
🧠 Finally feed Claude Sonnet 4 the entire codebase with its new 1 million token context window
Claude hits a million-token context with memory, Figure 02 folds laundry solo, and I break down OpenAI’s gpt-oss architecture.
Read time: 10 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (12-Aug-2025):
🧠 Anthropic’s Claude now has million token context window, 5x the previous limit
🧺 Figure 02- Today we unveiled the first humanoid robot that can fold laundry autonomously
🧑🎓 Deep Dive: Architecture of the OpenAI’s open-source language model gpt-oss
🗞️ Byte-Size Briefs:
Anthropic announced yesterday that Claude is gaining its own memory feature
🧠 Anthropic’s Claude now million token context window, 5x the previous limit
🔧 Claude Sonnet 4 now supports 1M tokens of context, a 5x jump that fits whole repos or dozens of papers in 1 prompt. Pricing rises past 200K tokens to $6 per 1M input and $22.50 per 1M output. Note, Opus does not have the 1M window.
Key Points
Beta status: This is a beta feature subject to change. Features and pricing may be modified or removed in future releases.
Usage tier requirement: The 1M token context window is available to organizations in usage tier 4 and organizations with custom rate limits. Lower tier organizations must advance to usage tier 4 to access this feature.
Availability: The 1M token context window is currently available on the Anthropic API and Amazon Bedrock. Support for Google Vertex AI will follow.
Pricing: Requests exceeding 200K tokens are automatically charged at premium rates (2x input, 1.5x output pricing). See the pricing documentation for details.
Rate limits: Long context requests have dedicated rate limits. See the rate limits documentation for details.
Multimodal considerations: When processing large numbers of images or pdfs, be aware that the files can vary in token usage. When pairing a large prompt with a large number of images, you may hit request size limits.
Long context pricing stacks with other pricing modifiers:
The Batch API 50% discount applies to long context pricing
Prompt caching multipliers apply on top of long context pricing
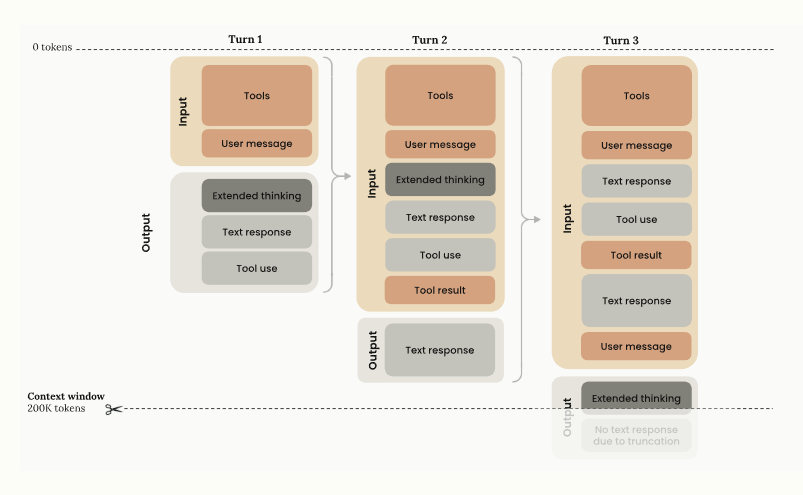
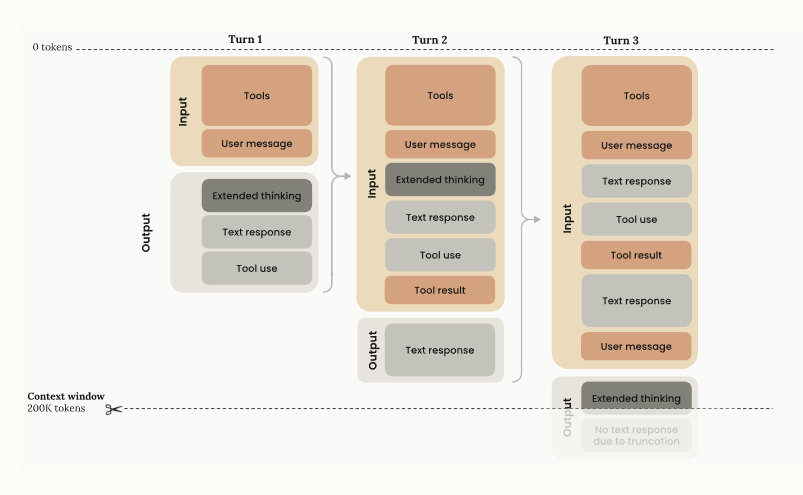
This scale means the model can read about 750,000 words or roughly 75,000 lines of code at once. That lets it map project structure, follow cross-file links, and reason across long specs without chopping context. For research or legal review, it can track references across many documents in a single pass.
