
Gemini Advanced Memory Features, OpenAI's 3K/week Thinking Prompts and more
GPT-5 gets user control modes, huge Thinking limits, Gemini rolls out memory features, OpenAI plus Gmail integration, Mistral 3.1 launch, and new GPT-5 IQ benchmarks.

Read time: 10 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (13-Aug-2025):
🧠 OpenAI added user controls to switch Auto, Fast, Thinking in GPT-5. It also set new huge limits for GPT-5 Thinking
🎯 Gemini Advanced Memory Features and Personalization Releasing Today Rollout starts on 2.5 Pro
📡 “GPT-5 Set the Stage for Ad Monetization and the SuperApp” - New Report from Semi Analysis
🛠️ Resources: Advanced Reinforcement Learning
🗞️ Byte-Size Briefs:
ChatGPT Pro users can now link Gmail, Google Calendar, and Google Contacts
Mistral launches Medium 3.1 with improvements in performance, tone, and web searches.
GPT-5 Pro has 148 IQ in Mensa Norway and 116 IQ in the Offline Test
🥊 Opinion: How China’s Free Models Are Forcing a U.S. Rethink
🧠 OpenAI added user controls to switch Auto, Fast, Thinking in GPT-5. It also set new huge limits for GPT-5 Thinking

OpenAI now gives users the ability to choose between Auto, Fast, and Thinking modes for GPT-5.
GPT-5 is a unified system with a standard model for most tasks, a deeper GPT-5 Thinking layer for hard problems, and a router that picks based on input complexity or an explicit request. Auto lets the router decide, Fast favors low latency, Thinking allocates extra reasoning steps for tougher prompts.
OpenAI capped GPT-5 Thinking at 3,000 messages/week, then grants overflow on GPT-5 Thinking mini. The context window limit is 196,000 tokens. Model access shifted, with GPT-4o back by default for paid users, and also a toggle to show o3, 4.1, and GPT-5 Thinking mini, and GPT-4.5 reserved for Pro due to GPU cost. OpenAI is making a warmer tone and per-user personality.
Also Sam Altman takes Musk rivalry to new level as OpenAI backs firm to challenge Neuralink. A new company called Merge Labs to develop brain-computer interfaces competing with Elon Musk’s Neuralink with Sam Altman as co-founder.
Merge Labs seeks to raise $250 million at an $850 million valuation, with significant investment expected from OpenAI’s ventures team.
Merge focuses on high bandwidth brain computer interfaces, which means many channels reading and writing neural signals at high data rates. More channels and better models raise accuracy, cut latency, and make real time control feel natural. That enables faster cursor control, clearer speech decoding, and richer feedback, without long calibration.
Neuralink leads this market today, with a recent $650M raise and a $9B valuation. Precision Neuroscience and Synchron are also pushing hard, so the field is moving from lab demos to real products.
🎯 Gemini Advanced Memory Features and Personalization Releasing Today Rollout starts on 2.5 Pro
Google adds Personal context, Temporary Chats, and new Keep Activity controls. Rollout starts on 2.5 Pro, 2.5 Flash follows.
Personal context lets Gemini use past chats to learn preferences, then tailor replies. The setting is on by default, change it in Settings, Personal context, Your past chats with Gemini. Personalized conversations begin on 2.5 Pro in select countries, expanding to 2.5 Flash soon.
Temporary Chats are for quick 1 off conversations. They do not appear in history, do not personalize, and do not train Google’s models. They are kept for 72 hours only to answer and process feedback.
Keep Activity is the new name for Gemini Apps Activity. When Keep Activity is on, Gemini may use a sample of your future uploads, like files and photos you send to Gemini, to help improve Google services.
If you do not want your uploads used this way, turn Keep Activity off. You can also use Temporary Chats for quick, private conversations that do not personalize your Gemini experience and do not train Google’s models.
There is a separate control for audio, video, and screen shares that you send through the mic button or Gemini Live. That control is off by default, so unless you turn it on, those recordings are not used to improve services.
Short version, Keep Activity controls uploads, Temporary Chats keep a session private, and media sharing stays off unless you enable it.
So if all these previous chats are remembered, how does that fit within the fixed context window?
The context window is just the model’s short-term workspace for this 1 reply, while Personal context is a separate long-term memory store the app maintains outside the window. The app only pulls a small, relevant slice of that memory into the prompt so it fits the window. Google describes long context at the model level, but the app’s personalization is a retrieval and summarization layer on top, not a full chat dump.
