EvolveDirector: Approaching Advanced Text-to-Image Generation with Large Vision-Language Models
A clever way to train open-source image models by learning from API-only models using vision-language feedback


A clever way to train open-source image models by learning from API-only models using vision-language feedback
Original Problem 🔍:
Text-to-image models with exceptional capabilities are often restricted to API access, limiting their widespread use.
Solution in this Paper 🛠️:
• EvolveDirector framework introduced to train open-source text-to-image models
• Uses advanced models' APIs to obtain training images
• Leverages Vision-Language Models (VLMs) to guide dynamic dataset curation
• Implements discrimination, expansion, deletion, and mutation operations
• Incorporates layer normalization after Q and K projections in cross-attention blocks
Key Insights from this Paper 💡:
• Generation abilities can be approximated through training on generated data
• VLMs significantly reduce required data volume for efficient training
• Learning from multiple advanced models can surpass individual model performance
Results 📊:
• 100k training samples sufficient for base model to match target model performance
• Edgen (final trained model) outperforms DeepFloyd IF, Playground 2.5, Stable Diffusion 3, and Ideogram
• Demonstrates superior capabilities in human generation, text generation, and multi-object generation
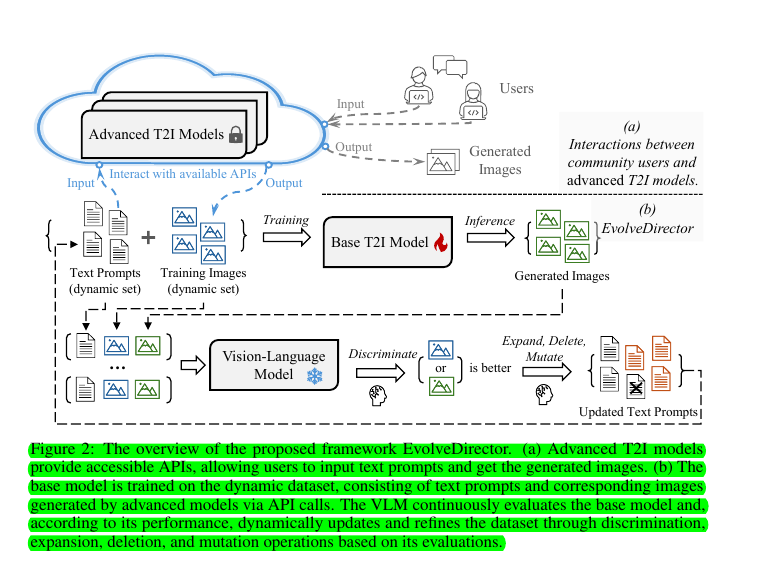
🧠 EvolveDirector uses a three-part process:
It interacts with advanced T2I models through their APIs to get training images.
It maintains a dynamic training set guided by a Vision-Language Model (VLM).
It trains a base model on this dynamic training set.