EvoPress: Towards Optimal Dynamic Model Compression via Evolutionary Search
Darwin meets LLMs: Evolution beats human rules at squeezing big AI models


Darwin meets LLMs: Evolution beats human rules at squeezing big AI models
Evolutionary search finds optimal LLM compression by challenging traditional error assumptions.
This paper finds, Multi-step selection tackles LLM compression bottlenecks without relying on flawed metrics
Basically, Nature-inspired search discovers better LLM compression solutions than human-crafted rules
Original Problem 🎯:
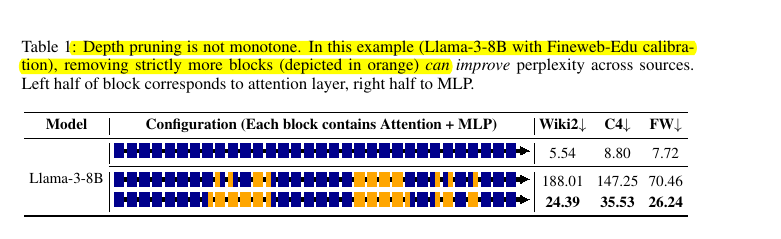
Current LLM compression methods rely on flawed assumptions about error monotonicity - that lower per-layer errors mean better overall model performance. This leads to suboptimal compression results, especially at higher compression ratios.
Solution in this Paper 🔧:
• EvoPress: A new evolutionary search framework for optimal dynamic compression
• Uses multi-step selection process - evaluates candidates progressively on increasing samples
• Starts with single search point, generates offspring through mutation operations
• Works across all compression types (pruning, sparsification, quantization)
• Provides theoretical convergence guarantees and low sample complexity
Key Insights 💡:
• Error monotonicity assumption is false - models with lower per-layer errors can perform worse
• Dynamic compression needs unbiased optimization approach rather than human-crafted scoring
• Multi-step selection with progressive evaluation is crucial for efficiency
• Low mutation rates work better in smooth fitness landscapes
Results 📊:
• Outperforms all prior methods across compression approaches
• For Mistral-7B at 70% sparsity: 14.42 PPL vs 17.22 (OWL) and 23.08 (uniform)
• For Llama-3-8B at 3-bit quantization: 7.49 PPL vs 12.19 (uniform)
• Converges in ~1 hour on single GPU for 8B parameter models
• Sets new state-of-the-art for depth pruning, especially at medium compression levels
💡 The key insight about error monotonicity
Error monotonicity (assumption that lower per-layer errors mean lower overall model error) does not hold generally for LLM compression. Models with lower sums of per-layer errors can perform worse than models with higher error sums.
This invalidates assumptions of previous approaches.