


🤔 RAG (Retrieval-Augmented Generation) in Brief
RAG injects external data into a prompt. It was once essential for large reference texts that didn’t fit into smaller context windows. The model would retrieve small chunks from a vector database and combine them into the final response. It worked well when memory limits were tight.
🚀 Gemini 2.0 Flash’s Huge Context Window
Gemini 2.0 Flash handles 2 million. This capacity eliminates the need for chunk-based retrieval on moderately sized documents. Dump entire transcripts or full-length technical papers into the model. It processes them holistically without fracturing context.
⚙️ Why Traditional RAG Gets Sidelined
Small windows forced chunking. Each chunk was retrieved based on similarity scores, then stitched together. This led to partial context and possible confusion. Gemini 2.0 Flash can scan everything in one sweep, capturing details across the entire document. The outcome is better factual accuracy and fewer hallucinations.
📁 Handling Large Document Sets
RAG still appears if you store hundreds of thousands of documents. Even Gemini 2.0 Flash can’t eat all of them at once. The modern approach:
Filter for relevant files first.
Feed each complete document into separate model calls.
Merge responses after the model has processed entire files.
That strategy replaces old chunk-by-chunk retrieval with a more thorough full-document method.
Below is one way you might implement that approach in Python. In this example, we assume you have a collection of document dictionaries (each with a date, title, and full content). The code:
Filters for documents relevant to Apple’s earnings calls from 2020–2024.
Processes each document (for example, by sending its full text to an AI model) in parallel.
Merges the individual responses and then synthesizes a final answer.
You can replace the placeholder functions with actual calls to your search/index system and AI model APIs.
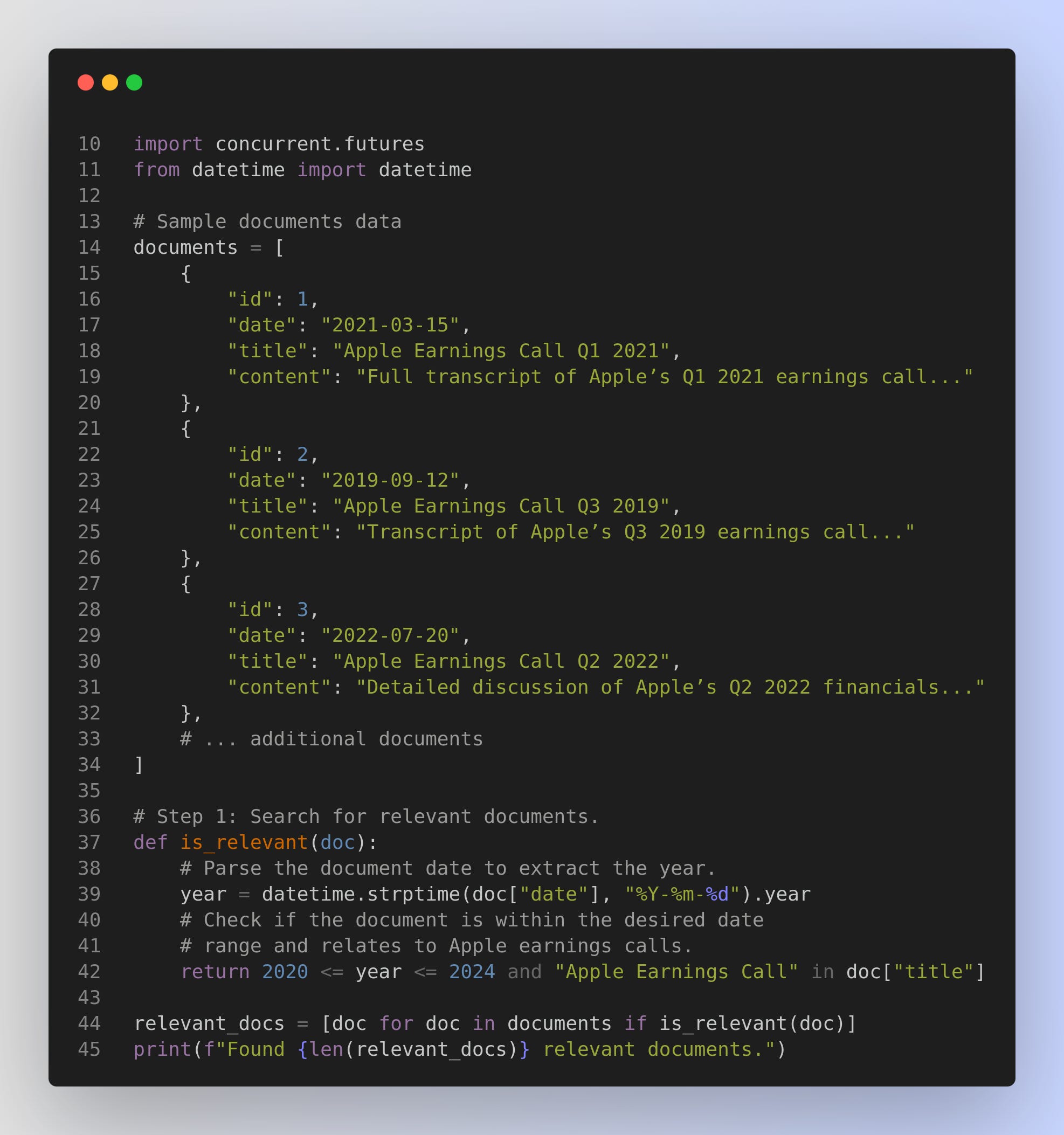
Step 2: Process each document separately in parallel.
