
Fast Takeoff Unlikely For Self Improving AI, Will Be Gradual, Over A Decade
AI designs antibodies in 14 days, decade-long AI self-upgrade debate, US cancel AI moratorium, free Gemini Classroom, Apple's Siri to go for OpenAI/Anthropic, Cursor’s multi-platform code-fix agents.

Read time: 10 mint
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (1-July-2025):
🥉 AI can now design new antibodies from scratch in just two weeks.
🧑🎓 OPINION: Self improving AI, fast takeoff unlikely, will be gradual over a decade
🗞️ Byte-Size Briefs:
US Senate announces AI moratorium removal; 99-1 vote frees states
Google launches no-cost Gemini Classroom; AI autogenerates lessons, quizzes instantly
Apple integrates OpenAI, Anthropic to upgrade Siri versus Google rivals
Cursor launches PWA agents fixing code; browser, mobile, Slack support
🧬 AI can now design new antibodies from scratch in just two weeks.

🧬 Chai Discovery unveils Chai-2, a model achieving a >15% hit rate in zero-shot antibody design. This represents a >100x improvement, cutting discovery timelines from months to just two weeks.
⚙️ The Details
This advancement compresses “hit” discovery timelines from months or even years down to approximately two weeks by eliminating the need for traditional, large-scale experimental screening.
What is ‘hit’
In drug discovery, a "hit" is a candidate molecule that shows the desired activity in an initial test. In this specific case, it refers to an antibody designed by the Chai-2 AI that, when created and tested in the lab, successfully binds to its intended target protein.
In a key experiment, Chai-2 was tasked with designing binders for 52 novel protein targets. With only 20 designs tested per target, the model achieved a 16% binding rate and successfully identified at least one effective binder for 50% of the targets. For miniprotein design, the model demonstrated an even higher 68% wet-lab hit rate, producing binders with high affinity.
Think of it as a search. Traditionally, scientists would screen millions of different molecules hoping for a "hit" – one that sticks to the target. Chai-2 designs a small, specific list of candidates. A "hit" means one of those computer-generated designs actually worked in the real world. A high "hit rate" means the AI's predictions are very accurate, which is why the discovery process becomes so much faster.
How Chai-2 really achieved it
The model's effectiveness comes from its multimodal generative architecture, which combines all-atom structure prediction with generative modeling. This allows it to create novel and diverse binders, including antibodies and nanobodies, that are specific to a desired epitope.
Think of the process as having two distinct but interconnected parts: one part that understands the "lock" (the target protein) and another that designs a brand-new "key" (the antibody).
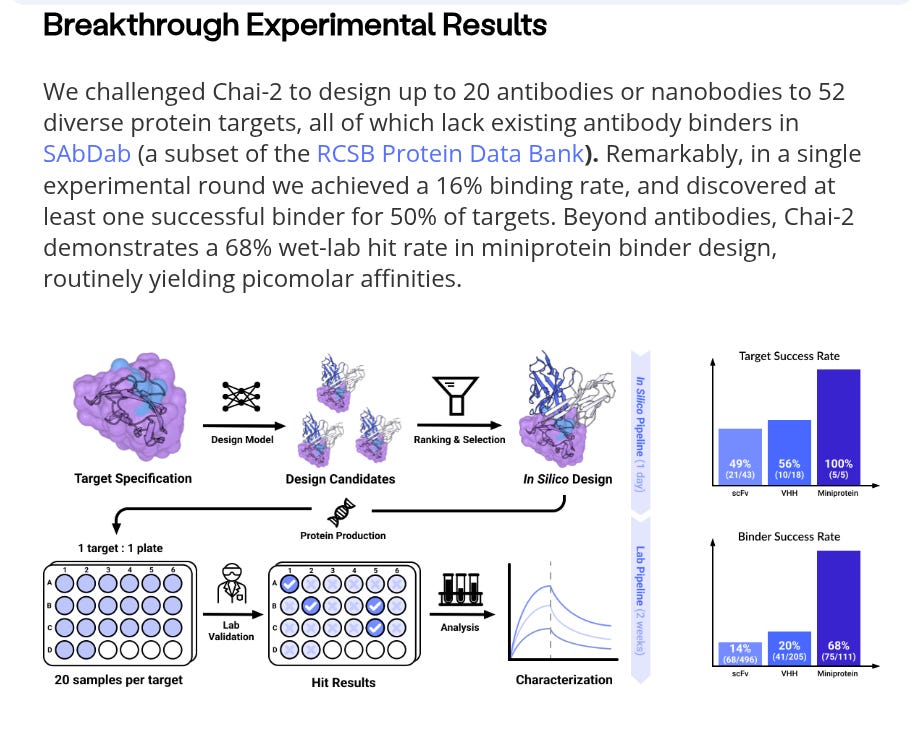
Understanding the Target (All-Atom Structure Prediction): First, the model is given a target protein and a specific region on it called an "epitope." This epitope is the precise spot where the antibody needs to bind. The "all-atom structure prediction" component acts like an incredibly powerful microscope. It analyzes the exact 3D shape and chemical properties of every single atom within that epitope. It's not just looking at a rough outline; it's building a highly detailed, 3D blueprint of the molecular surface it needs to interact with.
