
🧠 Gemini 3.0 Pro and Gemini 3 Deep Think just jumped to the top of the ARC-AGI reasoning leaderboard
Gemini 3 tops ARC-AGI, Membrane automates app integration, $45B Nvidia-MS-Anthropic deal, Bezos returns as CEO, and China leads in open-source.

Read time: 10 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (19-Nov-2025):
🧠 Gemini 3.0 Pro and especially Gemini 3 Deep Think just jumped to the top of the ARC-AGI reasoning leaderboard.
👨🔧 Membrane just launched - makes software self integrate, from OAuth to webhooks to reliable production workflows.
📢 TODAY’S SPONSOR: Dimension, the AI coworker that actually ships your routine work
🚨 Nvidia, Microsoft, and Anthropic announce new strategic AI partnerships of roughly $45 Billion.
🏭: Jeff Bezos is officially wearing the CEO badge again.
🇨🇳 China is absolutely dominating the open-source world.
🧠 Gemini 3.0 Pro and especially Gemini 3 Deep Think just jumped to the top of the ARC-AGI reasoning leaderboard with much higher scores than other frontier models at very different costs per task.
ARC-AGI benchmarks are puzzle-like tests that force a model to infer hidden rules from small grids and then generate the correct missing pattern, so they stress systematic reasoning instead of memorized knowledge. ARC-AGI-2 is a newer, harder version where previous leading systems sat around low double digit scores, so moving from ARC-AGI-1 to ARC-AGI-2 used to cause a big drop in performance.
On ARC-AGI-2, Gemini 3 Pro reaches 31.11% at about $0.81 per task, which is roughly a 2X jump over earlier state of the art while staying in a reasonable cost range. The Gemini 3 Deep Think preview hits 45.14% on ARC-AGI-2 at about $77.16 per task, using a very expensive long-thinking mode that spends a lot of compute to squeeze out extra correct solutions.
On the easier ARC-AGI-1 benchmark, Gemini 3 Pro scores 75% at $0.49 per task and Deep Think hits 87.5% at $44.26, so the drop from ARC-AGI-1 to ARC-AGI-2 is now much smaller, which means the models scale better to harder puzzles. The leaderboard image shows most other models like GPT-5 Pro, Claude Sonnet 4.5 Thinking, Grok 4 Thinking and o3 variants clustered below these scores, often at similar or higher costs, while the Gemini 3 points sit noticeably higher. The ARC team also notes that these same systems still miss some very easy ARC-AGI-1 problems that humans solve instantly.
👨🔧 Membrane just launched - makes software self integrate, from OAuth to webhooks to reliable production workflows.