Here is the rough playbook most assistants, including Gemini, use. The app extracts facts and preferences from past chats, saves them as compact notes, then scores them for relevance to your new question using embeddings, recency, and type signals, like “stable preference” vs “one-off request.” It deduplicates and summarizes overlaps, then injects only the top notes plus a tiny profile line into the system prompt. If the task itself is long, it shrinks or drops the lowest-score notes first to stay within the window. Google states the feature learns from past conversations and is on by default, with a clear toggle in Settings.
Conflicts are handled simply. The app prefers the most recent or highest-confidence memory when 2 facts disagree, or it asks for clarification. Temporary Chats are excluded from memory and from training, and they expire after 72 hours used only to respond and process feedback.
Privacy knobs sit next to this. Personal context controls whether past chats inform answers. Keep Activity (new name for Gemini Apps Activity) controls whether a sample of future uploads like files or photos can be used to improve Google services. Media sharing from the mic button or Gemini Live has its own switch, off by default.
Short version, the window stays fixed, the memory is curated, and only a tiny, relevant summary gets injected, so it scales without stuffing your whole history into every prompt.
📡 “GPT-5 Set the Stage for Ad Monetization and the SuperApp” - New Report from Semi Analysis

According to Semi Analysis latest report "OpenAI is Creating a Consumer SuperApp. For GPT 5, the real release is focused on the vast majority of ChatGPT’s free users, which is the 700m+ userbase that is growing rapidly. OpenAI is firmly knocking on the door of technology giants Google and Meta and even Amazon. Previous scares about AI have been focused on search query volume, not being replaced in the ad tech stack."
They basically said OpenAI’s GPT-5 drop is really about the router, not raw model size. It cuts cost, exposes thinking models to free users, and sets up agentic purchasing that can monetize 700M+ people. And that’s why to many power users (Pro and Plus), GPT5 was a disappointing release.
The router is the release. The router sits in front of GPT-5’s models. It picks a mini model for easy questions, a deeper reasoning model for hard ones, and it learns from signals like model switches, user preferences, and measured correctness. That single control point upgrades quality for everyday users while lowering serving cost, because cheap queries get cheap compute and tough ones get more compute only when needed.
Report says in future, ChatGPT will act as an agent that plans purchases, compares options, contacts sellers, and checks out on the user’s behalf. The router will flag high-intent queries, allocates more compute, triggers tool use, and earns revenue via commissions or affiliate fees when transactions complete, monetizing free users.
So, is the router being trained for commissions right now, strictly speaking, no. It is being trained for cost and quality control today. The report is saying, in future, the router makes it straightforward to add commercial value as a new signal next, which would unlock agentic purchasing inside ChatGPT.
🛠️ Liquid AI just released vision-language foundation models for edege devices like smartphone
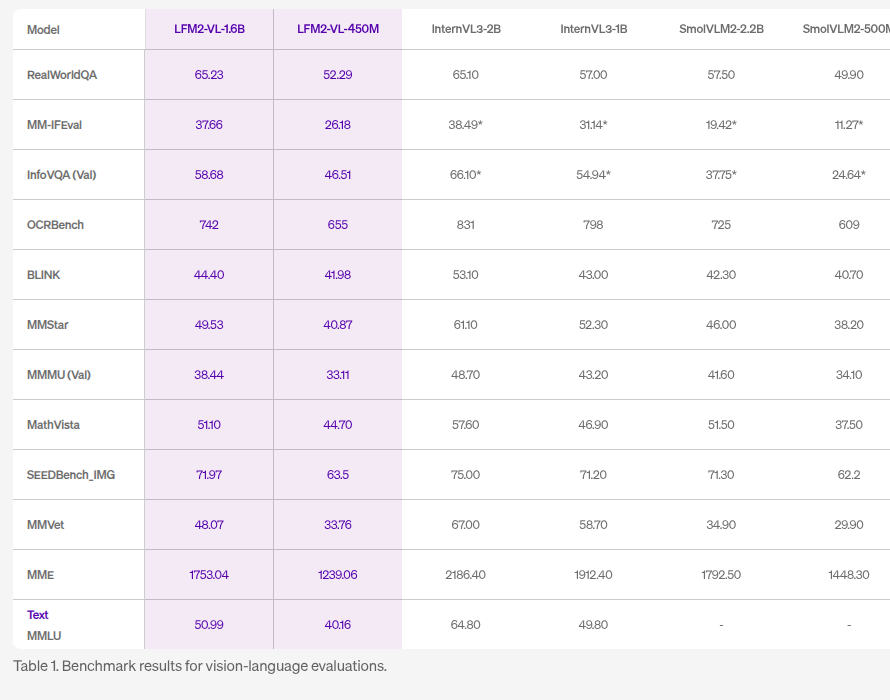
Liquid AI has released LFM2-VL, a new generation of vision-language foundation models designed for efficient deployment across a wide range of hardware — from smartphones and laptops to wearables and embedded systems.
