
🧩 Deepseek Releases Open-Source Reasoning Model Matching Openai-O1, And Outperforming Gpt-4o
DeepSeek's new reasoning model rivals GPT-4o, OpenAI hints at PhD-level super-agents, viral GPT-2 training hack, and Runway's cinematic Frames with 19 styles.

Read time: 7 min 19 seconds
⚡In today’s Edition (20-Jan-2025):
🧩 Deepseek Releases Open-Source Reasoning Model Matching Openai-O1, And Outperforming Gpt-4o
🏆 OpenAI May Launch AI Super-Agents With PhD-Level Intelligence Soon
📡 Google Launched Vertex Ai Rag Engine
🗞️ Byte-Size Brief:
Viral post shows GPT-2 training in 3 minutes, $0.40.
Runway unveils Frames for cinematic visuals, 19 style presets.
🧩 Deepseek Releases Open-Source Reasoning Model Matching Openai-O1, And Outperforming Gpt-4o

🎯 The Brief
DeepSeek has launched DeepSeek-R1, an open-source AI model that rivals OpenAI-o1 in math, code, and reasoning tasks. It features MIT licensing for unrestricted use and commercialization, accompanied by highly competitive API pricing. Smaller distilled models outperform GPT-4o and Claude-3.5-Sonnet in specific benchmarks. API outputs can now be used for fine-tuning & distillation.
⚙️ The Details
→ DeepSeek-R1 is designed to match OpenAI-o1 in reasoning benchmarks, achieving 97.3% on MATH-500 and 79.8% on AIME 2024. It utilizes a multi-stage training process, including reinforcement learning and supervised fine-tuning, to improve reasoning and alignment capabilities.
→ The model is fully open-source under the MIT license, enabling free modification, use, and commercialization. Six distilled versions ranging from 1.5B to 70B parameters were also released.
→ 🌐 API Access & Pricing
⚙️ Use DeepSeek-R1 by setting model=deepseek-reasoner
💰 $0.14 / million input tokens (cache hit)
💰 $0.55 / million input tokens (cache miss)
💰 $2.19 / million output tokens

Compare this OpenAI API Pricing

So, DeepSeek-R1 emerges as the more affordable option, $2.19 per million output tokens, while OpenAI's o1 costs $60.
Architecture Key Points
Pure RL Training ("Cold Start"):
The model starts training purely through Reinforcement Learning (RL) without any Supervised Fine-Tuning (SFT). This is comparable to AlphaZero's approach in board games where learning happens from scratch without human guidance.
"cold start" refers to the practice of initiating training purely with Reinforcement Learning (RL), without any pre-training or Supervised Fine-Tuning (SFT) on human-labeled data.
Rule-Based Rewards:
Rewards are based on hardcoded rules (e.g., correctness in math or code tasks), avoiding the use of neural reward models which can be prone to exploitation by the RL system.
Emergent Thinking Behavior:
The model naturally increases its thinking time as training progresses. This isn't manually programmed but is an emergent feature of the training process.
Emergence of Complex Behaviors:
The model develops capabilities for self-reflection and exploratory reasoning during training, demonstrating advanced problem-solving strategies.
GRPO (Group Relative Policy Optimization):
A streamlined alternative to PPO (Proximal Policy Optimization). GRPO eliminates the need for a separate critic model and uses averaged rewards from sampled outputs. This reduces memory overhead and simplifies the RL process. GRPO was introduced by the same team earlier in 2024.
Deepseek also dropped 6 distilled versions of R1 on Huggingface.
DeepSeek-R1, DeepSeek-R1-Zero, and their distilled models, based on Llama and Qwen architectures
i.e. DeepSeek uses the outputs of their high-performing R1 model to fine-tune smaller, open-source models (like Qwen-32B or LLaMA variants).

Distillation in this context involves using a larger, more capable model (the full Deepseek-R1 in this case) to train smaller models by transferring knowledge. This is done by feeding the smaller models the larger model's logit distributions (token probabilities) instead of just the final answers. The smaller models learn not only the correct output but also the nuanced token-by-token probabilities, enhancing their reasoning and generalization capabilities.
Unlike traditional fine-tuning, distillation includes a focus on how each token's likelihood distribution is adjusted by the teacher model. For example, if the teacher generates "I like to walk my [dog]," it provides a probability distribution over every possible next word (not just "dog").