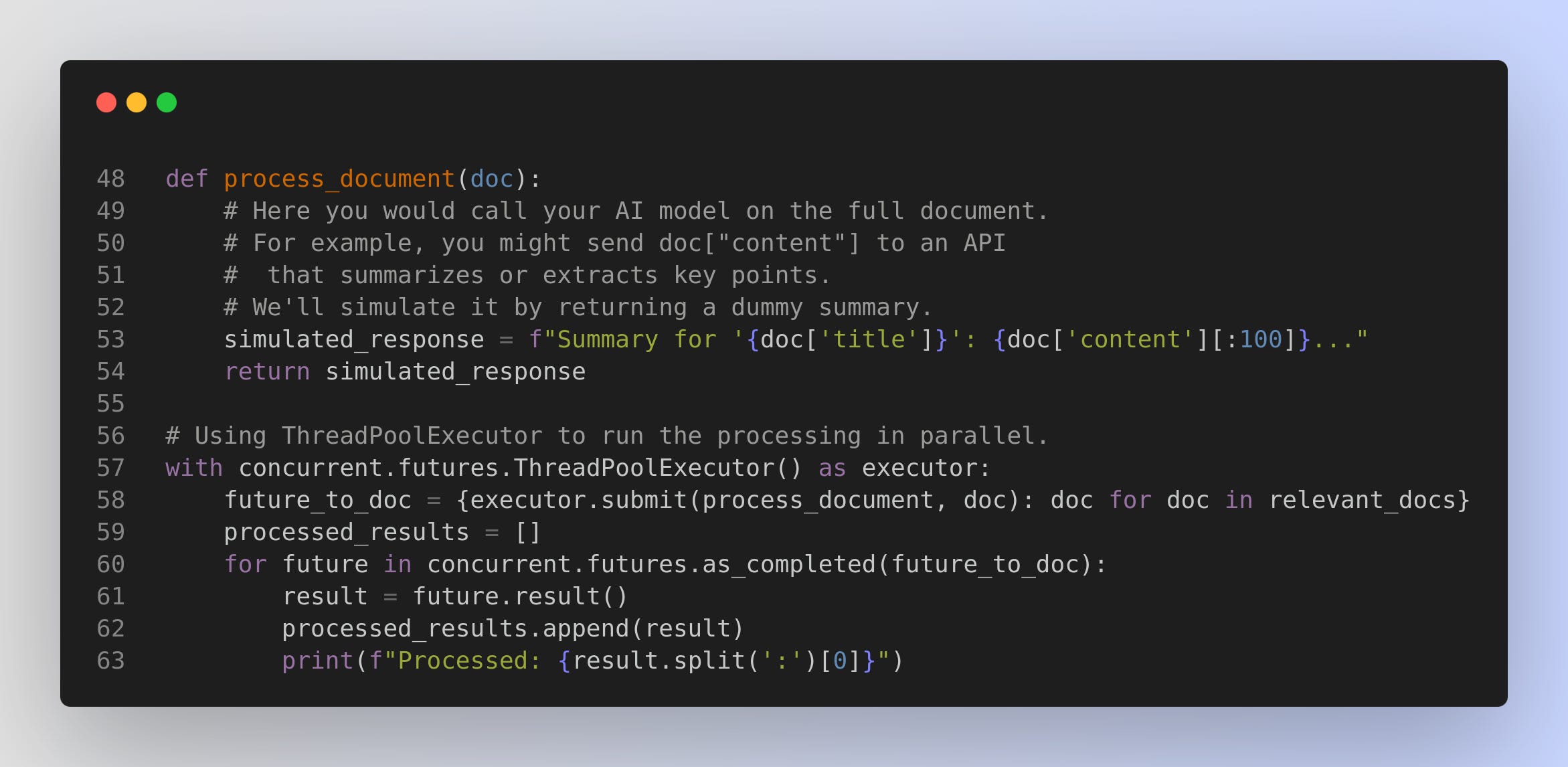
Step 3: Merge the individual responses.
