distributions or style drastically changed by supervised fine-tuning in an intermediate stage.
The Bigger Picture
By proving that pure RL can cultivate reasoning, they’ve opened up a whole new world of possibilities. GRPO, emergent behaviors, cold starts, and distillation—it’s a masterclass in innovation.
All well and good, the only thing I find suspicious is R1 identifies as o1 when prompted for its identity. Whereas in their entire paper there is not a whiff of o1. Also suspicious is the fact that in all the benchmarks it scores precisely the same numbers as o1 or less. If it was truly independent then why this exact matching, why not for instance, scores closer to o3, or even otherwise, why not more varied scores that do not match those of o1? Also, why does it repeat the same jokes as o1?