Anthropic also talks about the “effective” context window, the portion the model truly understands, not just stores. That matters for agentic coding runs where the model works for minutes or hours, because keeping every earlier step in context reduces drift and rework.
In the wider market, this sits against GPT-5 at 400K, Gemini 2.5 Pro at 2M, and Llama 4 Scout at 10M. The pitch is less about the raw ceiling, more about reliable recall at 1M, practical pricing knobs, and immediate fit for large codebases and long-horizon agents.
Pricing: Requests exceeding 200K tokens are automatically charged at premium rates (2x input, 1.5x output pricing).

Gemini Pro and Flash, by comparison, are far cheaper. For Gemini 2.5 Pro, the cost is $1.25/$10 when usage is under 200,000 tokens, and $2.50/$15 once you go above that limit.
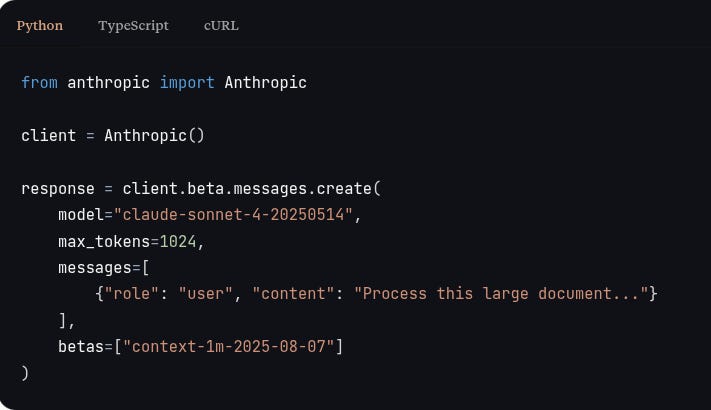
To use the 1M token context window, include the context-1m-2025-08-07 beta header in your API requests:
For the text analysis work, I tested it against Google’s 1-million token context models, Gemini 2.5 Pro and Gemini 2.5 Flash. Claude Sonnet 4 did well overall—it was usually quicker and produced fewer hallucinations compared to the Gemini models. However, for code analysis Gemini is still better at finding the details with the long context.
Industry Dynamics Around Long Context and Anthropic’s Position
Anthropic has built one of the biggest enterprise operations among AI model makers, mainly by selling Claude to coding-focused AI platforms like Microsoft’s GitHub Copilot, Windsurf, and Anysphere’s Cursor. Claude has become a favorite with developers, but GPT-5’s lower cost and strong coding skills could challenge that lead. Anysphere CEO Michael Truell even joined OpenAI in announcing GPT-5, which is now the default model for new Cursor users.
OpenAI earns most of its money from ChatGPT consumer subscriptions, while Anthropic’s revenue relies on selling AI models to businesses through an API. That’s why AI coding platforms are so important for Anthropic—and why it may be adding extra benefits to win users over as GPT-5 gains ground.
Just last week, Anthropic rolled out an upgraded version of its top model, Claude Opus 4.1, boosting its coding capabilities a little further.
More context generally means better performance for AI models, particularly in software development. If the model can see your entire app instead of just part of it, it will likely create better features.
Claude’s large context window allows it to excel at long-running, autonomous coding tasks that can stretch over minutes or hours. This big window lets Claude remember everything it has done during these long problem-solving sessions.
Some AI providers have taken this further. Google’s Gemini 2.5 Pro offers a 2 million token window, and Meta’s Llama 4 Scout goes up to 10 million.
Still, some research suggests huge context windows don’t always translate to better results, since AI models often can’t fully process such massive prompts.
🧺 Figure 02- Today we unveiled the first humanoid robot that can fold laundry autonomously

Figure shows a humanoid folding laundry fully autonomously using the same Helix model that already worked in logistics. No architecture or hyperparameter change, only new data.
Laundry folding is a very difficult problem for Robots because it adds deformable cloth with endless shapes, self occlusion, and constant regrasping that needs fine, real time tactile feedback, which breaks rigid object models.
The famous Moravec's paradox, says robots can ace planned acrobatics, yet climbing stairs or kitchen tasks remain hard because real homes need rich perception and nimble hands that are still tougher than abstract reasoning.
