
🥊Elon Musk Files Injunction to Block OpenAI’s For-Profit Transition
Musk sues OpenAI/Microsoft, global 10B model breakthrough, LazyGraphRAG launch, and new papers on LLM reasoning and training efficiency.


In today’s Edition (2-Dec-2024):
🥊Musk targets OpenAI's structural transformation with new legal action against Altman and Microsoft
🤯The First Globally Trained 10B Parameter Model, community-powered computers across continents unite
Microsoft releases LazyGraphRAG which outperforms all competing methods of RAG based search for 4% of the query cost of GraphRAG
🗞️ Top Papers Roundup of the last week
Boundless Socratic Learning with Language Games - Teaching AI to learn from itself
DeMo: Decoupled Momentum Optimization - Distributed LLM training just got 22x more efficient
Do Large Language Models Perform Latent Multi-Hop Reasoning without Exploiting Shortcuts?
Large Multi-modal Models Can Interpret Features in Large Multi-modal Models - AI models become their own explainers
📖 Deep Dive Tutorial
Complete tutorial for deploying and optimizing language models using llama.cpp
🥊Musk targets OpenAI's structural transformation with new legal action against Altman and Microsoft

The Brief
Elon Musk filed a preliminary injunction against OpenAI to block its transition to a for-profit structure, marking his fourth legal action targeting the company's structural transformation and its partnership with Microsoft.
The Details
→ The injunction targets multiple high-profile defendants including Sam Altman, Greg Brockman, Microsoft VP Dee Templeton, and Reid Hoffman. The legal action aims to preserve OpenAI's original non-profit character and prevent asset transfers.
→ Musk's filing alleges anticompetitive practices, claiming OpenAI and Microsoft discouraged investors from backing competitors like xAI through restrictive investment terms. It also points to improper sharing of competitive information between the partnered companies.
→ The complaint highlights potential self-dealing issues, specifically mentioning OpenAI's use of Stripe as its payment processor, where Altman holds material financial investments.
The Impact
The injunction could significantly disrupt OpenAI's plans to secure its $150B+ valuation and pending investments. While OpenAI dismisses these claims as baseless, the legal challenge directly threatens the company's fundamental business transformation and its strategic partnership with Microsoft.
🤯The First Globally Trained 10B Parameter Model, community-powered computers across continents unite
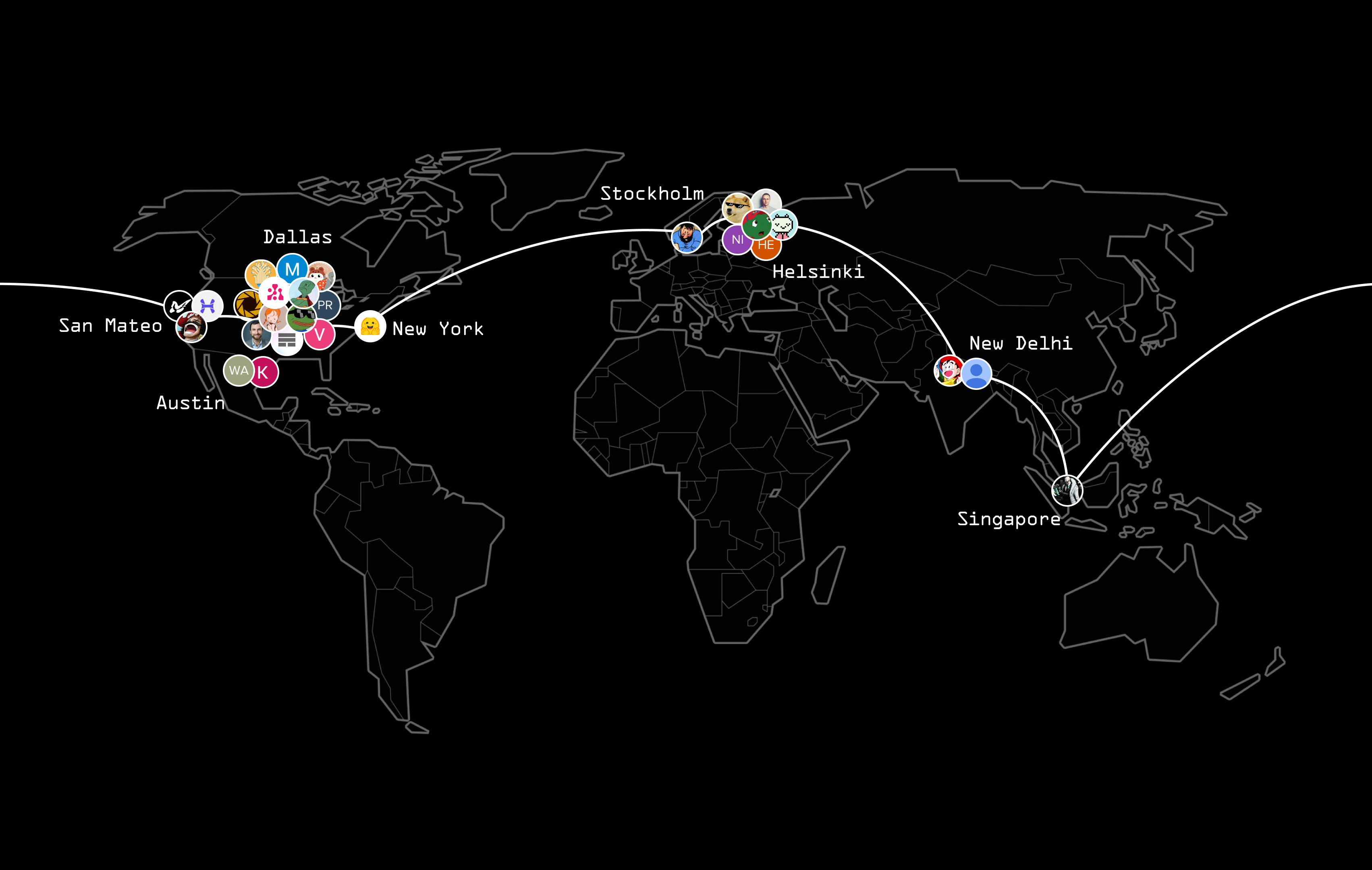
The Brief
Prime Intellect released INTELLECT-1, the first 10B parameter LLM trained collaboratively across multiple continents using distributed computing. This breakthrough demonstrates feasible large-scale decentralized AI model training, achieving 96% compute utilization within US and 83% globally using up to 112 H100 GPUs across five countries.
