Fusion-Eval: Integrating Assistant Evaluators with LLMs
Nice 🗞️ Paper - "Fusion-Eval: Integrating Evaluators with LLMs" is an innovative approach for evaluating Large Language Models (LLMs).


Nice 🗞️ Paper - "Fusion-Eval: Integrating Evaluators with LLMs" is an innovative approach for evaluating Large Language Models (LLMs). Traditional evaluation methods, while useful, are limited in addressing the complex nuances of natural language understanding. Fusion-Eval introduces a new system that integrates various evaluators, including model-based and human-based methods, using LLMs to orchestrate and contextualize their insights.
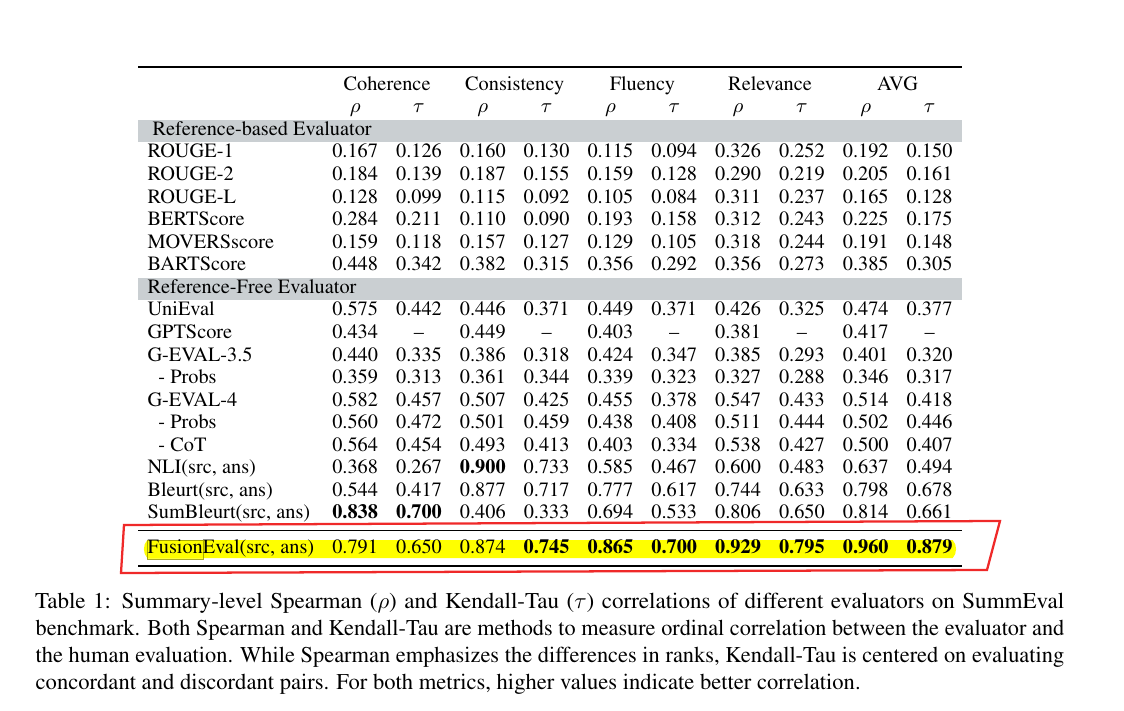
📌 The core innovation of Fusion-Eval is its ability to merge different evaluators to achieve a higher correlation with human judgment. This system employs LLMs to generate evaluation plans and integrate scores from various evaluators based on specific tasks. In testing with the SummEval dataset for summarization tasks, Fusion-Eval achieved a Spearman correlation of 0.96, indicating a close alignment with human evaluations.
📌 Fusion-Eval operates without fine-tuning the LLM. It uses a prompt template for each evaluation task, integrating scores from assistant evaluators and information about the evaluation example. The language model then processes this information to assign scores and rationales for each evaluation category.
📌 The planning aspect of Fusion-Eval is critical. An LLM generates a natural language plan outlining how to evaluate a model response, considering criteria and assistant evaluators. This plan, manually integrated into the prompt template, guides the evaluation process in a structured and coherent manner.
📌 The evaluation template is tailored for each example, explaining the task, the role of assistant evaluators, and the relationship between these elements and the evaluation criteria. This ensures a thorough assessment of attributes like coherence, consistency, relevance, and fluency.
📌 Using OpenAI's GPT-4, the study compared Fusion-Eval’s scores to human evaluations, yielding high Spearman and Kendall-Tau correlations. These results indicate that Fusion-Eval surpasses the performance of individual evaluators, effectively aggregating their scores to align closely with human judgment.
📌 In summary, Fusion-Eval sets a new standard in LLM evaluation, surpassing traditional methods by effectively integrating insights from various evaluators. Its ability to closely mirror human judgment, as demonstrated in experiments, highlights its potential for broader applications in the evaluation of complex language models.