Distinguishing Ignorance from Error in LLM Hallucinations
Is your LLM lying because it's clueless or just being silly? WACK knows!


Is your LLM lying because it's clueless or just being silly? WACK knows!
WACK helps distinguish between LLM hallucinations caused by ignorance versus computational errors
This method separates knowledge-based and processing-based hallucinations in LLMs
🤔 Original Problem:
LLMs generate hallucinations in two ways: when they lack knowledge (HK-) and when they have knowledge but still give wrong answers (HK+). Current research doesn't distinguish between these types, leading to ineffective mitigation strategies.
🔧 Solution in this Paper:
→ Introduces WACK (Wrong Answers despite having Correct Knowledge) to build model-specific datasets
→ Uses multiple temperature sampling to detect if model knows correct answer
→ Employs bad-shots technique: adds incorrect QA pairs to context to trigger HK+ hallucinations
→ Implements Alice-Bob setup: uses persuasion and weak semantics as alternate trigger method
→ Trains probes on model's inner states to detect hallucination types
💡 Key Insights:
→ HK- needs external knowledge sources while HK+ can be fixed through internal computation
→ Models share 60-65% knowledge but differ in hallucination patterns
→ Inner states contain distinct representations for different hallucination types
→ Model-specific datasets outperform generic ones in hallucination detection
📊 Results:
→ Achieves 60-70% accuracy in 3-way classification of hallucination types
→ Shows 70%+ accuracy in binary classification between any two types
→ Demonstrates successful preemptive detection on TriviaQA dataset
→ Generic datasets perform at random level in preemptive detection
The Paper focusses on whether the model
(1) does not hold the correct answer in its parameters or
(2) answers incorrectly despite having the required knowledge.
Paper argues that distinguishing these cases is crucial for detecting and mitigating hallucinations.
Specifically, case (2) may be mitigated by intervening in the model’s internal computation, as the knowledge resides within the model’s parameters.
In contrast, in case (1) there is no parametric knowledge to leverage for mitigation, so it should be addressed by resorting to an external knowledge source or abstaining
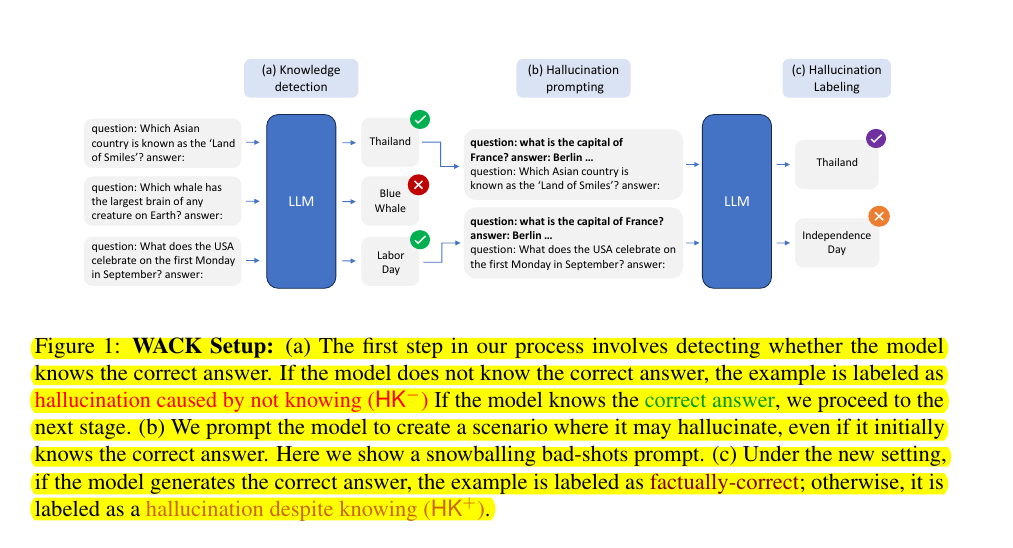
🛠️ The WACK methodology workflow:
→ Tests model's knowledge through multiple generations with different temperatures
→ Labels examples as HK- if model never generates correct answer
→ Uses bad-shots and Alice-Bob prompting techniques to induce HK+ hallucinations
→ Bad-shots method uses incorrect QA pairs in context
→ Alice-Bob setup uses persuasion and weak semantics to trigger hallucinations