
🗞️ Frontier AI can now autonomously chain complex, expert-level cyber attacks end-to-end
Read time: 10 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (30-April-2026):
🗞️ Frontier AI can now autonomously chain complex, expert-level cyber attacks end-to-end,
🗞️ Today’s Sponsor: World2Agent(W2A) is an open protocol that standardizes how Al agents perceive the real world.
🗞️ Google DeepMind’s real-time video AI doctor is here.
🗞️ Anthropic launches ‘Claude Security’ public beta to detect and patch software vulnerabilities
🗞️ The White House has blocked Anthropic’s push to expand access to Mythos
🗞️ Frontier AI can now autonomously chain complex, expert-level cyber attacks end-to-end, at superhuman speed and near-zero marginal cost.

AISI has been running controlled, realistic cybersecurity evaluations on the latest AI models. These include:
Narrow CTF-style tasks (expert-level challenges like exploiting memory corruptions, breaking crypto, reverse-engineering stripped binaries, etc.).
Multi-step “cyber range” simulations — a full 32-step corporate network attack chain (recon → initial access → lateral movement → privilege escalation → full network takeover). A human expert needs ~20 hours for this.

They previously tested Mythos Preview, and now OpenAI’s GPT-5.5.
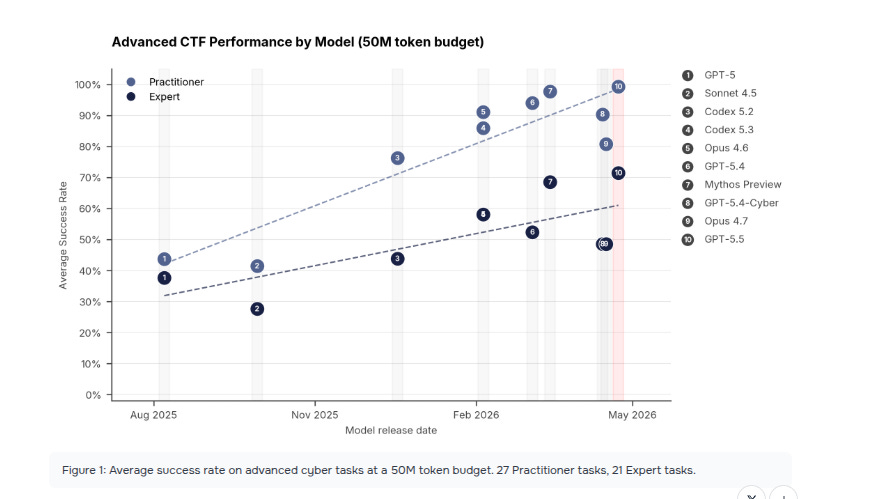
GPT-5.5 is now the 2nd model to complete a full 32-step simulated corporate cyberattack from initial access to full network takeover.
GPT-5.5 essentially tied with Mythos Preview - within the margin of error — both far ahead of earlier models (GPT-4o, Claude Opus 4.x, etc.).
GPT-5.5: 71.4% (±8.0%)
Mythos Preview: 68.6% (±8.7%)
One hard reverse-engineering task (custom virtual machine) takes a human expert ~12 hours with professional tools. GPT-5.5 solved it in under 11 minutes at a cost of $1.73.
The eye-catching result is not just higher scores but long-horizon autonomy, because the model chained reconnaissance, credential theft, lateral movement, a supply-chain pivot, and data exfiltration across roughly 20 hosts.
AISI says performance on the long attack range still rises as token budget rises to 100M, and the best models have not yet hit a plateau, which suggests more compute is still buying more capability.
The report also says basic cyber tasks are already saturated, so the real action has shifted to harder tasks like memory corruption, cryptography, stripped-binary reversing, and exploit development.
GPT-5.5 could not solve the Cooling Tower industrial-control attack range, and AISI says that failure happened in the IT portion, so it does not prove weakness on OT-specific attack steps.
The most alarming safety finding is that AISI found a universal jailbreak that produced blocked malicious cyber content across all tested cyber prompts, and AISI could not verify the final patched configuration because of a setup issue.
Overall, the interesting point is that, the gains appear to come from the same ingredients driving general model progress: longer-horizon planning, better reasoning, stronger coding, and more persistence across many steps.
That makes this feel less like a special-purpose cyber breakthrough and more like spillover from general intelligence improvements. Once a model can hold a plan together, recover from dead ends, and keep using tools coherently, offensive cyber work starts to look like a natural byproduct.
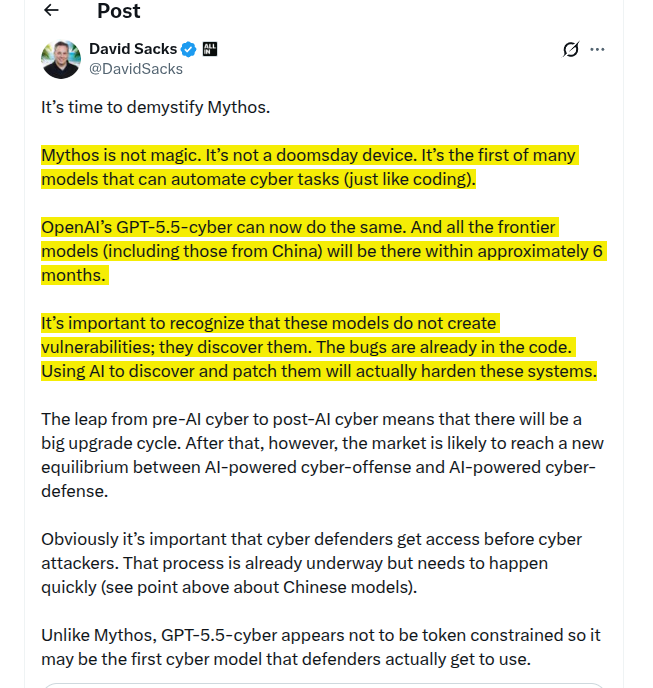
On a related note, David Sacks, co-chair of the US President’s Council of Advisors on Science and Technology (PCAST) tweeted on this result.
🗞️ Today’s Sponsor: World2Agent(W2A) is an open protocol that standardizes how Al agents perceive the real world.

