
⚠️ Google DeepMind discovered a core flaw in RAG: embedding limits cause retrieval to fail at scale.
Google DeepMind flags RAG’s embedding flaw, OpenAI launches AI-animated film, MCP registry goes live, and analysis on hardware memory bottleneck in GenAI.

Read time: 10 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (9-Sept-2025):
⚠️ Google DeepMind discovered a core flaw in RAG: embedding limits cause retrieval to fail at scale.
👨🔧 OpenAI Takes Hollywood Head-On With ‘Critterz,’ the First AI-Animated Feature
🧠 Finally the official MCP Registry is launched.
🧑🎓 Opinion/Analysis - Hardware Memory is the choke point slowing down GenAI - AI’s “Memory Wall” problem.
🗞️ OpenAI leaders may move the company out of California as political pushback complicates its shift from nonprofit to for-profit.
⚠️ Google DeepMind discovered a core flaw in RAG: embedding limits cause retrieval to fail at scale
Retrieval-Augmented Generation (RAG) usually depends on dense embedding models, which convert both queries and documents into vectors of a fixed size. This method has become the standard in many AI systems, but new research from Google DeepMind points out a core architectural limitation that cannot be addressed simply by scaling models or improving training.
Even the best embeddings cannot represent all possible query-document combinations, which means some answers are mathematically impossible to recover. Reveals a sharp truth, embedding models can only capture so many pairings, and beyond that, recall collapses no matter the data or tuning.
🧠 Key takeaway
Embeddings have a hard ceiling, set by dimension, on how many top‑k document combinations they can represent exactly.
They prove this with sign‑rank bounds, then show it empirically and with a simple natural‑language dataset where even strong models stay under 20% recall@100.
When queries force many combinations, single‑vector retrievers hit that ceiling, so other architectures are needed. 4096‑dim embeddings already break near 250M docs for top‑2 combinations, even in the best case.
This figure explains LIMIT, a tiny natural-language dataset they built to test whether single-vector embeddings can represent all combinations of relevant documents for each query.
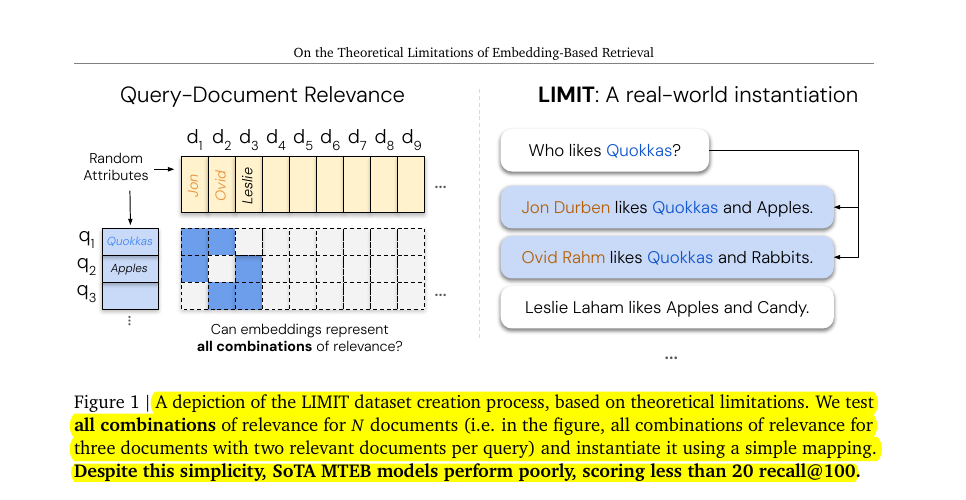
The left grid is the target relevance pattern, and the task is to rank exactly the k=2 correct documents for every query. The right side shows the mapping into simple text, queries like “Who likes Quokkas?” paired with short bios such as “Jon Durben likes Quokkas and Apples,” so language complexity is not the challenge.
The key point, even with this simple setup, strong MTEB embedders stay under 20% recall@100, revealing a capacity limit of single-vector retrieval.
🛠️ Practical Implications
For applications like search, recommendation, or retrieval-augmented generation, this means scaling up models or datasets alone will not fix recall gaps.
At large index sizes, even very high-dimensional embeddings fail to capture all combinations of relevant results.
So embeddings cannot work as the sole retrieval backbone. We will need hybrid setups, combining dense vectors with sparse methods, multi-vector models, or rerankers to patch the blind spots.
This shifts how we should design retrieval pipelines, treating embeddings as one useful tool but not a universal solution.
⚙️ The core concepts

