
Euclidean Distance and Normalization of a Vector

Euclidean distance
Euclidean distance is the shortest distance between two points in an N-dimensional space also known as Euclidean space. It is used as a common metric to measure the similarity between two data points and used in various fields such as geometry, data mining, deep learning, and others.
It is, also, known as Euclidean norm, Euclidean metric, L2 norm, L2 metric, and Pythagorean metric.
Consider two points P1 and P2:
P1: (X1, Y1) P2: (X2, Y2)
Then, the euclidean distance between P1 and P2 is given as:
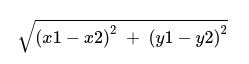
Euclidean distance in N-D space
In an N-dimensional space, a point is represented as (x1, x2, …, xN).
Consider two points P1 and P2:
P1: (X1, X2, …, XN) P2: (Y1, Y2, …, YN)
Then, the euclidean distance between P1 and P2 is given as:
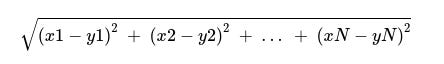
Furthermore, we can carry on like this into 4 or more dimensions, in general, J dimensions, where J is the number of variables. Although we cannot draw the geometry any more, we can express the distance between two J-dimensional vectors x and y as:
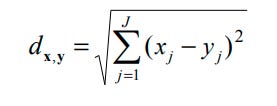
There are quite a few distance measurement techniques, e.g. few other popular distance measures include:
Hamming Distance: Calculate the distance between binary vectors (Wikipedia).
Manhattan Distance: Calculate the distance between real vectors using the sum of their absolute difference. Also called City Block Distance (Wikipedia).
Minkowski Distance: Generalization of Euclidean and Manhattan distance (Wikipedia).
Euclidean is a good distance measure to use if the input variables are similar in type (e.g. all measured widths and heights). Manhattan distance is a good measure to use if the input variables are not similar in type (such as age, gender, height, etc.
Manhattan distance is used only if the points are arranged in square format and that too the distance between each of the points should be a multiple of the length of the side of a square. We rarely come across this kind of scenarios in realtime and the mostly used metric is Euclidean distance as we prefer it when working on completely numerical data. When we work on the text data, the cosine distance is an appropriate metric.
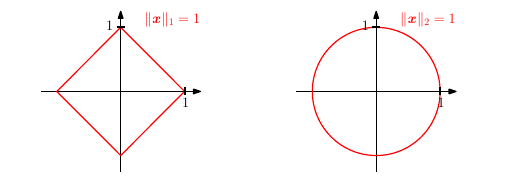
For different norms, the red lines indicate the set of vectors with norm 1. Left: Manhattan norm; Right: Euclidean distance.
What does it mean to normalize an array ?
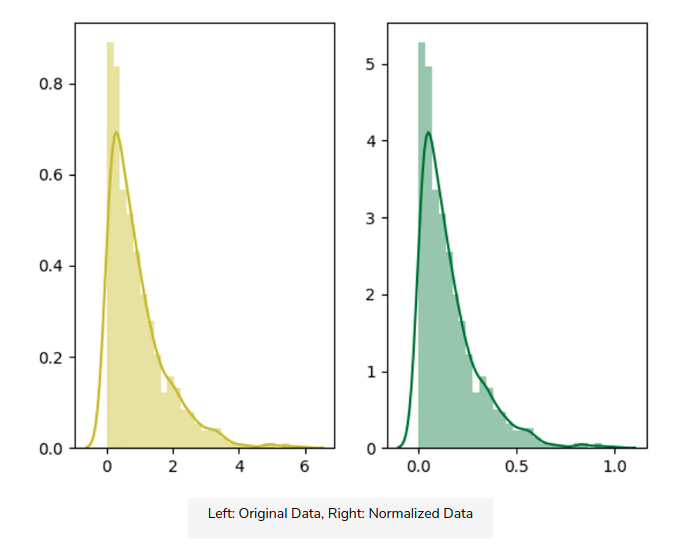
Data normalization is used in machine learning to make model training less sensitive to the scale of features. This allows our model to converge to better weights and, in turn, leads to a more accurate model. Normalization makes the features more consistent with each other, which allows the model to predict outputs more accurately.
To normalize a vector in math means to divide each of its elements to some value V so that the length/norm of the resulting vector is 1. Turns out the needed V is equal the length (the length of the vector).