Available on huggingface with Apache 2.0–based license. Unlike traditional architectures, Liquid’s approach aims to deliver competitive or superior performance using significantly fewer computational resources. According to Liquid AI, the models deliver up to twice the GPU inference speed of comparable vision-language models, while maintaining competitive performance on common benchmarks.
The models extend Liquid AI’s LFM2 system into multimodal processing, handling both text and images at native resolutions up to 512×512.
They use a modular design with a language backbone, a SigLIP2 NaFlex vision encoder, and a lightweight multimodal projector that compresses image tokens for speed. Larger images are split into patches and paired with thumbnails for context, preserving both detail and overall scene understanding.
Two versions target different needs: LFM2-VL-450M is under half a billion parameters for constrained devices, while LFM2-VL-1.6B offers more capability but still fits single-GPU or mobile deployment.
Both allow tuning of image token limits and patch counts to balance speed and quality without retraining.
Training combined 100B multimodal tokens from open and synthetic datasets, with a staged blend of text and image learning. On benchmarks like RealWorldQA and OCRBench, the models score competitively, while GPU inference tests show up to 2× faster performance than similar models.
🛠️ Resources: Advanced Reinforcement Learning
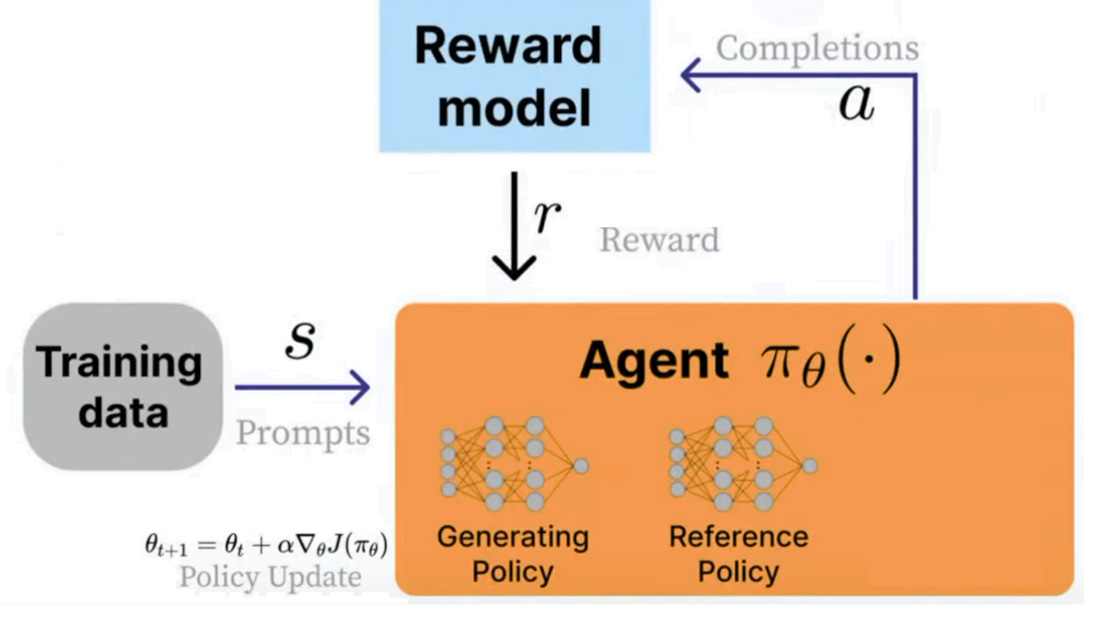
These slides cover a 3 hour workshop on training LLMs with reinforcement learning, kernels, agents, and quantization. They explain RL for LLMs, from RLHF and PPO to GRPO and RLVR, showing how rewards, baselines, advantage, KL penalties, and trust regions guide likelihood shifts. It highlights rollouts and group relative Z-scores that remove the value model.
Key learnings: use verifiable rewards to avoid reward hacking, bound updates with a trust region plus KL control, prefer GRPO when value models are costly, measure advantage with per group Z-scores. For deployment, apply dynamic GGUF quantization, quantize MoE layers heavily while keeping attention in higher precision, and use torch.compile for speed.
