
🌏 Google DeepMind debuted Genie 3 and it is literally ‘out of this world’
Google DeepMind’s Genie 3, China’s agent race, OpenAI’s translation + data agent, NVIDIA’s new MoE, and Kimi K2.5 leading open coding models.

Read time: 10 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (30-Jan-2026):
🌏 Google DeepMind debuted Genie 3 and it is literally ‘out of this world’
🇨🇳 China’s MiniMax launched MiniMax Agent Desktop
🏆 NVIDIA released an NVFP4 version of Nemotron 3 Nano, a 30B-A3B hybrid mixture of experts (MoE) model.
📡OpenAI’s launched its first dedicated translation product, across 50-plus languages.
🛠️ OpenAI explains in its latest piece why they needed a bespoke AI data agent.
🇨🇳 China’s Kimi K2.5 becomes the best open model for coding
🌏 Google DeepMind debuted Genie 3 and it is literally ‘out of this world’

Google has begun rolling out access to Project Genie, an experimental research prototype that allows users to create, explore and remix interactive worlds using AI-generated environments.
The world keeps generating ahead in real time based on actions, instead of being a mostly fixed 3D scene that only lets the camera move around. GoogleDeepMind links world models to AGI because agents need to handle more than fixed games like Chess or Go.
Older generative 3D demos often behave like static snapshots, so interaction is closer to camera movement than to a world that keeps evolving. Project Genie wraps Genie 3 with Gemini and Nano Banana Pro, so users preview and edit a starting image before entering the world.
It also lets users pick first-person or third-person view, adjust the camera, and download videos of their explorations. As you explore, Genie 3 generates the path ahead and tries to keep physics and interactions stable.
Remixing builds new worlds by reusing and modifying existing prompts, with curated examples and a randomizer to start from. For now, you can only explore a generated world for 60 seconds. Google also warns that sometimes the creations may not look “completely true-to-life” and users may face “experience higher latency in control” of characters. Currently Project Genie is available only for Google’s AI Ultra subscribers in the US.
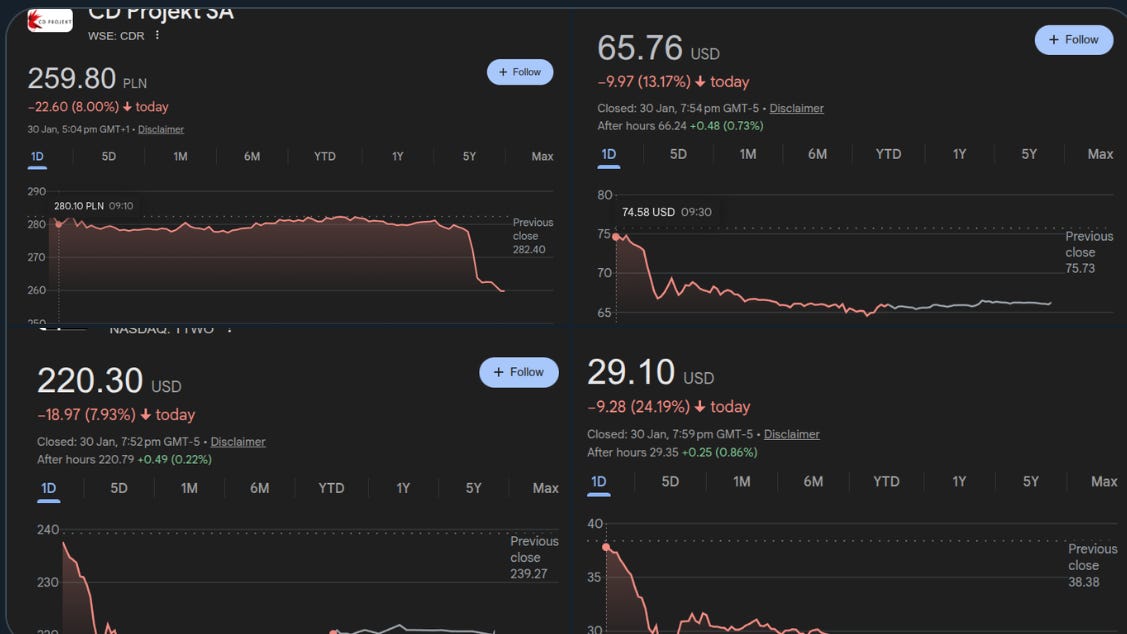
Genie is so good that Video game stocks are crashing sharply today right after Google introduced Project Genie. Investors think AI-powered game creation could disrupt the market.
Most games are still built by authoring assets and rules inside a game engine that explicitly computes physics, lighting, collisions, and other systems.
That workflow is slow because every new level needs lots of hand-built content plus careful scripting and testing. Whereas, Genie 3 shifts that slow human-bottlencked work into a learned world model that predicts what should happen next when the player moves and interacts.
🇨🇳 China’s MiniMax launched MiniMax Agent Desktop