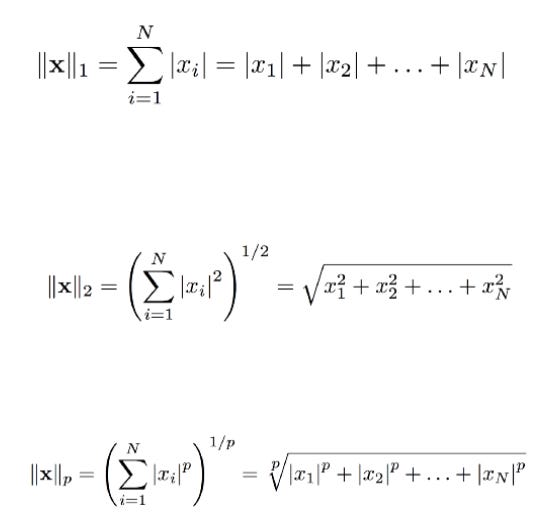
So this is basically the following norm calculations
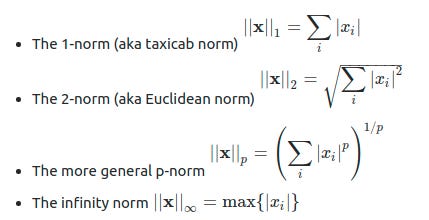
For a vector x having N components, the L¹ just adds up the components. Since we would like our magnitude to always be positive, we take the absolute value of the components. The L² norm takes the sum of the squared values, taking the square root at the end.
Say you have this array.
[-3, +4]
Its length (in Euclid metric) is: V = sqrt((-3)^2 + (+4)^2) = 5
So its corresponding normalized vector is:
[-3/5, +4/5]
Its length is now: sqrt ( (-3/5)^2 + (+4/5)^2 ) which is 1.
You can use another metric (e.g. I think Manhattan distance) but the idea is the same. Divide each element of your array by V where V = || your_vector || = norm (your_vector).
Informally speaking, the norm is a generalization of the concept of (vector) length; from the Wikipedia entry:
In linear algebra, functional analysis, and related areas of mathematics, a norm is a function that assigns a strictly positive length or size to each vector in a vector space.
The L2-norm is the usual Euclidean length, i.e. the square root of the sum of the squared vector elements.
The L1-norm is the sum of the absolute values of the vector elements.
The max-norm (sometimes also called infinity norm) is simply the maximum absolute vector element.
As the docs say, normalization here means making our vectors (i.e. data samples) having a unit length, so specifying which length (i.e. which norm) is also required.
You can easily verify the above by adapting the examples from the docs:
from sklearn import preprocessingimport numpy as np
X = [[ 1., -1., 2.], [ 2., 0., 0.], [ 0., 1., -1.]]
X_l1 = preprocessing.normalize(X, norm='l1')X_l1# array([[ 0.25, -0.25, 0.5 ],# [ 1. , 0. , 0. ],# [ 0. , 0.5 , -0.5 ]])
You can verify by simple visual inspection that the absolute values of the elements of X_l1 sum up to 1.
X_l2 = preprocessing.normalize(X, norm='l2')X_l2# array([[ 0.40824829, -0.40824829, 0.81649658],# [ 1. , 0. , 0. ],# [ 0. , 0.70710678, -0.70710678]])
np.sqrt(np.sum(X_l2**2, axis=1)) # verify that L2-norm is indeed 1# array([ 1., 1., 1.])
Normalizing a Vector
First the absolute basics of what norm is -

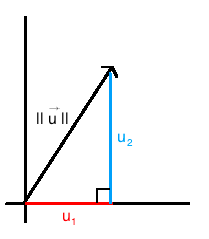
So, now, calculate the norm of the vector u⃗ =(3,4).
We first note that u⃗ ∈ R2, and we will thus use the formula
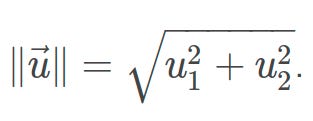
When we substitute our values in, we obtain that ∥u⃗ ∥=√25 = 5. Thus our vector u⃗ has length / norm of 5.
Mathematically a norm is a total size or length of all vectors in a vector space or matrices. And after we calculate the Norm, then we can normalize a vector. By definition a norm on a vector space — over the real or complex field — is an assignment of a non-negative real number to a vector. The norm of a vector is its length, and the length of a vector must always be positive (or zero). A negative length makes no sense.
Taking any vector and reducing its magnitude to 1.0 while keeping its direction is called normalization. Normalization is performed by dividing the x and y (and z in 3D) components of a vector by its magnitude:
For any vector V = (x, y, z),
we know the magnitude |V| = sqrt(x_x + y_y + z*z) which gives the length of the vector.
When we normalize a vector, we actually calculate
V/|V| = (x/|V|, y/|V|, z/|V|).
Let's look at an example
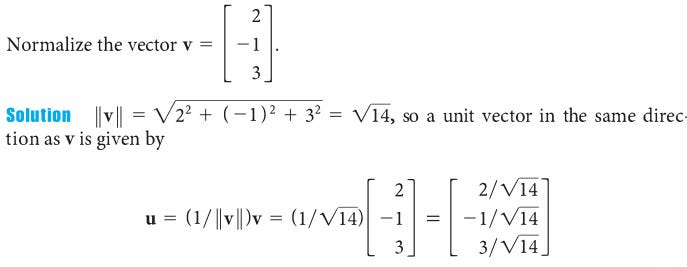
Can do some basic calculation to see that a normalized vector has length 1. This is because:
(In the first line below I to bring the sqrt outside of the braces, I am multiplying x/|V| with x/|V| and so on )
| V/|V| | = sqrt((x/|V|)*(x/|V|) + (y/|V|)*(y/|V|) + (z/|V|)*(z/|V|)) = sqrt(x*x + y*y + z*z) / |V| = |V| / |V| = 1
Hence, we can call normalized vectors as unit vectors (i.e. vectors with unit length).