The laundry folding result here fits the paradox, because towels deform, grasp points move, and tiny slips wreck progress. A robot needs precise finger control to trace edges, pinch corners, and smooth fabric in real time.
Helix is a Vision Language Action model from Figure that maps camera frames and instructions to motor commands. It runs end to end, with no object level representations, so it learns finger motions from examples instead of brittle towel models.
With only a new dataset, the same network that reoriented boxes now picks from a pile, adapts strategy, recovers from multi picks, traces edges, pinches corners, untangles, then finishes the fold. That is data only transfer on the same humanoid.
It also learned eye contact, directed gaze, and hand gestures, making human interaction feel natural during work.
This is the 1st humanoid folding laundry fully autonomously with multi fingered hands using an end to end neural policy.
Folding a towel looks simple to a person, but for a robot it is a moving target with thousands of hidden states, messy contact, friction, and self occlusion. Surveys call deformable object manipulation a long standing open challenge because the object keeps changing shape, which breaks rigid object models and planners. Early towel folders at Berkeley could do the task, yet needed slow perception cycles, roughly minutes per item, which is fine for a demo, not for a home.
So Figure Robot’s latest laundry folding achievement hints at a way through it. Using the same policy architecture and swapping in new data treats dexterity as a learning problem, not a hand engineered model of cloth. Vision language action work like RT 2 ( Robotics Transformer 2, is a vision-language-action model from Google DeepMind) follows the same playbook, mapping pixels and words straight to actions so the controller can internalize the hard bits that classical pipelines struggled to write down.
My view, the paradox still holds in spirit. Humans have millions of years of practice wiring up fast, robust perception and finger control, robots do not. But it is shrinking. End to end policies plus lots of real world trajectories are finally buying reliability on deformables, scene clutter, and recovery behaviors. The remaining hurdles are speed, coverage of edge cases, and consistent success across fabrics and setups, which likely need more data, better tactile feedback, and tighter low latency control. That is steady engineering, not magic.
Figure Robots also expanding their natural multimodal human interaction. Helix learned to maintain eye contact, direct its gaze, and use learned hand gestures while engaging with people.
🧑🎓 Deep Dive: Architecture of the OpenAI’s open-source language model gpt-oss

GPT-OSS is a standard autoregressive Transformer with MoE blocks. Each MoE layer has a fixed expert count (128 experts in 120B, 32 in 20B) with a learned linear router that selects the top-4 experts per token via softmax, and uses a gated SwiGLU activation in the MoE feedforward.
gpt-oss is a decoder-only transformer with pre-norm, and it drops dropout entirely. The model keeps the transformer stack but removes dropout because single-epoch training on massive data makes overfitting less of a concern. You can see the decoder-only layout in the side-by-side diagrams on page 4, and the discussion about not using dropout right after that.
Position handling with RoPE
Instead of absolute position embeddings, gpt-oss rotates queries and keys using RoPE. This keeps position signals inside attention itself, which is cheaper and scales better to long contexts than learned absolute vectors. The explanation and sketch are on page 6.
Feed-forward design, SwiGLU not GELU
The feed-forward nonlinearity is Swish, and the whole MLP block is upgraded to a gated variant, SwiGLU. Compared to a classic 2-layer MLP with GELU, SwiGLU reduces parameters for the same hidden size and improves expressivity via multiplicative gating. Pages 8-10 walk through the idea and show code-level shapes that make the parameter savings clear.
Sparse capacity with Mixture-of-Experts
Each transformer block replaces the single MLP with a Mixture-of-Experts. A learned router sends each token to a small subset of experts, so you get large total capacity but only pay compute for a few experts per token. In the 20B model there are 32 experts with 4 active per token, which is “few big experts” rather than “many small experts”. The MoE schematic is on page 11, and the 32/4 detail is discussed on page 20. The 120B model increases the number of blocks and experts while keeping the other dimensions fixed, as shown on page 21.
Attention, made cheaper and longer-context friendly
gpt-oss uses Grouped-Query Attention. Multiple query heads share a smaller set of key/value projections, which cuts KV parameters and shrinks the KV cache with little quality loss. See the side-by-side GQA vs MHA sketch on page 12. On top of that, gpt-oss alternates full-context layers with local sliding-window layers, so every second layer only attends within a window of 128 tokens. This 1:1 alternation, shown on pages 13-14, saves memory and bandwidth while retaining periodic global mixing.