MiniMax Agent Desktop is a cross platform AI workspace for macOS and Windows that can run a steady 24/7 worker on device. Its like a Claude Cowork assistant with real agent tools and a clawdbot style control, available on both macOS and Windows.
After using it I felt that MiniMax Agent shows that model capability alone isn’t enough; what matters is tying model iteration tightly to real consumer usage in subjective, non-verifiable domains.
It reads authorized local documents, email, calendars, GitLab, and logs, and keeps everything on device by design. They also released a feature named “Experts” hub which ships ready workflows for research, writing, code review, and outreach, and anyone can publish new Experts.
Developers get batch code reading, structured edits, merge request creation, and alert monitoring so the busywork drops away.
Its desktop app, after you grant permissions, reads those local sources and runs the workflows on your computer, keeping raw files and processing on device instead of sending them to the cloud. E.g. It reads authorized local documents, email, calendars, GitLab, and logs, and keeps everything on device by design.
The desktop app runs on macOS and Windows, and feels like a general purpose workstation for agents. Full browser control means you describe the goal once and the agent navigates, clicks, fills forms, and submits.
Setup is simple, install, sign up for 1,000 credits, connect only the sources needed, describe the task, then run an Expert. Here, I am turning AI paper into a gorgeous presentation with it. A clean slide deck in minutes using retrieval, outline planning, and slide generation.
Try MiniMax Agent Desktop here right away. Then
Authorize: Connect your local documents, email, and other tools as needed
Describe your tasks in natural language and let the Agent handle the rest
Browse the Experts Hub for pre-built workflows or create your own
And try here the Agent on the web.
🛠️ OpenAI explains in its latest piece why they needed a bespoke AI data agent.

The data agent works across 600PB of data and 70K datasets without the person needing to know where anything lives. The main result is that routine analysis moves from days to minutes because the agent can detect bad intermediate results and revise its own joins, filters, and assumptions.
At this scale, analysts often waste time distinguishing near-duplicate tables and guessing which one matches a metric definition. Manual SQL is also easy to get subtly wrong, since many-to-many joins can inflate counts, misplaced filters can change populations, and null handling can shift totals.
The agent starts with metadata grounding, using schemas and lineage plus mined historical queries that show common table pairings. It adds human annotations from domain experts so “what this table means” and “when not to use it” are explicit.
It then uses Codex to read the pipeline code that produces tables, which reveals freshness, granularity, and hidden business logic that SQL logs do not show. Institutional knowledge from Slack, Google Docs, and Notion is embedded with permissions, so internal terms, launches, and canonical metric logic can be retrieved safely.
Corrections can be saved as personal or global memory, which turns one-off fixes like the exact experiment gate string into a reusable constraint. A daily offline pipeline normalizes this context into embeddings, and at runtime retrieval-augmented generation (RAG) fetches only relevant snippets before issuing live warehouse queries.
🏆 NVIDIA released an NVFP4 version of Nemotron 3 Nano, a 30B-A3B hybrid mixture of experts (MoE) model.

It quantizes both weights and activations to NVFP4, a 4-bit floating point format, and uses quantization-aware distillation (QAD) to keep quality close to the original bfloat16 (BF16) model. Post-training quantization (PTQ) is easy because it needs no training, but pushing down to FP4 can cause noticeable accuracy loss.
Quantization-aware training (QAT) can fix some of that by training in low precision with next-token cross-entropy, which penalizes wrong next-token probabilities, but it often needs extra fine-tuning stages and can be unstable. quantization-aware distillation (QAD) instead freezes the BF16 model as a teacher and trains the NVFP4 student to match the teacher’s full next-token probability distribution.
The match is enforced by minimizing Kullback-Leibler divergence (KL divergence), which measures how different 2 probability distributions are, between teacher and student logits, the pre-probability token scores. Unlike weight-only FP4 schemes such as GPT-OSS MXFP4, quantizing activations as well is claimed to deliver about 2x more effective low-precision math on Blackwell tensor cores, the GPU’s matrix units. NVIDIA says the memory cut makes local deployment on consumer GPUs like RTX5090 more realistic.
Quantization-aware distillation (QAD) can keep the training goal closer to the high-quality teacher behavior, while QAT is tied to the standard next-token loss.
In the below image, on the left, quantization-aware distillation (QAD) uses a high-precision model as a frozen teacher and a 4-bit model as a student.

The student learns by trying to copy the teacher’s full set of “next word” probabilities, not just the single correct answer. The score it minimizes is KL divergence, which is just a way to measure how different 2 probability distributions are, and it pushes the student’s outputs to look like the teacher’s outputs. This helps because the teacher gives “soft targets” that tell the student which wrong answers are close and which are totally off, which is useful when 4-bit rounding makes learning noisy.
On the right, quantization-aware training (QAT) trains the 4-bit model directly using token labels and cross entropy, which only rewards the model for putting high probability on the single correct next token.
The “shift + mask” part means the training data is arranged so the model predicts the next token from the previous tokens, and the mask ignores positions that should not count in the loss.
📡 OpenAI’s launched its first dedicated translation product, across 50-plus languages.

