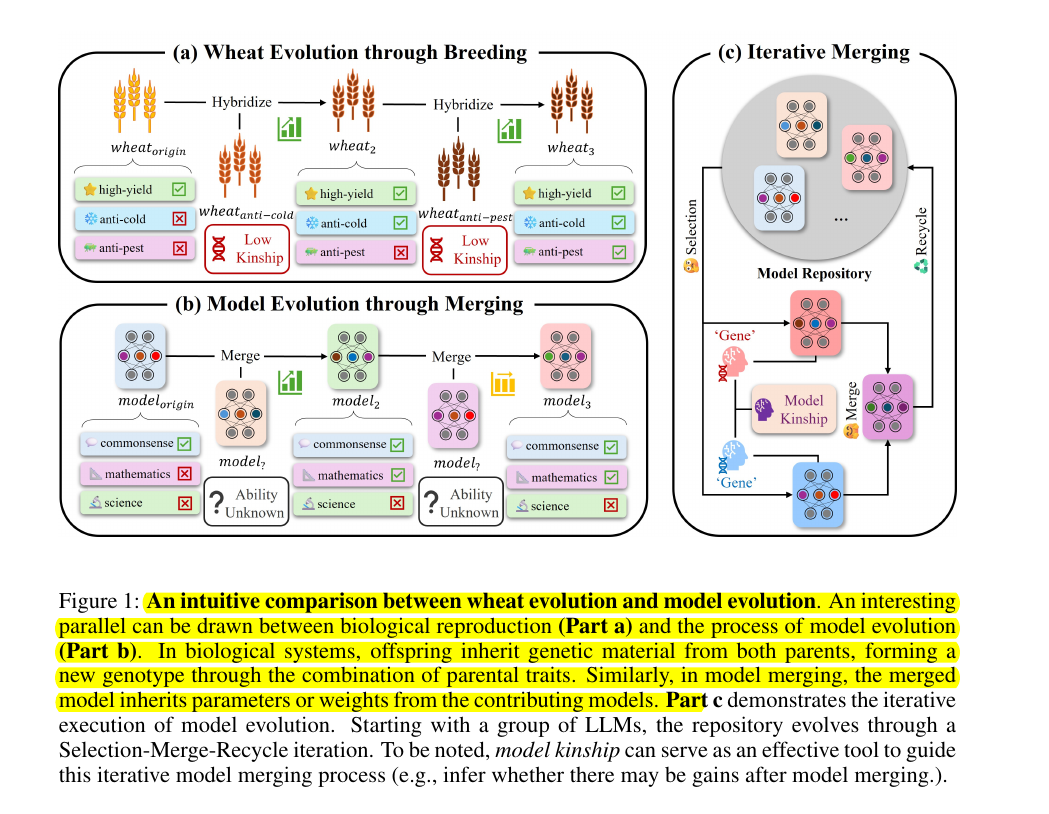
Exploring Model Kinship for Merging Large Language Models
LLMs use genetic-style "kinship scores" to find ideal merge partners, like DNA matching for AI models.


LLMs use genetic-style "kinship scores" to find ideal merge partners, like DNA matching for AI models.
So models now measure their genetic similarity before merging, leading to smarter offspring
Original Problem 🔍:
Model merging enhances LLM capabilities, but understanding performance gains and principles remains limited.
Solution in this Paper 🧩:
• Introduces "model kinship" metric to assess LLM similarity during merging
• Proposes Top-k Greedy Merging with Model Kinship strategy
• Uses model kinship as early stopping criterion to improve efficiency
Key Insights from this Paper 💡:
• Model kinship correlates with merge gain and average task performance
• Merging process has two stages: learning and saturation
• High model kinship (>0.9) indicates convergence and potential for early stopping
• Merging models with low kinship can boost exploration and escape local optima
Results 📊:
• Top-k Greedy Merging with Model Kinship outperforms vanilla greedy strategy
• Achieves 69.13 average task performance vs 68.72 for vanilla greedy
• Improves time efficiency by ~30% using model kinship as early stopping signal
• Escapes local optima and continues improving multitask capabilities
🔍 Model kinship is a metric designed to assess the degree of similarity or relatedness between LLMs based on their "genetic" information, which refers to the changes in weights during model evolution.
It's inspired by the concept of kinship from evolutionary biology and is used to estimate how closely related different LLMs are during the iterative model merging process.
🧠 The relationship between model kinship and performance gains in model merging
While model kinship alone is insufficient for predicting whether a model can achieve generalization gains through merging, it may serve as a key factor in determining the upper limit of merge gains, thus indicating potential improvements.