Designing the Binder (Generative Modeling): This is the creative part. Instead of searching through existing antibodies, the "generative modeling" component designs a new one from scratch. It generates novel sequences of amino acids (the building blocks of proteins). Crucially, as it generates a sequence, it simultaneously uses its structural understanding to predict how that sequence will fold into a 3D shape. The model's goal is to generate a sequence that will fold into a shape that is a perfect geometric and chemical complement to the target epitope, ensuring a tight and specific bond.
The term "multimodal" refers to the model's ability to process and integrate these two different types of information—the 3D structural data of the target and the 1D sequence data of the antibody—at the same time. This integration is what makes it so effective, as it designs the antibody's recipe and its final shape in a single, unified step.
Chai Discovery is now offering early access to academic and industry partners, prioritizing projects with a positive impact on human health.
Practical Implecations
The most significant implication is the potential to drastically accelerate the development of new medicines. This technology could enable researchers to tackle diseases caused by proteins previously considered "undruggable," potentially leading to novel treatments for challenging cancers, autoimmune conditions, and rare genetic disorders. By making the initial discovery phase faster and more predictable, it lowers the barrier to entry for creating advanced therapeutics like antibody-drug conjugates and other precision medicines.
More broadly, this represents a fundamental shift in biotechnology, moving it from a science of discovery to a discipline of engineering. In the event of a new pandemic, for example, researchers could computationally design neutralizing antibodies in weeks rather than searching for them in recovered patients over months. This transition from finding molecules to building them on demand could redefine how we approach everything from therapeutics and diagnostics to basic biological research.
🤔 OPINION: Self improving AI, fast takeoff unlikely, will be gradual over a decade

Just yesterday, OpenAI researcher Jason Wei wrote a long post on Twitter saying fast takeoff unlikely for self improving AI. Rather it will be gradual over a decade. “We don’t have AI self-improves yet, and when we do it will be a game-changer.”
There are many recent studies to support this view. Self-improvement of AI is graded, not on–off. Only after many iterations would an automated pipeline outpace humans.
LLMs already tweak themselves, but the gains arrive in small, uneven steps spread across domains, limited by compute cost, data efficiency, oversight plateaus, and the real-world speed of experiments. Recent 2025 papers back Jason Wei’s view that self-improvement will feel like a long, bumpy ramp rather than a leap.
🧩 The Core Concepts
Experiments that let a model grade its own work push accuracy upward, yet each round yields smaller returns and often stalls on harder tasks (arxiv.org). Different skills upgrade at different speeds. Arithmetic and string manipulation respond quickly, but low-resource language mastery or nuanced tool use lag because suitable data or evaluators are scarce (arxiv.org). Resource demand matters. Reinforcement Learning from Human Feedback and its self-supervised variants still burn thousands of GPU hours for modest jumps, so training loops remain slow and expensive.
Even with perfect software, progress bottlenecks on experiments in the physical world, from wet-lab biology to robotics, where each trial must finish before the next optimisation step (news.mit.edu, aicompetence.org, 2025.ieee-icra.org). Finally, every layer of automated oversight adds its own failure chance.
Mathematical models of scalable oversight show success rates flatten once the overseen system is a few hundred Elo stronger than its monitor (arxiv.org), and empirical benchmarks confirm that no single protocol dominates across tasks.
🔬Some recent studies in this context
Iterative Self-Improvement Remains Fragile
• Self-Improving Transformers solved increasingly long arithmetic strings but needed many curriculum rounds and still relied on human-curated filters to avoid error cascades (arxiv.org).
• Self-Rewarding Self-Improving showed a Qwen 7B model judging its own integration proofs, gaining only 8 % after multiple loops and still exposing reward-hacking risks (arxiv.org).