Right now AI Agents have a serious missing layer - agents can act, but they still can’t really notice.
Most agents still wait for a prompt. World2Agent (W2A) changes the setup: sensors watch real-world events, turn them into structured signals, and send them to agents so they can decide and act without someone manually feeding every update.
So W2A has built an open protocol that gives AI agents a standard way to notice real-world events, not just respond after a human tells them something. Sensors provide real-world context. You define the action.
Think GitHub trends, stock moves, Steam deals, meeting changes, research drops, X posts, error logs, or any source that can emit a signal.
Today’s agents are mostly reactive because they lack a perception layer, and builders currently have to manually stitch together polling, webhooks, auth, schemas, deduplication, and delivery logic every time they want an agent to “notice” something.
The important idea is this: tools give agents the ability to act, but sensors give them the ability to know when to act.
W2A wants sensors to emit structured signals in one shared format, so an agent can subscribe to them the way software subscribes to events.
So basically this is the missing infrastructure layer for proactive agents, similar in spirit to what MCP did for tool use.
W2A now works with any agent (e.g. OpenClaw, Hermes), Claude Code, and Codex. Like agent skills, anyone can build their own W2A sensors and reuse sensors built by others.
They’ve also open-sourced the sensors they built, as reference implementations to help developers build more complex sensors for proactive AI agents. W2A Protocol & W2A Sensors are meant to serve as building blocks for the broader proactive AI ecosystem.
Architecture: World → Sensor → Agent
Sensors watch data sources and emit structured data following W2A Protocol. Your agent receives signals and decides what to do. Checkout their Github.
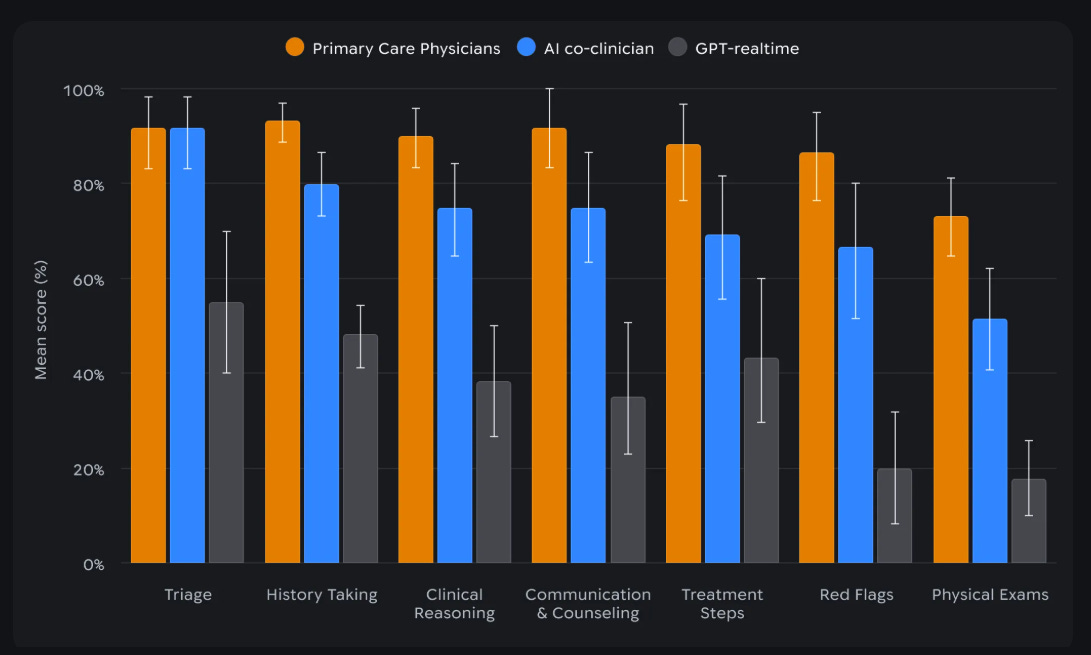
🗞️ Google DeepMind’s real-time video AI doctor is here.