If you’re still shipping integrations the old way, your engineering time is stuck on OAuth, pagination, and webhooks instead of product work. 🤔 Integration backlogs kill deals.
🛠️ So Membrane is building the future where software self-integrates.
You can literally scale to 100+ integrations without scaling the team. Membrane is a new approach that turns plain English requests into production-ready integration packages that teams fully own.
It pairs an AI integration builder that understands intent with an execution layer that handles auth, retries, paging, and error paths by default. The Agent chooses APIs, fields, and data shapes from a request like “sync HubSpot contacts on update,” then lays down the webhooks, transforms, and guardrails.
The Engine runs that plan with actions for single API calls, flows for multi step jobs, and events for real time triggers, with testing and observability built in. Universal models and field mappings keep data consistent across services, and data collections provide cached state so syncs are fast and predictable.
Output arrives as a Membrane Package, which is full source in your repo with docs, metrics, and tracing, so there is no lock in and you keep the code. This contrasts with embedded iPaaS that hides logic in a UI and with unified APIs that force lowest common data, because here you get generated code plus a runtime that adapts.
⚙️ The Core Concepts: The system relies on Membrane Agent, which acts like a specialized senior engineer dedicated solely to building connections. You give the Agent a natural language command, such as “Sync contacts from HubSpot whenever they are updated.”
The Agent then identifies the correct API calls, handles authentication methods like OAuth, and manages data structures without you needing to read the documentation. It understands technical nuances, such as the difference between REST and GraphQL protocols, and automatically handles pagination and rate limiting.
📢 TODAY’S SPONSOR: Dimension, the AI coworker that actually ships your routine work
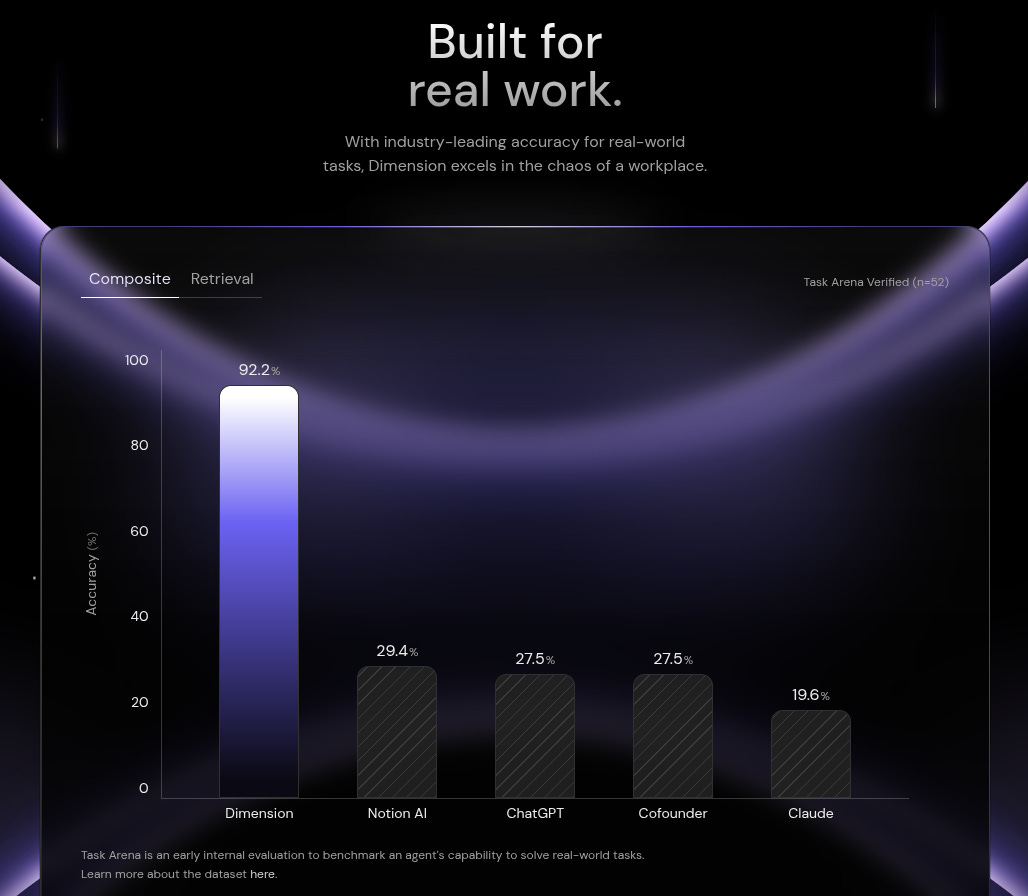
Moving between an AI chat window and other office tools (Gmail, Slack, Notion etc), has been such a pain point since AI arrived. And Dimension seems to be solving this.
Just used newly launched Dimension and feels like a genuinely brilliant timesaver for office AI. Checkout their launch demo video.
It’s a powerful AI office co-worker with predictable results that runs prebuilt and custom workflows to handle planning, email, docs, meetings, and engineering tasks, so routine work gets done without manual steps. Dimension connects to tools like Gmail, calendar, Linear, Notion, and Vercel, then executes multi step automations on a schedule or when an event hits, for example a new email or a meeting ending.
Each workflow chains skills, like reading inbox state, classifying urgency, drafting messages, creating tickets, and updating documents, so the outcome is a finished artifact rather than loose suggestions. I can trigger actions in plain language, for example clearing a calendar, notifying a team, or preparing a status brief, and the agent follows through across accounts with confirmations.
Under the hood, the value it brings is orchestration, the agent keeps context about me, my team, and past work so it can route tasks, pick owners, and fill templates with the right fields.
🚨 Nvidia, Microsoft, and Anthropic announce new strategic AI partnerships of roughly $45 Billion.