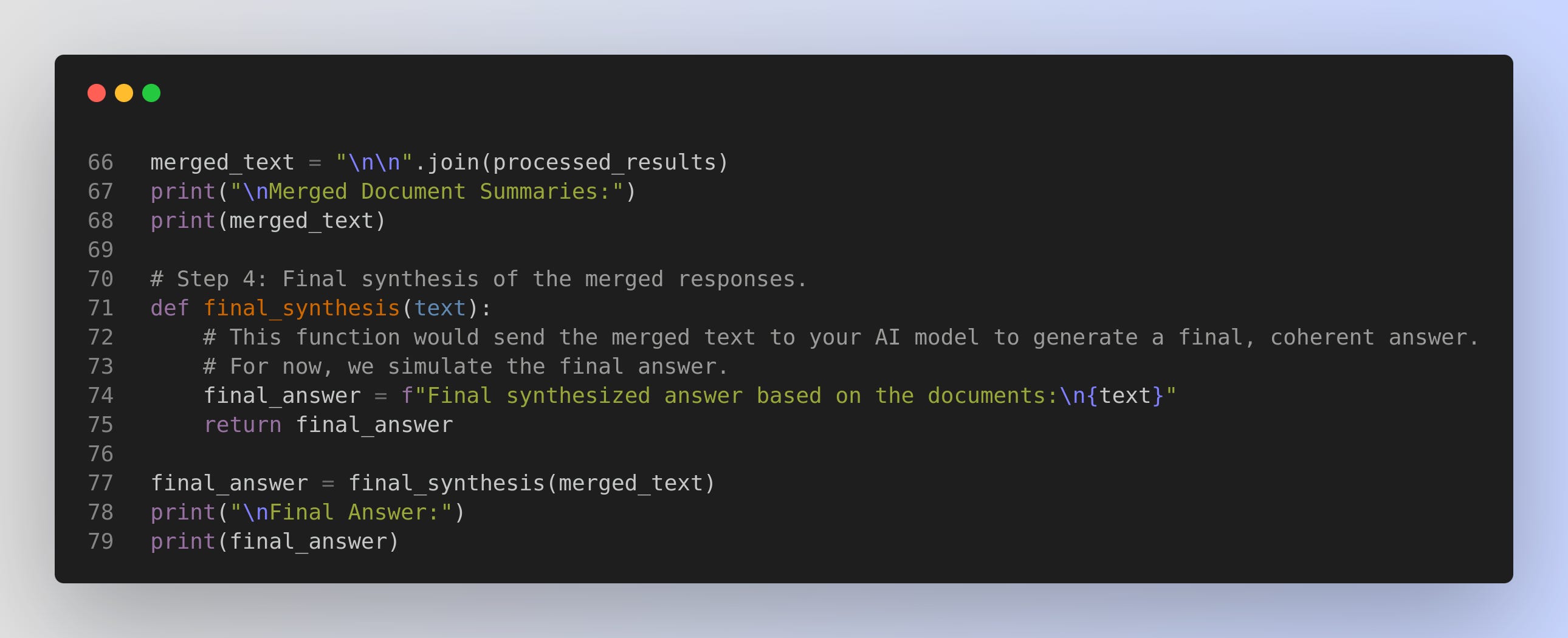
How It Works
Filtering: We define an
is_relevantfunction that checks each document’s date (ensuring it falls within 2020–2024) and its title (to confirm it is an earnings call).Parallel Processing: The
process_documentfunction represents a call to your AI model for processing full documents. Usingconcurrent.futures.ThreadPoolExecutor, we submit all relevant documents for processing concurrently.Merging & Final Synthesis: After collecting the individual responses, we merge them into one text block and then pass that merged text to a final synthesis function (which would typically be another call to your AI model).
This pattern ensures the AI sees entire documents rather than disconnected chunks, enabling better contextual reasoning across the full content. You can replace the simulated parts with your actual model calls or API integrations.