Fine-Tuning with Divergent Chains of Thought Boosts Reasoning Through Self-Correction in Language Models
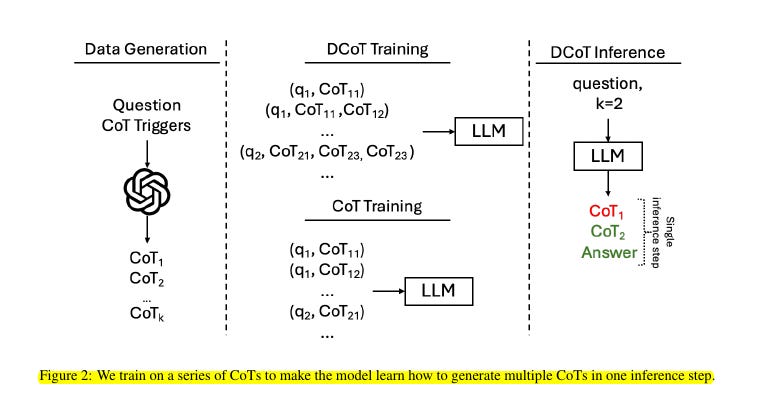
Divergent CoT (DCoT) : Requiring models to compare multiple reasoning chains before generating a solution in a single inference step.


Divergent CoT (DCoT) : Requiring models to compare multiple reasoning chains before generating a solution in a single inference step.
DCoT enhances LLM reasoning by generating multiple chains, enabling self-correction and improving performance across scales.
With this complex reasoning methods can be encoded into LLMs through appropriate instruction tuning.
Original Problem 🤔:
LLMs struggle with complex reasoning tasks. Existing Chain of Thought (CoT) methods generate single reasoning chains, limiting exploration of diverse solutions.
Solution in this Paper 🧠:
• Generates multiple reasoning chains in one inference step
• Compares chains before selecting final answer
• Instruction fine-tunes models on DCoT datasets
• Enables smaller models to benefit from complex reasoning
Key Insights from this Paper 💡:
• DCoT improves performance across model sizes (1.3B to 70B parameters)
• Enables self-correction without explicit training
• Generalizes to unseen tasks
• Compatible with existing CoT extensions
Results 📊:
• DCoT consistently outperforms CoT baseline across tasks and model scales
• Performance gains up to 7.59 points on BGQA for Phi 2
• Improves on unseen tasks: 5+ points on AQuA and SVAMP (Phi 2)
• Enables self-correction: 45% of corrected cases show different reasoning in second chain
• Combines with self-consistency for further gains
🔬 How Divergent Chain of Thought (DCoT) differs from standard Chain of Thought (CoT)?
DCoT requires LLMs to generate multiple reasoning chains before producing a solution in a single inference step.
Unlike standard CoT which generates a single reasoning chain, DCoT generates multiple divergent chains and compares them before selecting a final answer.
This allows the model to explore different reasoning paths simultaneously.