
during QLORA training, why the the “lm_head” is not quantized


📌 Understanding the Non-Quantization of "lm_head" in QLoRA Training
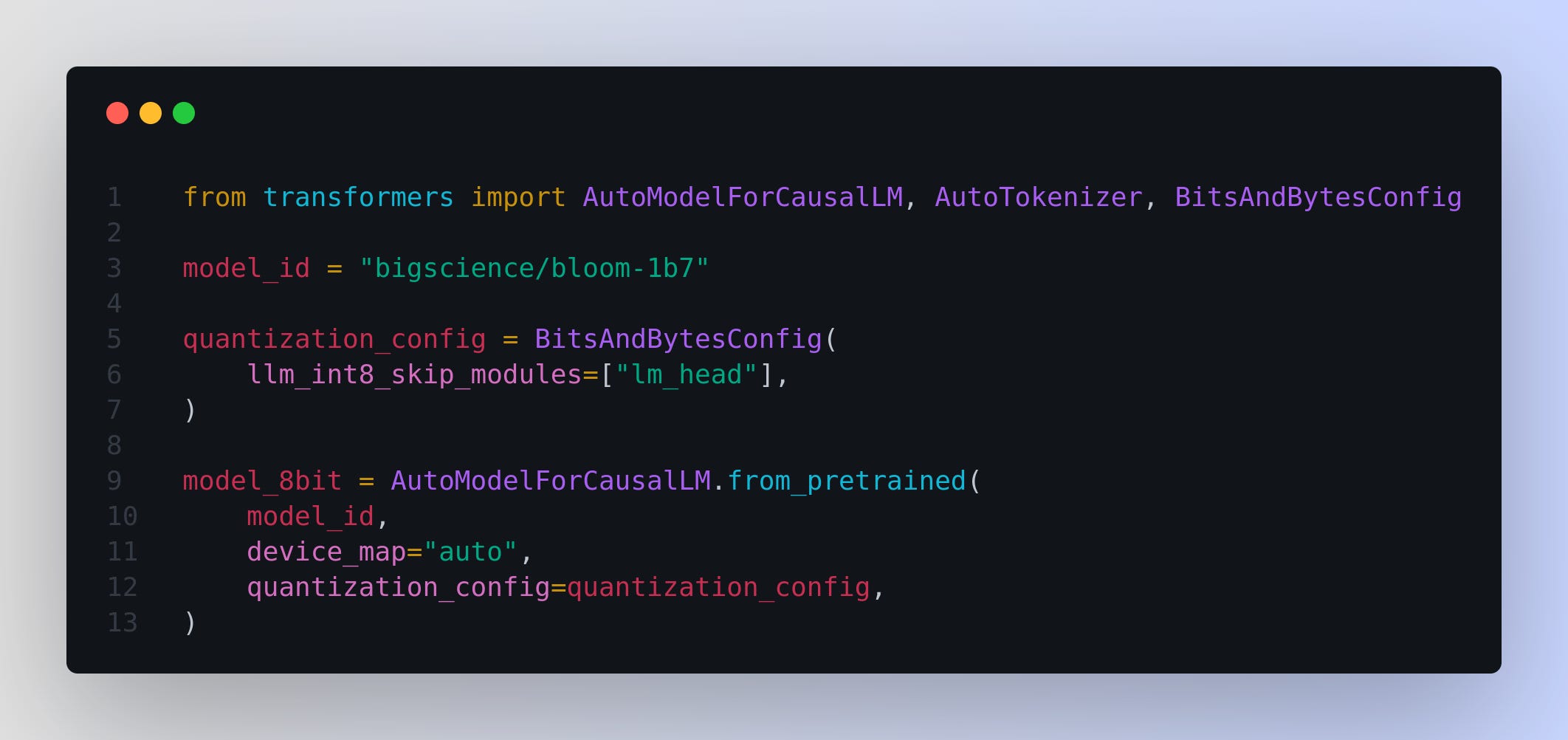
The decision not to quantize the "lm_head" (language model head) in the architecture of a quantized model like Llama 2 7B during QLoRA training is strategic and has significant implications for model performance and functionality. Here’s an in-depth analysis:
1. Role and Function of "lm_head"
Purpose: In neural network models, especially those used for language tasks, the "lm_head" typically comprises the final linear layer that maps the output of the transformer blocks (or other model components) to the vocabulary space. It is crucial for generating the final predictions or token probabilities based on the contextual embeddings produced by the model.
Sensitivity: This part of the model directly influences the output probabilities and is highly sensitive to small changes in the input from the transformer's output. The precision of the calculations here significantly affects the accuracy of the output tokens.
2. Precision Requirements
Need for High Precision: The mapping performed by the "lm_head" often involves a large vocabulary where subtle differences in the learned embeddings can lead to different output tokens. High precision ensures that these subtle differences are captured accurately, enabling the model to make correct and nuanced predictions.
Impact of Quantization: Quantizing this layer could lead to a loss of detail in how embeddings map to tokens. Given the exponential nature of the softmax function used in this layer (common in classification tasks to normalize outputs into probability distributions), even minor inaccuracies in input values can lead to large errors in the output probabilities.
3. Quantization Trade-offs
Balancing Performance and Efficiency: While quantization generally helps in reducing the model size and speeding up computations by using lower-precision arithmetic, it inherently introduces a trade-off between performance and computational efficiency. For the "lm_head", the trade-off skews towards maintaining performance over computational savings because the accuracy of this layer is critical for the overall utility of the model.
Error Propagation: In layers prior to the "lm_head", errors introduced by quantization can be somewhat mitigated or averaged out across many operations and non-linear activations (like ReLU). However, errors in the "lm_head" directly affect the final output without further corrections, making precision here more crucial.
4. Practical Considerations in Deployment
Flexibility in Fine-Tuning and Adaptation: Keeping the "lm_head" at higher precision also offers more flexibility when fine-tuning the model on specific tasks or datasets. It allows for precise adjustments to the model’s behavior at the output level, which is often necessary when adapting pre-trained models to specialized applications.
Hardware and Inference Efficiency: Modern inference hardware, such as GPUs and TPUs, is highly optimized for certain operations at 16-bit precision (like those used in "lm_head"). This means there may be no substantial computational penalty for maintaining higher precision in this layer, while the benefit in terms of output quality is significant.
📌 Conclusion
The non-quantization of the "lm_head" in QLoRA training reflects a deliberate choice to prioritize output accuracy and model adaptability over the potential gains in memory and computational efficiency that quantization might offer. This decision underscores the importance of precision in layers directly contributing to the model's final outputs, especially in high-stakes applications like natural language understanding and generation, where the quality of each prediction is paramount.