The translator also lets people ask for style shifts like more fluent, more formal, or kid-friendly wording. Older translation tools usually return 1 best guess per prompt, and fixing tone or idioms means rewriting the request. Here the translation stays inside a chat loop, so follow-ups can adjust phrasing while keeping context consistent.
🇨🇳 China’s Kimi K2.5 becomes the best open model for coding

Moonshot AI has released an upgraded version of its Kimi model Kimi K2.5, an open-source native multimodal model intensifying competition among China’s leading AI developers.
Kimi K2.5 builds on Kimi K2 with continued pretraining over approximately 15T mixed visual and text tokens. Built as a native multimodal model, K2.5 delivers state-of-the-art coding and vision capabilities and a self-directed agent swarm paradigm.
The swarm can spawn 100 sub-agents, run 1,500 tool calls, and reports up to 4.5x faster completion than a single agent. Parallel orchestrators are hard to train because feedback is delayed and sparse, and a common failure mode is serial collapse back into single-agent execution.
Trained with Parallel-Agent Reinforcement Learning (PARL), K2.5 learns to self-direct an agent swarm of up to 100 sub-agents, executing parallel workflows across up to 1,500 coordinated steps, without predefined roles or hand-crafted workflows.
PARL uses a trainable orchestrator agent to decompose tasks into parallelizable subtasks, each executed by dynamically instantiated, frozen subagents. Running these subtasks concurrently significantly reduces end-to-end latency compared to sequential agent execution.
Reward shaping first pushes parallelism, then shifts toward task success, and “Critical Steps” scores latency by tracking orchestration overhead plus the slowest subagent stage.
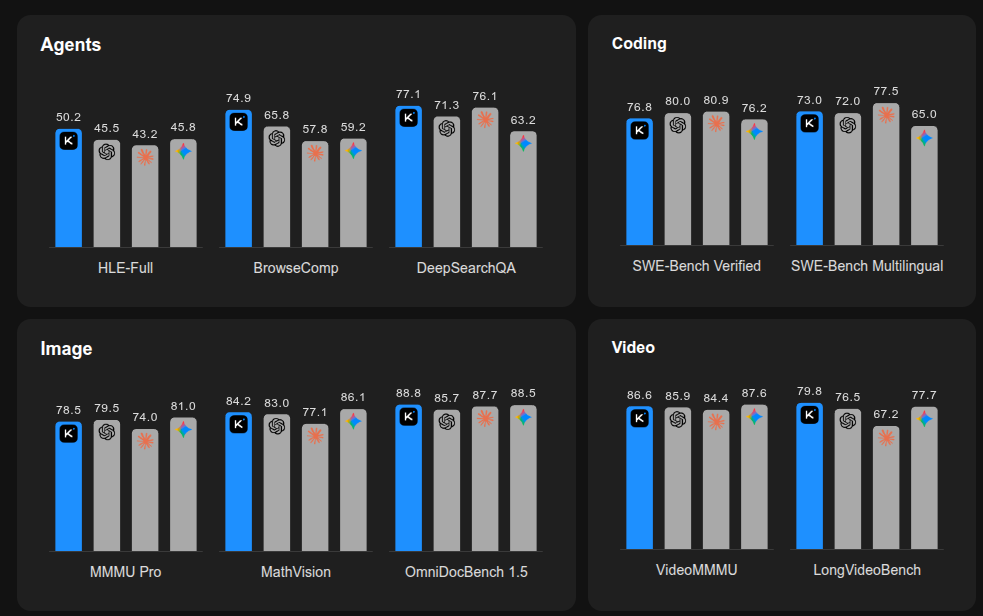
On HLE-Full with tools, a mixed text plus image reasoning benchmark with search and browsing, it reports 50.2 versus 45.5 for GPT-5.2 xhigh and 43.2 for Claude 4.5 Opus.
On BrowseComp with context management, a tool-based search benchmark, it reports 74.9 versus 65.8 and 57.8, and swarm mode reaches 78.4.
On OCRBench, an optical character recognition (OCR) test, it reports 92.3 versus 80.7 and 86.5, while SWE-Bench Verified, a real bug-fixing test, is 76.8 versus 80.0 and 80.9.
BrowseComp cost is 21.1x lower than GPT-5.2, and HLE and SWE-Bench Verified costs are 10.1x and 5.1x lower at similar performance, and internal swarm evaluations cut runtime by up to 80%.
Most runs use a 256k-token context and sometimes truncate tool history, so very long tool traces can fail.
That’s a wrap for today, see you all tomorrow.