DIRECT JUDGEMENT PREFERENCE OPTIMIZATION
DPO-trained Generative judge (DJPO) achieves the best performance on 10 out of 13 benchmarks, outperforming strong baselines like GPT-4o and specialized judge models.


DPO-trained Generative judge (DJPO) achieves the best performance on 10 out of 13 benchmarks, outperforming strong baselines like GPT-4o and specialized judge models.
DJPO creates versatile LLM judges excelling in single rating, pairwise comparison, and classification tasks.
Original Problem🔍:
LLM judges trained via supervised fine-tuning (SFT) lack exposure to incorrect judgements, limiting their evaluation capabilities.
Solution in this Paper🛠️:
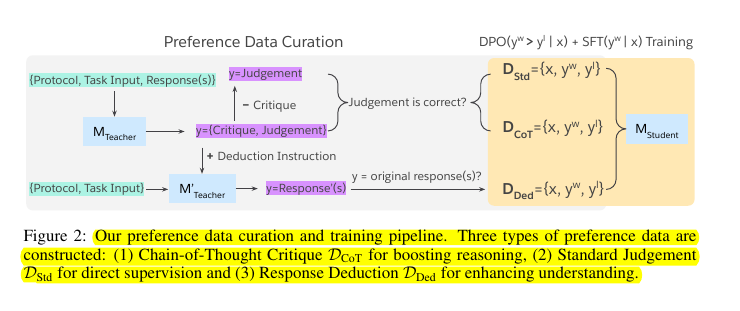
• Employed three approaches to collect preference pairs:
Chain-of-Thought Critique: Enhances reasoning capability
Standard Judgement: Provides direct supervision for correct judgements
Response Deduction: Improves understanding of good/bad responses
• Used DPO + SFT loss for training generative judges
• Created SFR-Judges in three sizes: 8B, 12B, and 70B parameters
Key Insights from this Paper💡:
• Learning from both positive and negative evaluations improves judge performance
• Pairwise preference format enables flexible training data curation
• Combining CoT critiques with standard judgements balances reasoning and direct supervision
Results📊:
• SFR-Judges achieved best performance on 10/13 benchmarks
• 70B model reached 92.7% accuracy on RewardBench, outperforming other generative judges
• Demonstrated lower bias compared to other models on EvalBiasBench
• Showed high consistency in pairwise comparisons
• Improved downstream model performance when used as a reward model
🧠 The proposed method differs from previous approaches to training LLM judges in several key ways:
Use of preference optimization: Unlike previous methods that rely solely on supervised fine-tuning (SFT), this approach uses direct preference optimization (DPO) to learn from both positive and negative examples. This allows the model to learn what constitutes both good and bad judgements.
Multiple training tasks: The method incorporates three distinct training tasks (Chain-of-Thought Critique, Standard Judgement, and Response Deduction) to target different aspects of evaluation capability.
Flexible data curation: The pairwise preference format enables a flexible approach to curating training data, allowing for inclusion of both detailed critiques and direct judgements.
Focus on generative judges: While many previous approaches focused on classifier-based judges, this method trains generative judges capable of providing both numerical scores and free-text critiques.