General OCR Theory: Towards OCR-2.0 via a Unified End-to-end Model
General OCR Theory i.e. GOT (OCR-2.0) demonstrates versatility in handling various "character" types with an efficient 580M parameter architecture.


General OCR Theory i.e. GOT (OCR-2.0) demonstrates versatility in handling various "character" types with an efficient 580M parameter architecture.
Original Problem 🔍:
Traditional OCR systems (OCR-1.0) and current Large Vision Language Models (LVLMs) have limitations in handling diverse optical character recognition tasks.
Solution in this Paper 🛠️:
• Proposes and introduces GOT model
• GOT: 580M parameter unified end-to-end model with high-compression encoder and long-contexts decoder
• Supports various input types and output formats (plain/formatted)
• Features: Interactive OCR, dynamic resolution, multi-page processing
• Three-stage training strategy: encoder pre-training, joint-training, and decoder post-training
• Data engines for synthetic data production across various OCR tasks
Key Insights from this Paper 💡:
• OCR-2.0 unifies diverse OCR tasks in a single model
• Balances perception and reasoning capabilities
• Efficient architecture with fewer parameters than LVLMs
• Versatile in handling various "character" types beyond text
Results 📊:
• Outperforms larger models in scene text OCR
• Achieves state-of-the-art performance on Chinese and English PDF OCR tasks
• Demonstrates strong performance in formatted document OCR, fine-grained OCR, and general OCR tasks (e.g., sheet music, geometric shapes, charts)
• Surpasses chart-specific models and popular LVLMs in chart OCR tasks
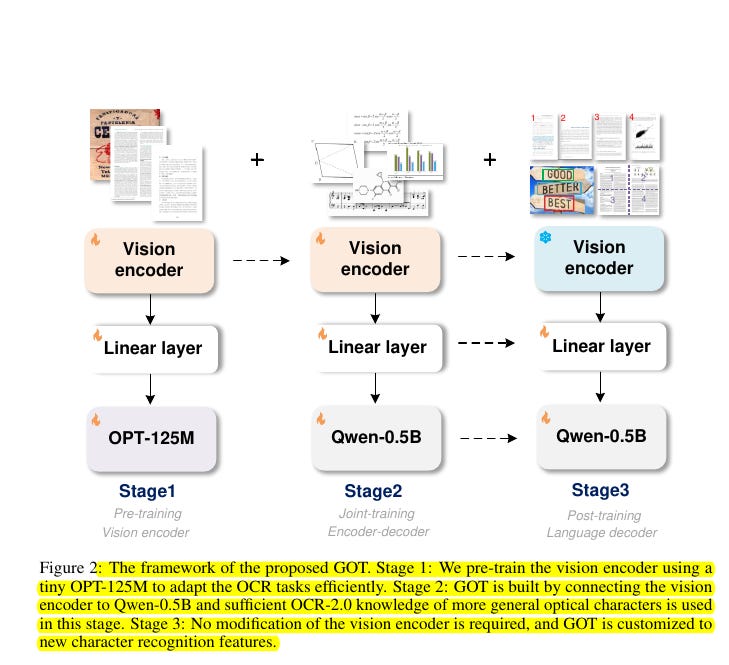
🛠️ Architecture : The GOT model consists of three main components:
Image encoder: A VitDet-based encoder with about 80M parameters, processing 1024x1024 input images.
Linear layer: Connects the encoder and decoder.
Output decoder: A Qwen-0.5B language model with 500M parameters, supporting 8K max length tokens.

Key features of the GOT model
Unified architecture: It uses a high-compression encoder and a long-contexts decoder in an end-to-end design.
Versatility: It can handle various input types (scene and document-style images) and output formats (plain or formatted results like markdown/tikz/smiles/kern).
Interactive OCR: It supports region-level recognition guided by coordinates or colors.
Dynamic resolution: It can process ultra-high-resolution images (over 2K).
Multi-page OCR: It can handle multiple pages in a single pass, useful for PDF documents.
Supports English and Chinese.
With 580M parameters, it's more computationally friendly than larger models.