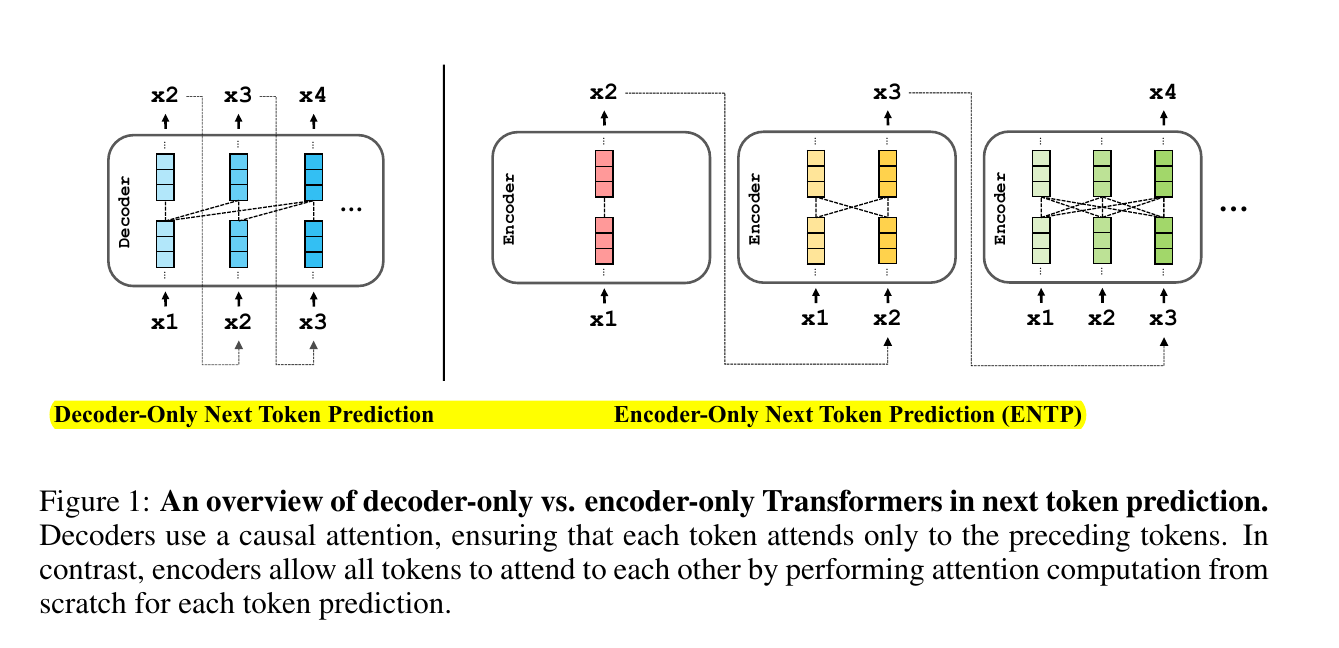
ENTP: Encoder-only Next Token Prediction
Trading speed for power: Full attention matrices, instead of causal masks, outshine causal masking in complex tasks.


Trading speed for power: Full attention matrices, instead of causal masks, outshine causal masking in complex tasks.
In more simple words, sometimes looking backward helps you predict forward better, and let tokens talk to their future friends.
Original Problem 🔍:
Next-token prediction models primarily use decoder-only Transformers with causal attention, limiting their expressive power.
Solution in this Paper 🛠️:
• Introduces Encoder-only Next Token Prediction (ENTP)
• Compares ENTP with decoder-only Transformers in expressive power and complexity
• Proposes Triplet-Counting task to showcase ENTP's advantages
• Evaluates ENTP on various tasks including length generalization and in-context learning
Key Insights from this Paper 💡:
• Encoder-only and decoder-only models have different expressive capabilities
• ENTP offers greater expressivity but at the cost of computational efficiency
• Causal attention in decoders is about efficiency, not necessity
• ENTP outperforms decoders in tasks like Triplet-Counting and length generalization
Results 📊:
• ENTP outperforms decoder-only models on Triplet-Counting task
• Superior performance in length generalization for addition tasks
• Better or competitive performance in in-context learning across various function classes
• Slightly lower perplexity on OpenWebText dataset (104.6 vs 110.5 for decoder-only)
The paper introduces the concept of Encoder-only Next Token Prediction (ENTP) as an alternative to the commonly used decoder-only Transformers for next-token prediction tasks. The key differences are:
Attention mechanism: Encoder-only models use full self-attention for each token prediction, while decoder-only models use causal attention.
Computation: ENTP recomputes attention from scratch for each token, while decoder-only models can cache previous computations.
Expressivity: The paper argues that encoder-only and decoder-only models have different expressive capabilities, with some functions being easier to express for one architecture over the other.