Any vector, when normalized, only changes its magnitude, not its direction. Also, every vector pointing in the same direction gets normalized to the same vector (since magnitude and direction uniquely define a vector). Hence, unit vectors are extremely useful for providing directions.
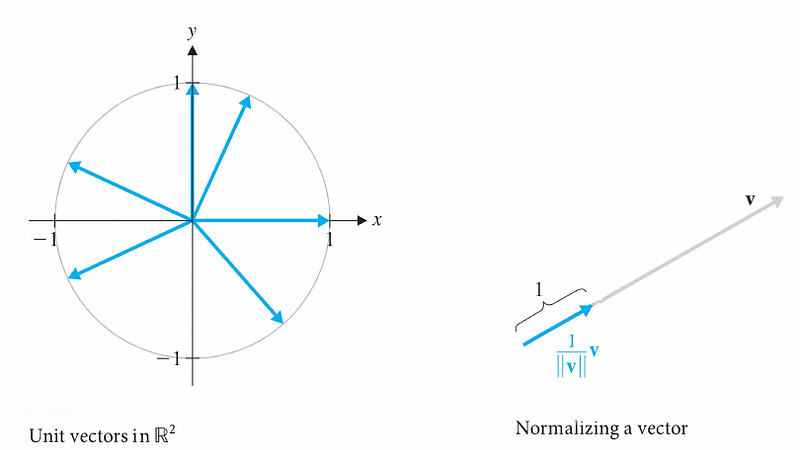
A vector of length 1 is called a unit vector. In 𝑅2 , the set of all unit vectors can be identified with the unit circle, the circle of radius 1 centered at the origin
L1 Vs L2? Which one to use?
L1 norm
Is also known as least absolute deviations (LAD), least absolute errors (LAE) It is basically minimizing the sum of the absolute differences (S) between the target value (Yi) and the estimated values (f(xi)): as shown in picture 1 On another words Sum of absolute values = 1 Example if applied this norm along row then sum of square for a row = 1. It is insensitive to outliers Sparsity: Refers to that only very few entries in a matrix (or vector) is non-zero. L1-norm has the property of producing many coefficients with zero values or very small values with few large coefficients.
Having, for example, the vector X = [3,4]:
The L1 norm is calculated by
||X || = |3| + |4| = 7
L2 norm
It is the shortest distance to go from one point to another. Is also known as least squares
The L2 norm is calculated as the square root of the sum of the squared vector values. The L2 norm calculates the distance of the vector coordinate from the origin of the vector space. As such, it is also known as the Euclidean norm as it is calculated as the Euclidean distance from the origin. The result is a positive distance value.
||v||2 = sqrt(a1² + a2² + a3²)
Computational efficiency:
L1-norm does not have an analytical solution, but L2-norm does.
This allows the L2-norm solutions to be calculated computationally efficiently. However, L1-norm solutions does have the sparsity properties which allows it to be used along with sparse algorithms, which makes the calculation more computationally efficient.
The L1 norm is the sum of the absolute values.
The L2 norm is the square root of the sum of the squared values.
By squaring values, you are putting more emphasis on large values and less influence on small values.
For example, consider just the ten-element vector [1,1,1,1,1,1,1,1,1,10]. The L1 norm is 19; and the largest value, 10, contributes 10/19=53% of it.
The L2 norm is sqrt(109)=10.44, and the largest value contributes 100/109=92% of the sum.
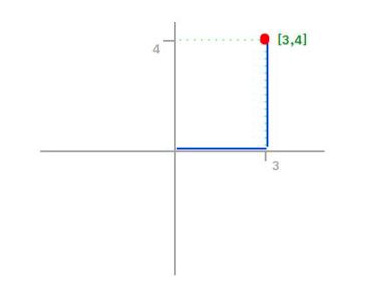
Differences between Norm of a Vector and distance between two points
Key point to remember — Distance are always between two points and Norm are always for a Vector.
That means Euclidean Distance between 2 points x1 and x2 is nothing but the L2 norm of vector (x1 — x2)
This is actually by definition that the L2 Norm of a vector = Euclidian distance of that point vector from origin.
In other words, the distance(metric) between any two vectors can be defined as the norm of the difference of those two vectors.
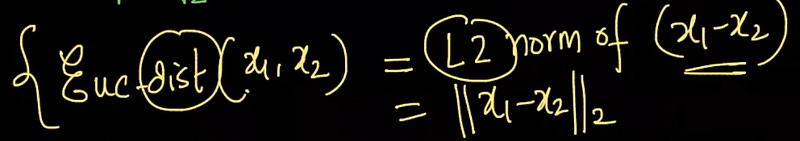
Thanks for reading :))