The Details
→ Built on Llama-3 architecture with 42 layers, 4096 hidden dimensions, 32 attention heads, and 8192 sequence length. The model was trained on 1T tokens with a diverse dataset mix: 55% FineWeb-Edu, 20% Stack v2, 10% FineWeb, 10% DCLM-baseline, and 5% OpenWebMath.
→ The PRIME framework enabled efficient distributed training through innovations like ElasticDeviceMesh and DiLoCo implementation, reducing communication bandwidth by 400x compared to traditional approaches. Training utilized dynamic node participation, scaling from 4 to 14 nodes while maintaining stability despite geographical distribution.
→ Post-training optimization involved collaboration with Arcee AI, including 16 SFT runs, 8 DPO runs, and strategic model merging using MergeKit. Median sync times varied: 103s for US-only, 382s for transatlantic, and 469s for global training.
The Impact
This achievement demonstrates the viability of community-driven AI development as an alternative to centralized corporate training. The success of INTELLECT-1 proves that distributed training can match the performance of centrally trained models while democratizing AI development through global collaboration.
🚀 Microsoft releases LazyGraphRAG which outperforms all competing methods of RAG based search for 4% of the query cost of GraphRAG
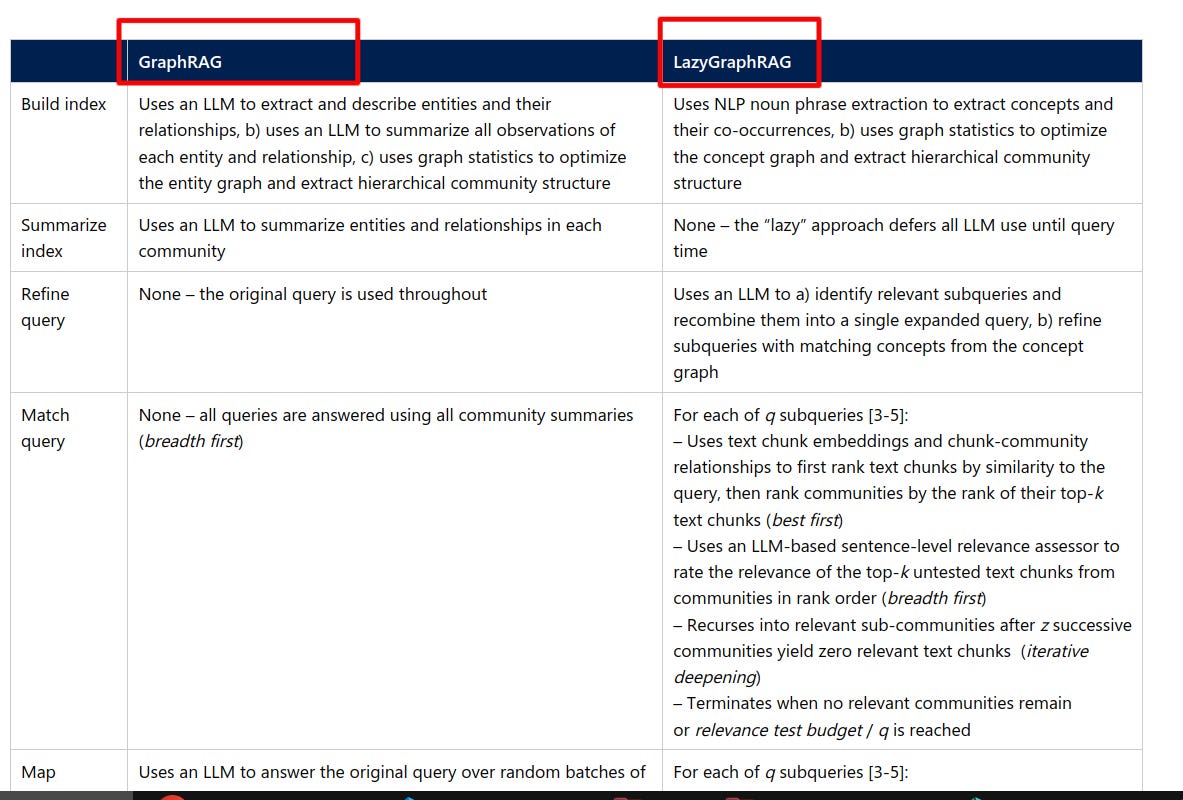
The Brief
Microsoft introduces LazyGraphRAG, a groundbreaking approach to retrieval-augmented generation that achieves comparable performance to GraphRAG at 1/700th query cost while maintaining the same indexing costs as vector RAG, revolutionizing how AI systems handle private dataset queries.
The Details
→ LazyGraphRAG fundamentally transforms RAG by deferring LLM use until query time and eliminating prior source data summarization. The system combines best-first and breadth-first search in an iterative deepening manner, using relevance test budgets to control cost-quality tradeoffs.
→ At the lowest budget level with 100 relevance tests, LazyGraphRAG significantly outperforms all conditions on local and global queries, except for GraphRAG global search conditions. When increased to 500 relevance tests (4% of C2 query cost), it surpasses all conditions across both query types.
→ The system's data indexing costs are identical to vector RAG and only 0.1% of full GraphRAG costs. It employs query expansion and concept-based retrieval to enhance performance across the local-global query spectrum.
The Impact
LazyGraphRAG establishes a new benchmark for RAG systems, particularly valuable for one-off queries, exploratory analysis, and streaming data scenarios. While not replacing traditional GraphRAG, it offers a highly efficient alternative that could be further enhanced by combining with GraphRAG summaries and pre-emptive claim extraction.
Byte-Size Brief