🗞️ Byte-Size Briefs
ChatGPT Pro users can now link Gmail, Google Calendar, and Google Contacts, so the AI can bring up relevant emails, events, and people during conversations. OpenAI’s Connector system makes this possible by linking ChatGPT to third-party services. Previously, Dropbox was supported, and now Google’s suite joins the list. The rollout starts with Pro accounts globally this week, and Plus, Team, Enterprise, and Edu users will get it soon after. Connectors can be activated by going to Settings → Connectors → Connect in the app. If you’ve granted deep research access before, no extra setup is needed.
Mistral launches Medium 3.1 with improvements in performance, tone, and web searches. is live on Le Chat or through their API library (`mistral-medium-2508`). Note, its not an open source model, but benchmark numbers improved over the previous version.

GPT-5 Pro has 148 IQ in Mensa Norway 116 IQ in the Offline Test. It is a timed, practice IQ quiz made by Mensa Norway. You get 35 visual pattern puzzles, all non-verbal, with a 25-minute limit. Every correct answer is worth 1 point, the items get harder as you go, the reported IQ range is 85 to 145 with Standard Deviation 15. What it measures is matrix-reasoning style, non-verbal abstract reasoning, the same family as Raven’s Progressive Matrices that psychologists use to estimate fluid intelligence and general reasoning ability.



🥊 Opinion: How China’s Free Models Are Forcing a U.S. Rethink

🧭 What just happened
China pushed a wave of open-weight models that anyone can download and modify, then followed up with more in July, and it is bending adoption its way. This streak starts with DeepSeek-R1 in January, then big upgrades like Alibaba’s Qwen3, plus new entrants like Moonshot’s Kimi K2, Z.ai’s GLM-4.5, and MiniMax-M1. U.S. teams felt the pressure, so OpenAI finally released gpt-oss in early August. That one move turned “open weights” from a China-plus-Meta story into a full arena with U.S. players, regulators, and clouds leaning in.
Washington also shifted. The White House published an AI Action Plan in July that explicitly backs open-source and open-weight models and warns they could set global standards if the U.S. drags its feet. That is a big policy nudge for agencies and vendors to build on open models, and it is a recognition that standards often come from what ships broadly, not only what scores highest in a lab.
🔓 What “open weight” actually buys you
Open weight means you can pull the model weights, run them on your own hardware, tune them, and bake them into products without phoning home. That gives you control over latency, privacy, and unit economics. OpenAI’s gpt-oss-20B can run on a single machine with 16GB memory, while gpt-oss-120B is engineered to fit a single 80GB GPU thanks to quantization, so teams can actually host it without a distributed setup. The models expose full chain-of-thought, support tool use, and stretch to 131,072 tokens of context.
The availability story matters as much as the tech. gpt-oss is now on AWS, with Amazon claiming big price-performance gains vs other models, and it is also easy to run locally with Ollama and vLLM. This turns “try it this afternoon” into a default, which is how standards spread.
Why “easy to get and bend” scares Washington and Silicon Valley
Open-weight models slash friction. If you can download weights, fine-tune locally, and deploy inside your own perimeter, adoption jumps. This is exactly why Chinese open-weight families getting broad distribution trigger anxiety, because distribution plus flexibility is how technical standards take root. U.S. teams responded with gpt-oss, which put an American open-weight on the field and narrowed the convenience gap for anyone who prefers a domestic option.
🐉 China’s playbook
China is treating openness as practical resilience. The state and major firms push open ecosystems across operating systems, chip architecture, and AI tooling, so that companies have a fallback if they are cut off from Western tech. That includes OpenAtom Foundation efforts like OpenHarmony, plus a nationwide push on RISC-V. The same instinct shows up in models, where open weights seed global usage and community support quickly.
🛠️ The U.S. pivot, concrete moves
The Action Plan’s message is clear, build leading open models founded on American values, encourage agencies and businesses to use them, and remove friction for deployment. In parallel, OpenAI shipped gpt-oss, and major clouds started listing it so enterprise teams can test, price, and swap models with fewer hurdles. This is how you compete with a distribution-led strategy, you make the default choice cheap, easy, and safe enough to pass procurement.
The leverage on both sides, chips vs minerals
This trade fight has showed each side where its levers are. The U.S. uses advanced AI chip export controls and tight licensing around Nvidia and peers. China uses rare earth and critical mineral controls as a counterweight, adding paperwork, delays, or bans on materials that sit under everything from magnets to semiconductors. Standards battles ride on these supply levers, because whoever controls key inputs can tilt the playing field during crucial adoption windows.
📏 Reality check: performance, size, and cost
Benchmarks this summer show Alibaba’s Qwen3 still edging out U.S. open weights at the very top end, but at a larger total scale. Qwen3’s flagship 235B Mixture-of-Experts setup often activates around 22B parameters per token, while gpt-oss-120B activates 5.13B. That gap explains why Qwen3 can top some leaderboards while gpt-oss can feel leaner in everyday serving. Different tradeoffs, different wins.