→ Distillation techniques applied to DeepSeek-R1 generated smaller dense models, from 1.5B to 70B parameters. The DeepSeek-R1-Distill-Qwen-32B is straight SOTA, delivering more than GPT4o-level performance, showcasing that smaller models can achieve exceptional reasoning capabilities when derived from larger, well-trained models.
→ DeepSeek-R1-Zero was developed without supervised fine-tuning (SFT), relying solely on large-scale RL. And, DeepSeek-R1 incorporates SFT in the early stages before RL. This enhancement ensures better alignment with human preferences and significantly improves performance across math, coding, and reasoning tasks.
You can chat with DeepSeek-R1 on DeepSeek's official website: chat.deepseek.com, and switch on the button "DeepThink"
How did DeepSeek enhance the Transformer architecture?
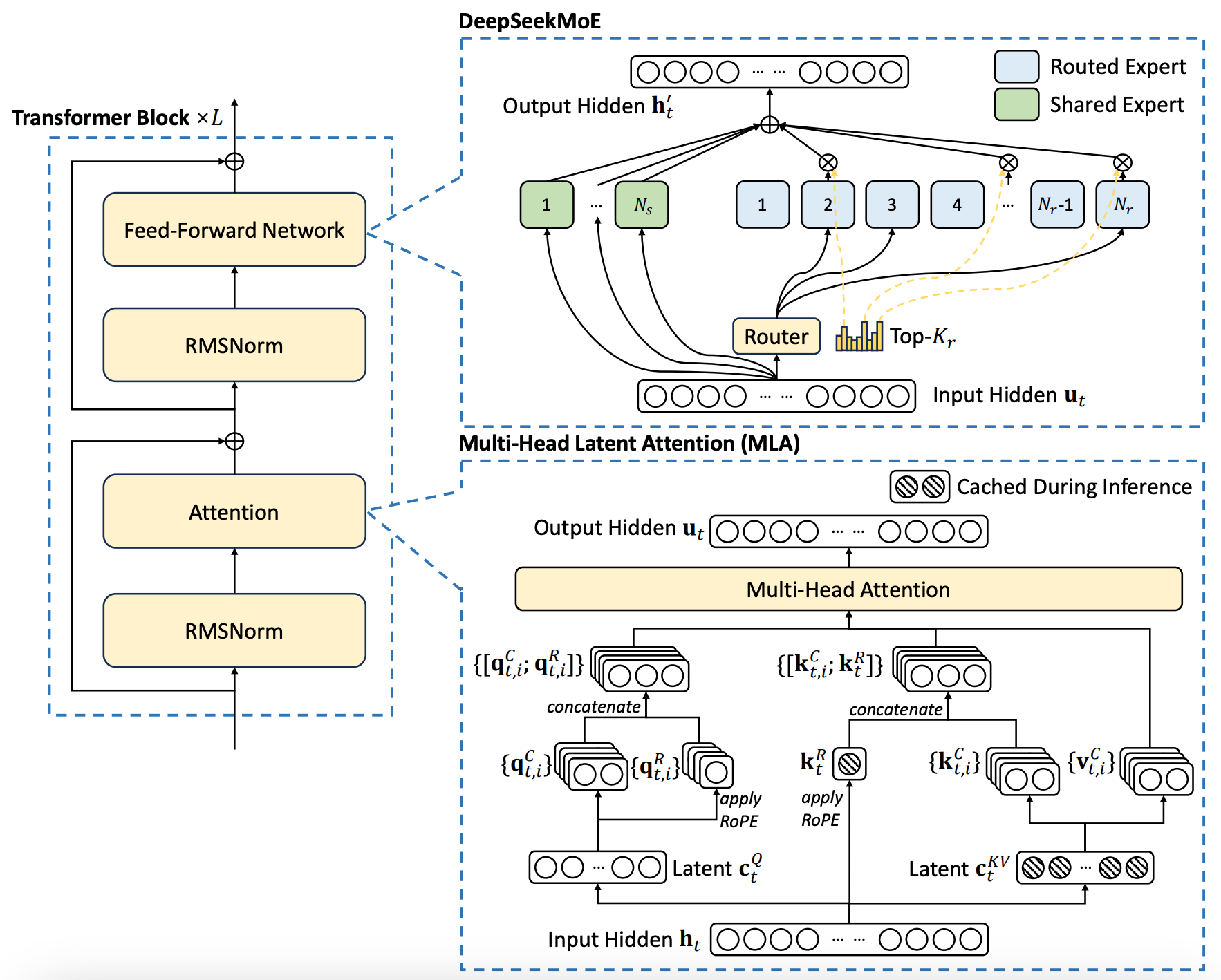
Among all of the open source AI labs, DeepSeek has perhaps made the most architectural improvements to the standard decoder-only Transformer.