ChatGPT mysteriously terminates conversations when users attempt to make it write "David Mayer". Users across social platforms have tried various methods to bypass this limitation, including ciphers and coded messages. The cause remains unknown despite extensive testing.
Hugging Face integrated Text-to-SQL capabilities across their entire public dataset ecosystem of over 250,000 datasets, using Qwen 2.5 Coder 32B as the underlying model to power this functionality. Ask questions in English to search 250,000 datasets - no SQL needed. The browser-based system uses DuckDB WASM for local processing, handles 12.6M rows in 3 seconds, and automatically converts datasets to Parquet format within a 3GB memory limit.
Google AI Studio adds proper mathematical expressions supprt with LaTeX rendering. Now, you can transforms mathematical expression from raw text into properly formatted equations.
ZenML published a database of how companies actually deploy LLMs in Production. Straight from engineering teams. The database compiles performance metrics, hardware setups, and deployment architectures from 300+ implementations, comparing hosted vs API costs and documenting real optimization solutions.
🗞️ Top Papers Roundup of the last week
📖 Boundless Socratic Learning with Language Games
This paper introduces a framework for creating self-improving AI systems through language-based interactions. It proposes using structured language games to enable continuous learning without human data, addressing the core challenge of bounded improvement in current AI systems.
Original Problem 🤔:
AI systems currently hit improvement ceilings due to their dependence on human-sourced data and feedback. This limits their potential for recursive self-improvement.
Solution in this Paper 🔧:
→ The paper presents "Socratic learning" - a system where AI agents engage in recursive language interactions within closed environments.
→ It implements multiple narrow language games with clear rules and scoring functions instead of a single broad objective.
→ Each game provides automatic feedback and data generation through structured agent interactions.
→ A meta-game system schedules and manages these language games to maintain learning diversity.
Key Insights 💡:
→ Closed systems can achieve boundless improvement through well-designed language interactions
→ Multiple targeted language games provide better learning than single universal objectives
→ Meta-game scheduling helps prevent learning collapse and drift
📖 DeMo: Decoupled Momentum Optimization
Key Contribution: DeMo enables LLM training across distributed systems without needing expensive high-speed interconnects. By decoupling momentum updates and allowing controlled divergence in optimizer states, it reduces inter-accelerator communication by orders of magnitude while maintaining or exceeding AdamW's performance.
