
"Fast Video Generation with Sliding Tile Attention"
Below podcast on this paper is generated with Google's Illuminate.

https://arxiv.org/abs/2502.04507
The challenge in video generation using Diffusion Transformer (DiT) models is the high computational cost of 3D attention, which significantly slows down the process. This paper introduces Sliding Tile Attention (STA) to reduce this computational burden and accelerate video generation.
STA leverages the observed locality of attention in pre-trained video DiTs. It efficiently processes attention by operating on tiles instead of individual tokens within local spatial-temporal windows.
-----
📌 STA's tile-based attention smartly aligns with GPU architecture. It converts irregular sparse operations of sliding window attention into dense matrix computations. This significantly boosts hardware utilization and speed.
📌 Sliding Tile Attention directly exploits the inherent redundancy in video data. By focusing computation on local tiles, STA drastically cuts down FLOPs without losing the crucial spatial-temporal context needed for high-quality video generation.
📌 STA offers a practical path to democratize high-resolution video generation. It reduces inference time by up to 3.5x on HunyuanVideo. This makes advanced video AI accessible to wider research and development communities with limited resources.
----------
Methods Explored in this Paper 🔧:
→ This paper proposes Sliding Tile Attention (STA), a novel attention mechanism.
→ STA is designed for efficient video generation in Diffusion Transformer models.
→ It addresses the high computational cost of 3D full attention.
→ STA operates on tiles, which are contiguous groups of tokens.
→ This tile-based approach contrasts with traditional token-wise sliding window attention.
→ STA processes attention within local 3D spatial-temporal windows.
→ It utilizes a hardware-aware sliding window design for efficiency.
→ The method involves a consumer-producer paradigm for data loading and computation similar to FlashAttention3.
→ STA avoids explicit attention masking during computation. Masking is handled by producer warpgroups.
→ This design ensures dense and hardware-efficient computation within consumer warpgroups.
→ STA automatically configures optimal window sizes per attention head through profiling, balancing speed and quality.
-----
Key Insights 💡:
→ Attention scores in pre-trained video diffusion models exhibit strong 3D locality. Attention is concentrated in local spatial-temporal regions.
→ Different attention heads show specialized locality patterns. Some focus on fine details while others capture broader context. This is termed "head specialization".
→ Head specialization is consistent across different prompts. This allows for pre-profiling to determine optimal window sizes.
→ Existing sliding window attention methods are inefficient due to irregular attention masks and masking overhead.
→ STA overcomes these inefficiencies by operating tile-by-tile and eliminating mixed blocks in the attention map.
-----
Results 📊:
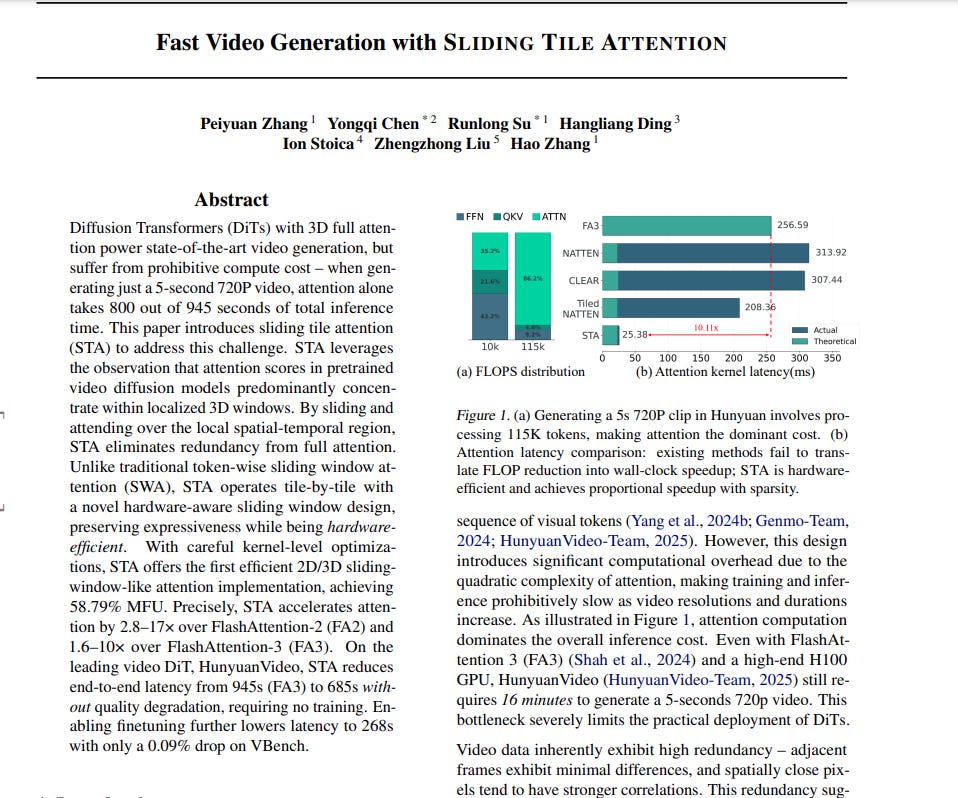
→ STA achieves 2.8–17× speedup in attention computation over FlashAttention-2.
→ STA achieves 1.6–10× speedup in attention computation over FlashAttention-3.
→ End-to-end video generation latency on HunyuanVideo is reduced from 945s (with FlashAttention-3) to 685s with STA without quality loss.
→ Fine-tuning with STA further reduces latency to 268s with a minimal 0.09% drop on VBench quality score.
→ STA achieves 58.79% MFU (Model FLOPs Utilization).