The 3 key innovations are Multi-Head Latent Attention (MLA) and Mixture-of-Experts (MoE) and and Multi-Token prediction.
Multi-Head Latent Attention (MLA): It reduces KV cache size without quality loss by compressing key-value vectors into latent representations and reconstructing them efficiently during inference. This approach surpasses grouped-query attention by enabling effective information sharing across attention heads.
Mixture-of-Experts (MoE) Enhancements: Innovations include auxiliary-loss-free load balancing to prevent routing collapse, expert-specific bias adjustments for dynamic load balancing, and separation of shared and routed experts to optimize resource allocation while avoiding redundant routing constraints.
Multi-Token Prediction: DeepSeek predicts multiple tokens per forward pass, improving training efficiency and enabling speculative decoding. This achieves near double inference speed while maintaining high acceptance rates for predicted tokens.
When using deepseek-reasoner, please upgrade the OpenAI SDK first to support the new parameters.
pip3 install -U openai
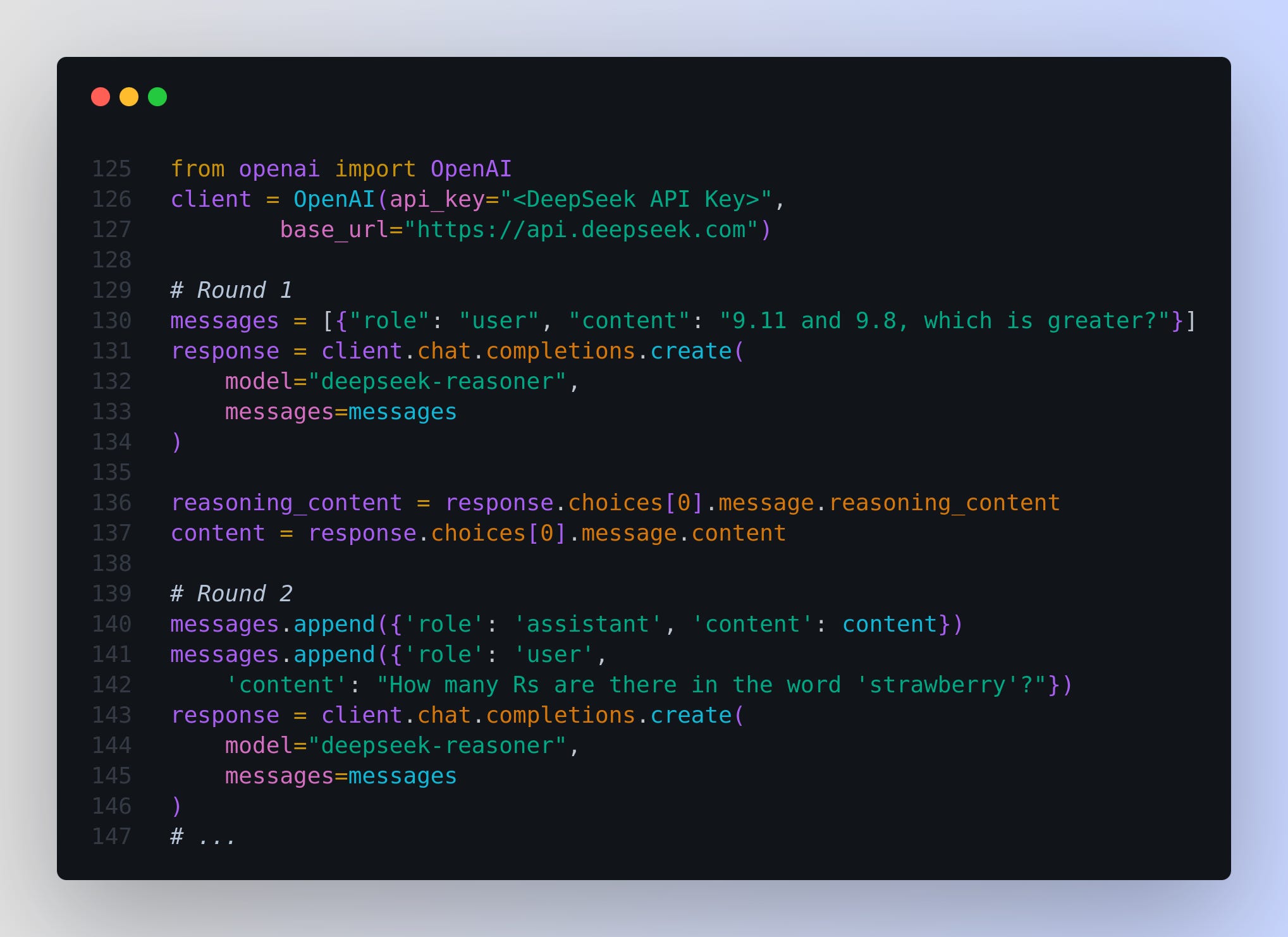
Before delivering the final answer, the model first generates a Chain of Thought (CoT) to enhance the accuracy of its responses. If the reasoning_content field is included in the sequence of input messages, the API will return a 400 error. Therefore, you should remove the reasoning_content field from the API response before making the API request.
🏆 OpenAI May Launch AI Super-Agents With PhD-Level Intelligence Soon

🎯 The Brief
OpenAI, is set to announce PhD-level AI super-agents capable of performing complex human tasks with precision, speed, and creativity, according to a report. A closed-door briefing with U.S. government officials on this advancement is scheduled. However, he also tweeted saying “we are not gonna deploy AGI next month, nor have we built it.”
⚙️ The Details
→ OpenAI is reportedly preparing to unveil AI super-agents that can handle multilayered tasks, such as designing software, conducting financial analyses, or managing logistics, at a level comparable to PhD professionals.
→ CEO Sam Altman has scheduled a private briefing with U.S. officials. This comes amid discussions about AI's ability to revolutionize industries, as noted by Meta's Mark Zuckerberg, who envisions AI replacing mid-level engineers in 2025.
