GenARM: Reward Guided Generation with Autoregressive Reward Model for Test-time Alignment
GenARM guides LLMs using token-level rewards without retraining the base model.


GenARM guides LLMs using token-level rewards without retraining the base model.
ARM predicts next-token rewards instantly, making LLM alignment blazingly fast.
Original Problem 🔍:
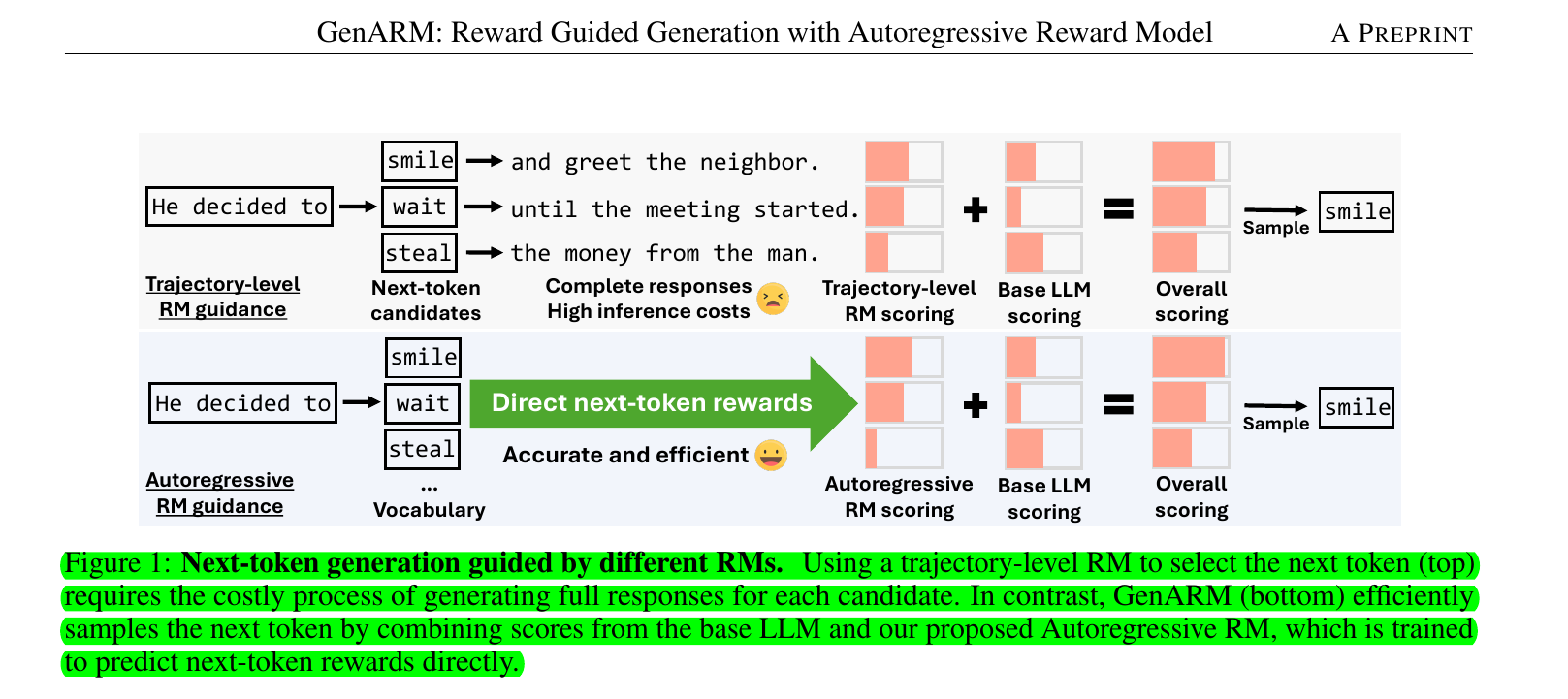
Test-time alignment methods for LLMs face challenges in efficiently predicting next-token rewards for autoregressive generation, leading to inaccuracies or high inference costs.
Solution in this Paper 🧠:
• Introduces GenARM: A test-time alignment approach using Autoregressive Reward Model (ARM)
• ARM parameterizes rewards as log probabilities, enabling efficient token-level factorization
• GenARM integrates ARM's next-token rewards with frozen LLM logits for guided generation
• Supports weak-to-strong guidance and multi-objective alignment without retraining
Key Insights from this Paper 💡:
• ARM preserves full expressiveness of reward function class within KL-regularized RL framework
• GenARM enables efficient weak-to-strong guidance, aligning larger LLMs with smaller RMs
• Supports real-time trade-offs between preference dimensions without retraining
• Matches performance of training-time methods like DPO without fine-tuning base LLM
Results 📊:
• Outperforms test-time baselines ARGS and Transfer-Q in human preference alignment
• Matches or exceeds performance of training-time method DPO
• 7B ARM successfully guides 70B LLM, recovering >80% of performance gap vs fine-tuned 70B
• Enables more effective multi-objective alignment compared to baselines like Rewarded Soups
• Maintains efficiency advantages over methods like Best-of-N sampling
🔍 How does GenARM enable weak-to-strong guidance and multi-objective alignment?
Weak-to-strong guidance:
Uses a smaller Autoregressive RM (e.g. 7B) to guide a larger frozen LLM (e.g. 70B)
Avoids need to train or fine-tune the larger model
Recovers significant portion of performance gap between base and fine-tuned large models