Attention bias terms and “attention sinks”
Two small but interesting choices appear in the attention code. First, the Q, K, V projections keep bias terms. These are often removed in newer stacks, but gpt-oss includes them. Second, the model adds learned per-head “attention sink” logits directly into the attention scores. These sinks act like always-attended slots that stabilize focus in long contexts, without inserting special tokens. The code snippets and explanation are on pages 23-24.
Normalization
Layers use RMSNorm rather than LayerNorm. RMSNorm avoids mean subtraction and standard-deviation division, so it reduces cross-feature reductions and GPU communication. The comparison and code snippets are on pages 15-16.
Width vs depth choices
Relative to peers like Qwen3, gpt-oss-20B prefers width over depth. It uses fewer blocks, larger embedding size 2880, and more heads, which improves tokens/s throughput at some memory cost. The depth/width trade-off and concrete dimensions are summarized on page 19. When scaling to 120B, gpt-oss mainly increases the number of blocks and the number of experts, see page 21.
Deployment-minded weight format
The release includes an MXFP4 quantization path for MoE experts. MXFP4 lets gpt-oss-120B fit on a single 80GB H100-class GPU, and gpt-oss-20B fit on 16GB RTX 50-series, with a fallback to higher-precision formats on older hardware. Practical VRAM figures and caveats are on pages 27-28. This is not “architecture” in the strictest sense, but it is a deliberate design choice around the MoE weights that shapes how the model is used in practice.
Putting it together
In short, gpt-oss modernizes the classic decoder stack with RoPE, RMSNorm, SwiGLU, MoE, GQA, alternating local attention, and small attention extras like bias terms and learned sinks. The 20B variant chooses width and few-but-large experts for speed, the 120B scales blocks and experts for capacity, and MXFP4 makes both practical to host on fewer GPUs.
Why use SinkAttention?
Softmax forces every attention head to put 100% probability on some tokens. When none of the nearby tokens are useful, heads still spread mass across them, which can inject noise. Multiple studies show that models naturally form “sink” positions that soak up attention, often the first token, and this behavior stems from softmax normalization rather than meaning. Making the sink explicit gives each head a clean “none of the above” option. (arXiv, OpenReview)
Benefits that matter for GPT-OSS. When you combine sliding-window layers with dense layers, quality can drop if a head is forced to attend inside a short window. StreamingLLM showed that keeping a tiny set of sink keys restores fluency and lets windowed attention generalize to very long sequences, even millions of tokens, without fine-tuning. A per-head learnable sink provides the same safety valve with almost no overhead, so heads can ignore unhelpful local context while dense layers still mix information globally. (arXiv, OpenReview, Hugging Face)
What others do instead. Most open-source models focus on efficiency rather than adding an explicit sink. The dominant choice is Grouped-Query Attention, which reduces key-value cache size and speeds up inference. It is standard in Llama 3 and widely used in Mistral. Many of these models also use sliding-window attention for some layers to cut cost on long sequences. These tools are popular because they are simple, production-proven, and supported by existing kernels. (Meta AI, Hugging Face, Mistral AI)
Other alternatives aimed at the same pain point. Instead of adding a sink, you can change softmax so that “null attention” is possible. Recent proposals include softmax-1 and Softpick, which modify the normalization to avoid sinks altogether. These are promising but are new in 2024-2025 and not yet widely adopted by mainstream open-source models. (OpenReview, arXiv)
Overall, GPT-oss already alternates sliding-window and dense layers, so giving each head a learnable sink is a low-cost way to avoid forced, noisy attention inside local windows. This matches the empirical finding that sink behavior exists and helps stability in long or streaming settings. Meanwhile, the broader open-source ecosystem mostly standardizes on GQA plus sliding-window attention for speed and memory, leaving explicit sinks as a newer, more targeted refinement. (arXiv, Meta AI)
🗞️ Byte-Size Briefs
Anthropic announced yesterday that Claude is gaining its own memory feature, allowing users to reference other chat history, including by pasting the exact context to reference. A week ago, Anthropic released a small but useful improvement to Claude Sonnet with version 4.1. This is on-demand memory, not a persistent profile. Claude only looks back when you ask it to, and Anthropic says it is not building a user dossier behind the scenes.
Rolling out to Max, Team, and Enterprise plans today, with other plans coming soon. Once enabled for your account you can toggle it on in Settings -> Profile under "Search and reference chats".
Now the question is, after turning this on how much will it increase the token consumption.
The only thing I am missing if voice chat/dictation, being able to just talk through a problem with Claude.
That’s a wrap for today, see you all tomorrow.