
Duo-LLM: A Framework for Studying Adaptive Computation in Large Language Models
Think fast lanes and slow lanes, but for AI brain cells 💡


Think fast lanes and slow lanes, but for AI brain cells 💡
LLMs can now selectively route tokens through big or small neural pathways based on complexity.
Saves compute by sending easy tokens through simpler paths.
Nice Paper from Apple.
Original Problem 🎯:
LLMs use fixed compute for all tokens regardless of complexity, leading to inefficient resource usage. Current adaptive methods like MoE and speculative decoding lack optimal routing patterns.
Solution in this Paper 🔧:
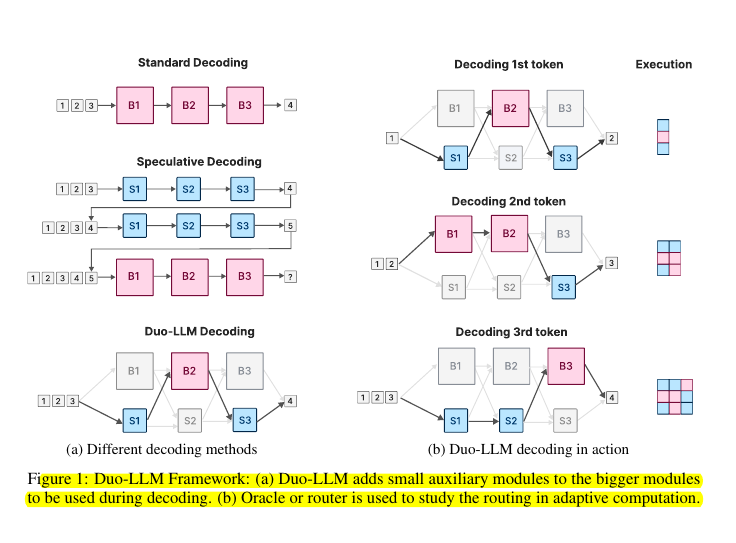
• Introduces Duo-LLM framework with small auxiliary modules in each FFN layer
• Three-stage methodology:
Train LLM with random routing between big/small FFN modules
Use oracles to find optimal routing patterns
Train practical routers to compare against oracle patterns
• Enables tokens to route through small/big modules or skip layers entirely
• Introduces concept of token difficulty based on potential for loss reduction
Key Insights 💡:
• Using one big layer strategically can outperform using big layers throughout
• Later layers need capacity threshold for optimal performance
• Token difficulty is context-dependent - some high-loss tokens don't improve with more compute
• Trained routers perform closer to random trials than oracle patterns
• Layer skipping patterns don't follow simple early-exit strategies
Results 📊:
• Oracle achieves significantly lower perplexity than random routing
• Optimal routing with 6 big layers outperforms using all 12 big layers
• Router performance aligns with best of 100 random trials rather than oracle
• Early tokens utilize big modules more, while later tokens need less compute
Neural traffic control: express lanes for complex thoughts, local roads for simple ones.
🎓 The key findings about optimal routing patterns
Using just one big layer strategically can outperform using big layers throughout
Later layers need a certain capacity threshold for optimal performance
Once threshold is met, earlier layers benefit from additional compute
When layers skip early in a sequence, they tend to benefit from further skipping later.
💡 The concept of Token difficulty is relative and context-dependent.
Some high-loss tokens don't improve with more compute due to inherent uncertainty. The potential for loss reduction, rather than just token difficulty, should guide adaptive routing.
🤖 The gap between practical routers and theoretical optimum
Trained routers perform closer to random trials than oracle patterns. They fail to discover complex patterns identified by oracles, suggesting room for improvement in routing mechanisms.