Independent trackers highlight this split, with Qwen3 variants and DeepSeek-R1 still ranked above gpt-oss-120B in overall “intelligence” indices, even as gpt-oss narrows the distance with far fewer active parameters. It is not the crown, but it is impressively close for the size and the serving footprint.
On cost, Amazon is publicly claiming double-digit price-performance wins for gpt-oss on Bedrock, including 18x vs DeepSeek-R1. Claims are claims, so test in your stack, but the point stands, U.S. clouds are incentivized to make open American models the cheapest credible option.
Why standards tilt to whoever ships widest
Markets with lots of early rivals usually compress into 1 to 3 defaults. That shift often tracks distribution and switching costs more than raw technical elegance. Think Windows on desktops, Google for search, and iOS plus Android on phones. Once a tool becomes the default, developers tailor to it, users learn its quirks, and the flywheel keeps spinning. The important point for AI is simple, the “best” model on a lab chart can still lose to the model that is easier to get, easier to run, and easier to customize.
The money path looks like Android
Winners in open source usually earn little on the core artifact at first. The play is lock in usage with free, then monetize adjacent services. Android is a clean analogy, the core is open source and built on Linux, but the money rides on services and distribution layered on top. Expect similar packaging in AI, for example open weights married to paid hosting, eval, tool catalogs, guardrails, or domain adapters.
🏢 How enterprises are actually using this
A growing pattern is a stable of open models behind one interface. Teams keep 8 to 12 models hot, swap defaults by task, and avoid lock-in. A large Southeast Asia bank, OCBC, reports roughly 30 internal tools built on open weights across summarization, coding assist, and market analysis, rotating between Gemma, Qwen, and DeepSeek as new checkpoints ship. This is vendor choice as a feature, not a headache.
🧪 What to install today, without fuss
If you need a U.S. open weight you can serve easily, pull gpt-oss-20B first. It runs on a single 16GB box, supports tool use, and gives you good reasoning at low cost. If you have a single 80GB GPU, gpt-oss-120B is the sweet spot for stronger reasoning without going distributed. Both are available on AWS, and both run cleanly on Ollama or vLLM if you prefer local or your own cluster.
If you need top-end ability in Asian languages or you are localizing for Japan or China, test Qwen3 families in parallel. If you want cutting-edge open Chinese reasoning models beyond Qwen, add Moonshot Kimi K2, MiniMax-M1, and Z.ai GLM-4.5 to your bake-off. All three released open weights in the last few weeks.
📦 Open source beyond models is part of the story
Openness on models is reinforced by openness elsewhere. China’s policy push around RISC-V and OpenHarmony means you can stitch a full stack with fewer foreign dependencies. That is not a headline feature for most teams, but it does bend the long-term cost curve and shapes where ecosystems settle.
🧩 A simple selection playbook
Start with 2 defaults, then grow to a small pool. Use gpt-oss-20B as your low-cost baseline for retrieval-augmented QA, simple coding help, and summarization. Add gpt-oss-120B or a Qwen3 mid-size for deeper reasoning, tool use, and longer documents. Keep 1 to 2 regional specialists if you serve Chinese or Japanese speaking users. Route by task and language automatically using cheap heuristics first, then learned routing as volume grows. This is exactly how teams avoid lock-in and keep leverage on pricing.
🧱 Bottom line
China made open weights the default in 2025, and the U.S. just matched with policy, distribution, and a credible open model in gpt-oss. At the top end, Qwen3 still holds an edge, but gpt-oss closes ground with leaner serving, 1-GPU fits, and strong tool use, and it is now 1 click away in U.S. clouds. The practical move for most teams is simple, run a small stable of models, route by job, and let cost, latency, and language drive the choice, not brand.
History says availability and flexibility beat pure technical merit when standards harden. Policy now reflects that, 3 executive orders plus 90+ actions that bless open models as a legitimate path to standard status. The commercial loop matches past playbooks, free core, paid ecosystem. And geopolitics underscores the urgency, chips on one side, minerals on the other, while enterprises keep installing what they can run and shape on their own terms.
That’s a wrap for today, see you all tomorrow.
For another article maybe- What do you think of the Comet browser?
Validating your thoughts on the open source competition- “Betamax and VHS were two competing home video formats in the late 1970s and 1980s. While Betamax initially offered superior video and audio quality, VHS ultimately won the format war due to longer recording times and lower costs, which were more appealing to the mass market.”