From Generalist to Specialist: Adapting Vision Language Models via Task-Specific Visual Instruction Tuning
A framework that transforms generic vision models into medical experts without losing their versatility


A framework that transforms generic vision models into medical experts without losing their versatility
Original Problem 🤔:
Vision Language Models (VLMs) underperform in task-specific scenarios due to domain gaps between pretraining and fine-tuning. This limits their effectiveness in specialized applications like medical diagnosis.
Solution in this Paper 🛠️:
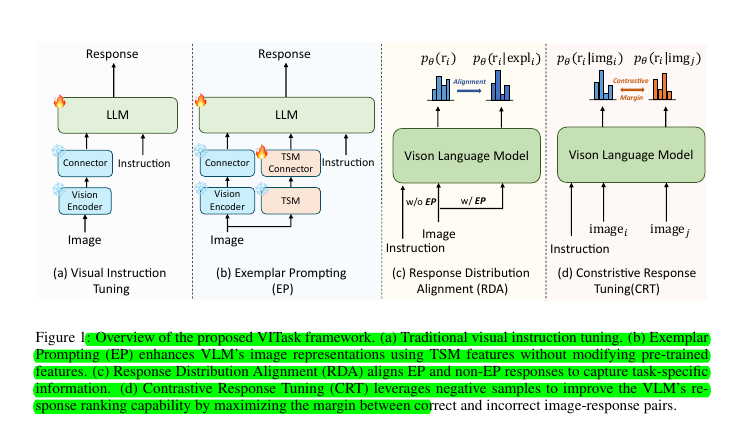
Exemplar Prompting: Uses Task-Specific Model (TSM) features to guide VLMs, enhancing adaptability without altering pre-trained features.
Response Distribution Alignment: Aligns response distributions between exemplar-prompted and non-exemplar-prompted models, enabling VLMs to learn from TSMs implicitly.
Contrastive Response Tuning: Optimizes response ranking by maximizing the margin between correct and incorrect image-response pairs.
Key Insights from this Paper 💡:
VITask bridges the gap between VLMs and TSMs, enhancing task-specific performance.
Exemplar Prompting improves VLM adaptability using TSM features.
Response Distribution Alignment allows learning without TSMs during inference.
Contrastive Response Tuning refines response accuracy and ranking.
Results 📊:
VITask outperforms vanilla instruction-tuned VLMs and TSMs across 12 medical datasets.
Accuracy improvements: PathMNIST (0.953), OCTMNIST (0.952), DermaMNIST (0.877).
F1 score improvements: DermaMNIST (0.772), RetinaMNIST (0.522).
Demonstrates robustness to incomplete instructions and flexibility in integrating different TSM architectures.