DiscoveryBench: Towards Data-Driven Discovery with Large Language Models
DISCOVERYBENCH shows current LLMs solve only 25% of scientific discovery tasks


DISCOVERYBENCH shows current LLMs solve only 25% of scientific discovery tasks
Original Problem 🔍:
Data-driven discovery automation using LLMs remains unexplored. Current benchmarks lack comprehensive evaluation of hypothesis search and verification capabilities across diverse domains.
Solution in this Paper 🧠:
• DISCOVERYBENCH: A benchmark with 264 real-world and 903 synthetic discovery tasks
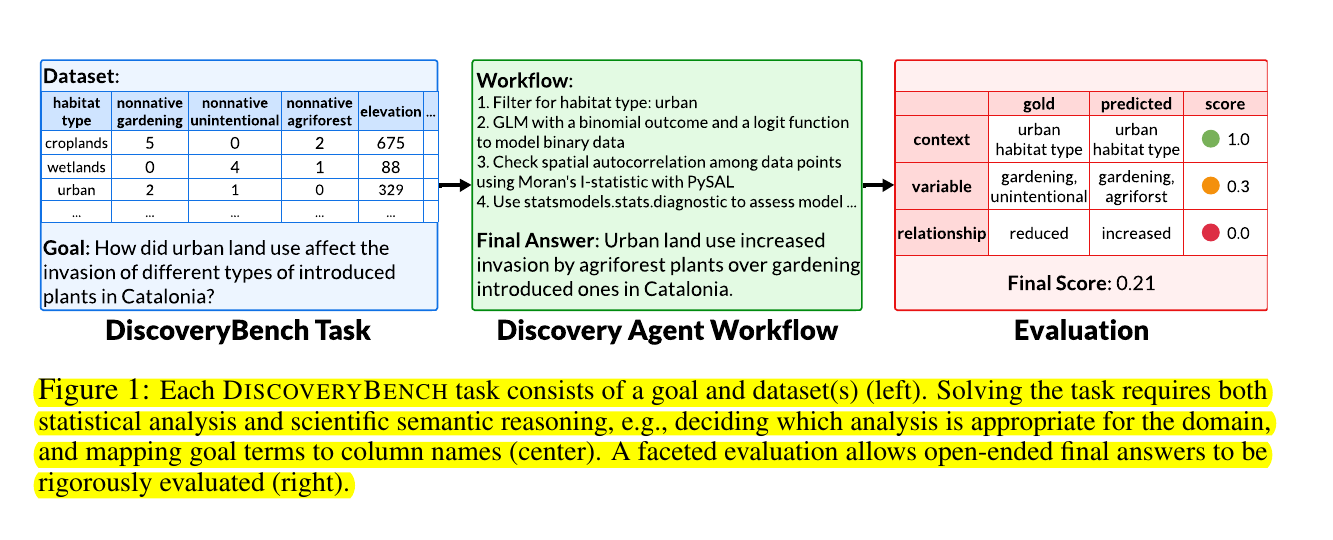
• Structured formalism for data-driven hypotheses using contexts, variables, and relationships
• Hypothesis Semantic Tree concept to represent complex hypotheses hierarchically
• Facet-based evaluation methodology using GPT-4 for rigorous assessment
Key Insights from this Paper 💡:
• LLMs struggle with complex statistical techniques and domain-specific models
• Context identification is crucial for accurate variable and relationship prediction
• Performance decreases as workflow length and task complexity increase
• Additional domain knowledge can significantly improve discovery performance
Results 📊:
• Best system scores only 25% on DISCOVERYBENCH
• Performance peaks at 25% for DB-REAL and 23.2% for DB-SYNTH
• Reflexion (Oracle) agent shows best results across different LLMs
• Economics (25%) and sociology (23%) tasks perform better than biology (0%) and engineering (7%)
🧠 DISCOVERYBENCH consists of two main components:
DB-REAL: This component contains 264 tasks collected across 6 diverse domains (sociology, biology, humanities, economics, engineering, and meta-science). These tasks were manually derived from published papers to approximate real-world challenges faced by researchers.
DB-SYNTH: This component provides 903 synthetic tasks across 48 domains, generated using LLMs to mimic the real-world discovery process. It allows for controlled model evaluations by varying task difficulty.
Each task in DISCOVERYBENCH is defined by a dataset, its metadata, and a discovery goal in natural language. The benchmark uses a structured formalism of data-driven discovery that enables a facet-based evaluation, providing insights into different failure modes.