→ OpenAI recently published an "Economic Blueprint" emphasizing AI's potential to drive U.S. reindustrialization through infrastructure investments and productivity growth. Experts believe these advancements could transform health, science, and education through unprecedented research capabilities.
→ Critics warn about job displacement risks, particularly for entry- and mid-level roles.
📡 Google Launched Vertex Ai Rag Engine
🎯 The Brief
Google launched the Vertex AI RAG Engine, a managed orchestration service designed to enhance generative AI applications by integrating external data sources with LLMs.
⚙️ The Details
→ The Vertex AI RAG Engine leverages Retrieval-Augmented Generation (RAG) to retrieve external, up-to-date information, ensuring LLMs generate grounded and contextually relevant responses.
→ Developers can customize components like data parsing, chunking, embedding, and annotations or integrate their existing tools and frameworks. It supports popular vector databases such as Pinecone and Weaviate, along with Vertex AI’s own vector search.
→ Google provides three RAG solutions: Vertex AI Search (for fully managed enterprise-grade search), DIY RAG (for maximum flexibility), and Vertex AI RAG Engine, which balances ease of use with customization.
→ Key use cases span finance, offering personalized investment advice, healthcare, accelerating drug discovery, and legal, streamlining contract reviews and due diligence.
→ Google offers extensive resources, including GitHub notebooks, detailed documentation, and integration examples, to support developers in quickly adopting the Vertex AI RAG Engine for grounded generative AI applications.
🗞️ Byte-Size Brief
Training a GPT-2-level model now costs $0.40 and takes under 3 minutes on 8 H100 GPUs. A post went viral on X explaining the entire process. Using long-short sliding window attention, context length warming, and other optimizations, this method cuts training times while keeping validation loss manageable with minimal cost increase.
Runway’s new its newest text-to-image generation model, Frames, generates cinematic-quality visuals with stylistic precision, aiming to redefine creative workflows for artists and filmmakers. With 19 preset styles and customizable designs, Frames combines creativity with consistency, ideal for editorial, branding, and film production tasks.