
FlashAttention-3 is now available. 1.5-2.0x faster than FlashAttention-2 with FP16, up to 740 TFLOPS 🤯


Flash Attention-2 was already making attention 4-8x faster, but has yet to take advantage of modern GPUs like H100’s full power.
👨🔧 Now this new Flash Attention-3 is optimized for H100, 75% utilization of H100 theoretical max FLOPS, while FlashAttention-2 could achieve up to 70% theoretical max FLOPS on Ampere (A100) GPUs, and the FA-2 did not take advantage of new features on Hopper GPUs to maximize performance.
👨🔧 With FP8, FlashAttention-3 reaches close to 1.2 PFLOPS, with 2.6x smaller error than baseline FP8 attention.
Key points from the associated Paper
📌 Warp-specialization with circular SMEM buffer: Divides warps into producer and consumer roles. Producers handle asynchronous data movement using Tensor Memory Accelerator (TMA). Consumers perform computation using Tensor Cores via WGMMA instruction. Uses a circular shared memory buffer for efficient pipelining.
📌 2-stage GEMM-softmax pipelining: Overlaps GEMM operations with softmax computation. First WGMMA (QK^T) of iteration j+1 is executed concurrently with softmax of iteration j. Requires careful management of data dependencies and register allocation.
📌 FP8 optimizations: Addresses layout conformance issues for FP8 WGMMA. Performs in-kernel transpose of V tiles using LDSM/STSM instructions. Uses byte permute instructions to transform WGMMA accumulator layout. Employs block quantization (per-block scaling) and incoherent processing (random orthogonal matrix multiplication) to reduce quantization error.
📌 Implementation details: Uses CUTLASS primitives like WGMMA and TMA. Employs setmaxnreg for dynamic register allocation. Careful instruction scheduling to maximize overlap between asynchronous operations.
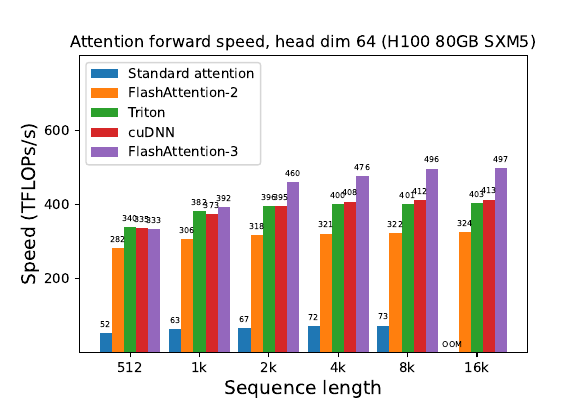
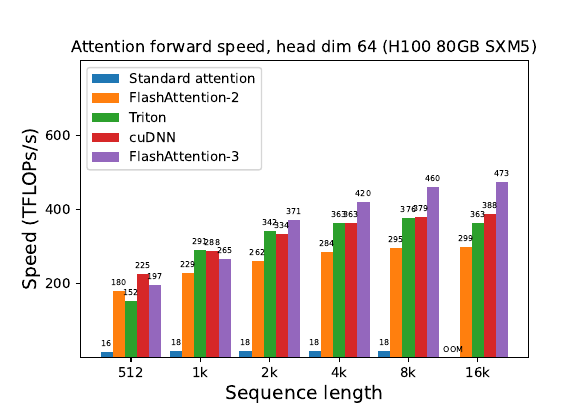
📌 Performance results: Achieves up to 740 TFLOPs/s (75% of theoretical max) for FP16 on H100 GPU. FP8 version reaches close to 1.2 PFLOPs/s. Outperforms cuDNN's optimized implementation for medium to long sequences.
📌 Accuracy improvements: FP16 FlashAttention-3 maintains same numerical error as FlashAttention-2, 1.7x lower than standard implementation. FP8 version with block quantization and incoherent processing reduces error by 2.6x compared to baseline FP8 attention.
Reducing quantization error with incoherent processing in FlashAttention-3

📌 The image shows a table with numerical error comparisons for different attention methods.
📌 For FP16 precision, it shows FlashAttention-2 and FlashAttention-3 both achieve 1.9e-4 RMSE, an improvement over the baseline's 3.2e-4.
📌 For FP8 precision, FlashAttention-3 achieves 9.1e-3 RMSE, a significant improvement over the baseline FP8's 2.4e-2.
📌 The table also shows the impact of block quantization and incoherent processing. Without block quantization, the error is slightly higher at 9.3e-3. Without incoherent processing, the error increases to 2.4e-2, matching the baseline.
📌 LLM activations often have outlier values much larger than typical features, making quantization difficult and error-prone.
📌 Incoherent processing is used to mitigate this issue. It multiplies query and key matrices by a random orthogonal matrix, "spreading out" outlier values.
📌 Specifically, a Hadamard transform with random signs is used. This can be computed in O(d log d) time per attention head, rather than O(d^2).
📌 The Hadamard transform is memory-bandwidth bound, allowing it to be fused with other bandwidth-bound operations like rotary embedding at minimal extra cost.
📌 In experiments with simulated outliers (0.1% of values having large magnitudes), incoherent processing reduced quantization error by 2.6x.
📌 The table shows numerical error comparisons. For FP8, FlashAttention-3 with incoherent processing achieved 9.1e-3 RMSE, compared to 2.4e-2 for the baseline and no incoherent processing.
🗞️ https://tridao.me/publications/flash3/flash3.pdf
Blog - https://tridao.me/blog/2024/flash3/
Github - https://github.com/Dao-AILab/flash-attention