The system is built to retrieve clinical-grade evidence, verify it, and in patient-facing simulations use a dual-agent setup where one module talks while another watches for boundary violations.
It also beat other frontier models on open-ended drug questions, because real medicine arrives as messy patient cases, not multiple-choice exams.
DeepMind evaluated it against the failure modes clinicians actually care about: saying the wrong thing, or failing to surface the crucial thing.
In 98 realistic primary care evidence queries, physicians preferred the co-clinician to leading evidence-synthesis tools, and the system logged zero critical errors in 97 cases under their NOHARM-style evaluation.
🗞️ OpenAI’s Advanced Account Protection Dumps Passwords for Security Keys

OpenAI just rolled out Advanced Account Security, an opt-in mode that turns ChatGPT and Codex accounts into phishing-resistant accounts by replacing passwords and weak recovery paths with stronger identity checks.
OpenAI designed the mode for “people at increased risk of digital attacks,” which could include government officials, corporate executives, researchers, and human rights activists. The Advanced Account Security works by making a user’s account resistant to phishing messages, password guessing, and SIM swap attacks, which is how hackers usually crack online accounts.
The problem is that an AI account now stores chats, work context, connected tools, and sometimes sensitive research or political material, so a stolen inbox, phone number, or browser session can become a direct path to that data.
The fix is - password login is shut off, email/SMS recovery is shut off, and access depends on passkeys, physical security keys, backup keys, and shorter-lived sessions with login alerts.
OpenAI also ties this mode to privacy by making training exclusion automatic for enrolled accounts, and it says members of Trusted Access for Cyber must enable it by 06-26 unless their organization proves phishing-resistant SSO.
🗞️ Anthropic launches ‘Claude Security’ public beta to detect and patch software vulnerabilities

Anthropic has opened Claude Security in public beta for Claude Enterprise customers, turning Claude[.]ai into a codebase scanner that finds vulnerabilities, checks them in context, and drafts patches for review.
Traditional security scanners mostly match patterns, but many serious bugs depend on how data, permissions, and control flow move across files, which is why teams often get both missed issues and piles of noisy alerts.
Claude Security is trying to handle that gap by scanning a repo, validating whether a suspected issue actually holds up, and then returning the severity, affected file and line, explanation, and a suggested fix.
The product is packaged as a built-in workflow rather than a custom security stack, so teams do not need a separate API integration or agent build if they already run Claude Code on the Web inside Claude Enterprise.
The setup is tightly bounded to enterprise controls, including the Anthropic GitHub App, GitHub[.]com repositories, premium user seats, and consumption billing with configurable spend limits.
Teams can scope scans to a branch or directory, run parallel projects, choose Regular or Extended effort, and schedule recurring scans, with Anthropic explicitly recommending narrower scope for large repos and monorepos to improve reliability.
Each finding can be exported to CSV or Markdown, pushed through webhooks or email, opened in a remediation session that generates a candidate patch, or dismissed with a reason that carries forward across future scans.
🗞️ The White House has blocked Anthropic’s push to expand access to Mythos

WSJ reported, that White House Pushes Back Against Anthropic’s Mythos Expansion.
The White House has blocked Anthropic’s push to expand access to Mythos, Anthropic's new powerful model that can reportedly find and exploit software flaws at a level serious enough to trigger national-security controls.
The fight is about who gets to use a model that can help defenders patch bugs faster but could also help attackers find weak points across critical systems.
Anthropic wanted roughly 70 more companies and organizations added, which would have pushed total access to about 120, but officials argued that wider access raises security risk and could strain the compute needed by agencies already using it.
The dispute also shows that Anthropic’s relationship with Washington is still tense, with military-use fights, staffing disputes, and broader distrust shaping who gets near the model. A model that can reliably find and exploit software vulnerabilities is not just another productivity tool.
It compresses the time between discovering a flaw and weaponizing it, which means every decision about rollout becomes a security decision before it becomes a commercial one.
The White House appears to be making two bets at once: that restricting access lowers immediate risk, and that scarce compute should be reserved for agencies already inside the perimeter.
That’s a wrap for today, see you all tomorrow.