Claude will scale on Azure using NVIDIA systems, which expands access for enterprises and makes Claude available across the major clouds. Anthropic and NVIDIA will co-design to tune both model stacks and future chips for performance, efficiency, and total cost of ownership, so the models run faster per dollar.
The first wave targets NVIDIA Grace Blackwell and Vera Rubin systems, which pair high-bandwidth memory with dense interconnect to push training and inference throughput. Microsoft will expose Anthropic models in Azure AI Foundry, including Claude Sonnet 4.5, Claude Opus 4.1, and Claude Haiku 4.5, so teams can pick latency and cost profiles.
Claude will also remain available across the Copilot family, which means coding, document automation, and workflow agents can call the same model line. The 1GW commitment signals many thousands of GPUs worth of capacity, which reduces queue times and stabilizes unit economics for long-running training runs. The joint optimization loop, models shaping chips and chips shaping models, typically yields double-digit efficiency gains over off-the-shelf deployments.
🏭 Jeff Bezos is officially wearing the CEO badge again.

Prometheus is about AI that designs parts, plans builds, runs tests with robots, learns from results, then repeats faster than human only workflows, with a tight loop of propose, fabricate, measure, and update. Leadership pairs Bezos with Vik Bajaj, who previously built frontier R&D groups at Google X, Verily, and Foresite Labs.
Prometheus already has nearly 100 hires, including researchers from OpenAI, DeepMind, and Meta, which shortens the ramp for model training, simulation, and control stacks. Funding size matters because training physics aware models and operating automated labs burn capital on compute, custom rigs, materials, and high cadence experimentation.
The target differs from standard chatbots that learn from text alone, since these systems also learn from physical experiments where outcomes push the model toward designs that actually work in the real world. Think of it as coupling generative design, high fidelity simulation, and closed loop robotics so the AI proposes candidates, screens them in sim, fabricates the best few, measures gaps, and retrains for the next cycle.
Rivals are moving, like Periodic Labs with automated discovery lines and Thinking Machines Lab with $2B, so execution speed and data advantages will decide who builds the strongest feedback loop. If Prometheus links design data, manufacturing telemetry, and test results into one continuous dataset, it can cut iterations and raise yield for complex assemblies.
🇨🇳 China is absolutely dominating the open-source world.

Many top Silicon Valley companies are choosing Alibaba’s Qwen as their shortcut, as you can see from the above chart. Qwen leads by a great margin.
Chinese models are also winning over customers as geopolitical and cybersecurity concerns take a backseat to factors like cost, efficiency, and ease of use. And derivative models (finetuned or otherwise modified models) built on Chinese base foundations now absolutely exceed those built on US and European models. Alibaba towers over everyone from late 2024 into mid 2025, with around 5000 to 6000 Alibaba based derivatives in its peak month, several times the uploads built on Meta, Microsoft, Google, or OpenAI models.
👨🔧 xAI launches Grok 4.1 with lower hallucination rate on the web and apps — no API access

xAI keeps the Grok reasoning core and trains reward models that score answers for tone, clarity, and instruction-following, then uses reinforcement learning so the model produces more controlled, helpful text.
On human preference leaderboards, Grok 4.1 Thinking sits around 1483 Elo and the non-thinking mode in the mid 1400s, which is near the top of public systems. The 2 configurations differ because the Thinking mode spends extra internal steps to plan and check reasoning, while the fast mode skips that work for low-latency direct answers.
Reliability jumps, with hallucination rate dropping from 12.09% to 4.22% and FActScore error shrinking from 9.89% to 2.97%, so factual answers fail less often.
Under the hood, Grok 4.1 supports about 1M tokens of context, cuts token latency by roughly 28%, strengthens multimodal skills on images and video, and can run tools in parallel to shorten research flows.
Safety tests show very low false negatives on restricted chemistry and biology prompts and 0% attacker success on persuasion benchmarks, pointing to strong robustness against jailbreak and prompt-injection attempts.
That’s a wrap for today, see you all tomorrow.