• Self-Challenging Agents doubled Llama-3.1-8B success in tool-use benchmarks, but required heavy reinforcement fine-tuning and careful task vetting to control noise (arxiv.org).
Data and Compute Efficiency Efforts
Researchers cut reinforcement fine-tuning cost 37X by re-using rollouts and targeting medium-difficulty queries, yet total training time still spanned days on high-end GPUs (arxiv.org). Tool-use studies found that adding more synthetic data eventually hurts because the model fixates on easy cases, so teams now alternate warm-up supervised fine-tuning with defect-focused reinforcement passes (arxiv.org).
Oversight Scaling Plateaus
A formal game-theoretic model put the nested success rate of weak-to-strong oversight below 52% once the gap passes 400 Elo, implying many layers are needed and each layer slows iteration (arxiv.org). A new benchmark comparing debate, consultancy, and propaganda protocols showed that performance varies by task, forcing empirical tuning at every capability level (arxiv.org).
Real-World Experiment Bottlenecks
FutureHouse’s automated lab platform still waits for chemical reactions, illustrating why smarter experiment design speeds progress only linearly, not explosively (news.mit.edu). Robotics faces the sim-to-real gap: simulations run instantly, but transferring policies to hardware demands cautious, multi-hour fine-tuning despite improved domain-adaptation tricks (aicompetence.org, 2025.ieee-icra.org).
Safety and Evaluation Instability
Fine-tuning, even on benign data, unpredictably degrades refusal behaviour, making each self-improvement round require fresh safety audits (arxiv.org). DeepSeek’s reward-only training skipped legible reasoning, raising concern that future self-trained models may drift outside human interpretability, forcing slower validation cycles (time.com). Wired’s SEAL system keeps tweaking weights on the fly, but the authors warn of catastrophic forgetting and heavy compute costs that still gate updates (wired.com).
🚦 What This Means for Takeoff Pace
Evidence from arithmetic curricula, self-judging math solvers, value-model bootstrapping, oversight scaling laws, and lab-robotics feedback loops points to a common pattern: every self-improvement loop introduces new frictions that must be ironed out in subsequent loops. Speedups accumulate, yet each domain hits fresh ceilings that need method-specific breakthroughs, human inspection, or long physical experiments.
🗞️ Byte-Size Briefs
US Senate Kills AI Moratorium 99-1, Letting States Regulate Freely
The original AI moratorium would have blocked states from passing or enforcing AI laws for 10 years, under threat of losing $42 billion in broadband and $500 million in AI funding.
On July 1, 2025, the Senate voted 99-1 to remove the moratorium from the One Big Beautiful Bill.
This means states can now regulate AI without risking federal funds. The tech industry, which backed the moratorium to avoid fragmented state rules, faces a major defeat. There's still no federal AI framework, but states now have a green light to move independently. The overwhelming vote signals rare bipartisan support for state-level AI governance and consumer protection.
Google launched Gemini in Classroom: a suite of No-cost AI tools that amplify teaching and learning. Teachers can auto-generate lesson drafts, quizzes and rubrics based on grade and topic. They can refine plans, find videos and export quizzes to Forms in seconds. And can also can create student-facing AI experiences using NotebookLM study guides and audio summaries. They can also build custom Gems like ‘Quiz me’ or ‘Study partner’ linked to class materials.
Apple reportedly considers letting Anthropic and OpenAI power the AI for Siri. AI rollout from 2025 to 2026, and shifting from its LLM Siri project to deeper third-party integration aimed at closing the gap with Google.
Cursor launched new apps for mobile and browser. So Cursor Agent now leaves the IDE and lives in the browser. The same model that autocompletes code can launch bug fixes, build features, or answer deep codebase questions while you continue other work. Any desktop, tablet, or phone can run it because the site is a Progressive Web App. Install once and it behaves like a native client on iOS or Android.
Agents operate with rich context. You can attach images, chain multiple agents in parallel, and then review their diffs and pull requests inside the web UI.
Slack support keeps teams in the loop. Mention @Cursor to start a task and receive a notification when it finishes, complete with links to the code change.
That’s a wrap for today, see you all tomorrow.
great article. appreciate the cites to alphaXiv. Interesting that smaller (like 7B) models can self-improve. Now this- “Fine-tuning, even on benign data, unpredictably degrades refusal behaviour, making each self-improvement round require fresh safety audits”- is fodder for the AI in my novel. Also, something to take note of in the real world.