Original Problem 🤖:
→ Training LLMs requires sharing gradients between accelerators through high-speed interconnects like Infiniband
→ These specialized interconnects are expensive and force all accelerators to be in the same datacenter
Key Insights 💡:
→ Gradients and optimizer states during training have significant redundancy
→ Fast-moving momentum components need immediate synchronization while slow ones can be decoupled
→ DCT can efficiently extract and compress important gradient components
Solution in this Paper ⚙️:
→ DeMo uses Discrete Cosine Transform to identify and extract key momentum components
→ It synchronizes only the most significant components across accelerators
→ Allows controlled divergence in optimizer states while maintaining convergence
Results 📊:
→ Matches or exceeds AdamW performance on standard benchmarks
→ Reduces communication volume by 21.9x for 1B parameter model
→ Enables training with limited network bandwidth
📖 Do Large Language Models Perform Latent Multi-Hop Reasoning without Exploiting Shortcuts?
LLMs show promising but inconsistent abilities to reason without showing their work
This paper evaluates if LLMs can perform latent multi-hop reasoning without exploiting shortcuts. Through rigorous dataset creation and evaluation methods, it reveals LLMs can compose knowledge internally for certain query types, but performance varies dramatically based on bridge entity type - from 80% accuracy with countries to just 5% with years.
Original Problem 🤔:
→ Prior evaluations couldn't verify if LLMs truly perform latent reasoning or just exploit shortcuts from training data co-occurrences
→ Models could get correct answers through simple pattern matching rather than actual reasoning
Solution in this Paper 🛠️:
→ Created SOCRATES dataset excluding test queries where head/answer entities co-appear in training
→ Filtered cases where bridge entities could be easily guessed
→ Implemented systematic removal of queries vulnerable to shortcuts
→ Applied rigorous evaluation to distinguish true reasoning from pattern matching
Key Insights 📊:
→ LLMs construct clearer internal representations for better-performing query types
→ Model scaling shows minimal improvement in latent reasoning
→ Chain-of-Thought reasoning significantly outperforms latent reasoning
Results 📈:
→ 80% accuracy for country-based queries
→ Only 5% accuracy for year-based queries
→ 96% CoT success vs 8% latent reasoning success for top models
📖 Large Multi-modal Models Can Interpret Features in Large Multi-modal Models
Making AI models interpret themselves. The paper develops a method where models can interpret their own internal features using sparse autoencoders (SAE). So models can now analyze and explain how their own neural networks process and understand information.
Original Problem 🔍:
LLMs are black boxes - we can't understand their internal representations or control their behaviors, leading to unexpected outputs and hallucinations.
Solution in this Paper 🛠️:
→ Paper introduces a framework that uses Sparse Autoencoders (SAE) to break down LLM features into understandable components
→ SAE integrates into a specific layer of LLaVA-NeXT model, disentangling representations into human-interpretable features
→ Framework employs auto-explanation pipeline where larger LLMs interpret features of smaller ones
Key Insights 💡:
→ Model contains emotional features that enable empathy and EQ capabilities
→ Low-level visual features differ significantly from text-based features
→ Feature steering can control model behavior and reduce hallucinations
Results 📊:
→ IOU score of 0.20 and CLIP score of 23.6 across all concept categories
→ 89% GPT-4 consistency and 75% human consistency in feature interpretations
🧑🎓 Deep Dive Tutorial
Complete tutorial for deploying and optimizing language models using llama.cpp
This blog is a really long and comprehensive guide on building and using llama.cpp for devloping with your local LLMs
→ Showing how to run LLMs locally using llama.cpp, focusing on the SmolLM2 model family as an example.
→ Demonstrates complete workflow from building llama.cpp, converting models to GGUF format, quantizing them for efficiency, to running the server and interacting with models.
📊 Some Highlights
→ Model Architecture and Memory Requirements
SmolLM2's smallest 1.7B model requires approximately 3GB of VRAM/RAM when quantized to 8-bit precision (Q8_0). The guide explains how different quantization methods affect model size and performance.
→ Performance Benchmarks
The author achieved significant speedups using GPU acceleration via Vulkan backend - prompt processing improved 5.3x (from 165 to 880 tokens/second), and text generation improved 4x (from 22 to 90 tokens/second).
→ Advanced Sampling Parameters
The guide provides detailed explanations of sampling parameters like temperature, top-k, top-p, min-p, and repetition penalties. Each parameter's effect on text generation is explained with practical examples.
🛠️ Building Process
The guide shows how to build llama.cpp with different backends (CPU, CUDA, Vulkan, etc.), with detailed explanations of each option and their tradeoffs.
→ Model Conversion Pipeline
Details the process of converting HuggingFace models to GGUF format and subsequent quantization, explaining the technical reasoning behind each step.