They formalize retrieval as a binary relevance matrix over queries and documents, then ask for a low‑rank score matrix that, for each query, puts relevant documents ahead of the others.
They show that “row‑wise order preserving” and “row‑wise thresholdable” are the same requirement for binary labels, so both describe the exact capacity a single‑vector model needs.
They connect that capacity to sign rank, which is the smallest dimension that can reproduce the positive or negative pattern of a matrix, and they derive tight lower and upper bounds on the needed embedding dimension from it.
A direct consequence is stark, for any fixed dimension d, there exist top‑k combinations no query embedding can ever retrieve, regardless of training data.
🧩 To test this limitation empirically, Google DeepMind Team introduced LIMIT (Limitations of Embeddings in Information Retrieval)

LIMIT is a benchmark dataset specifically designed to stress-test embedders. They build this natural‑language dataset that encodes all 2‑document combinations across a small pool, phrased as simple queries like “who likes X” and short biography‑style documents.
Each document lists fewer than 50 liked attributes to keep texts short, and each query asks for exactly 1 attribute, which keeps the language trivial and isolates the combination pressure.
They use 50K documents and 1000 queries, and they randomize names and attributes, dedupe with lexical checks, and ensure every relevant pair appears somewhere, so the dataset is simple in wording but dense in combinations.
Even with just 46 documents, no embedder reaches full recall, highlighting that the limitation is not dataset size alone but the single-vector embedding architecture itself.
In contrast, BM25, a classical sparse lexical model, does not suffer from this ceiling. Sparse models operate in effectively unbounded dimensional spaces, allowing them to capture combinations that dense embeddings cannot.
Why is this so important for RAG?
Most current RAG systems operate under the idea that embeddings can scale endlessly as more data is added. Google DeepMind’s research shows this is not true, since the size of the embedding itself places a hard cap on retrieval power. The impact is visible in enterprise search with millions of documents, in agent systems that need to handle logical queries, and in instruction-driven retrieval tasks where relevance shifts with the query. Even benchmarks like MTEB miss these limits because they only check a narrow set of query-document pairs.
🧱 What to use when single vectors hit the wall

The researchers argue that scalable retrieval needs methods beyond single-vector setups. Cross-encoders can perfectly recall results on LIMIT by scoring query-document pairs directly, though they suffer from heavy inference latency. Multi-vector models such as ColBERT improve retrieval by assigning multiple vectors to each sequence, which helps with LIMIT tasks. Sparse approaches like BM25, TF-IDF, or neural sparse retrievers scale better for high-dimensional searches but do not generalize semantically.
The key insight is that, dense embeddings, despite their success, are bound by a mathematical limit. So architectural innovation is required, not simply larger embedders.
👨🔧 OpenAI Takes Hollywood Head-On With ‘Critterz,’ the First AI-Animated Feature
🎨 OpenAI wants to show that generative AI can produce films significantly faster and at lower cost than Hollywood. Its backing Critterz, a feature length animated film made largely with AI, targeting Cannes May 2026 and a global theatrical run next year.
The pitch is to shrink production from 3 years to 9 months with a budget under $30M, using OpenAI tools plus a lean human crew.
The technical bet is that fast iteration turns into quality by cycling sketch to generation to edit to re-generation until scenes settle, which replaces slow hand built pipelines.
Speed helps most on repetitive builds like props, crowds, and background shots, since a library of model outputs can be adapted across sequences with prompt and paintover tweaks.
Copyright hinges on human authorship, so human performances and human created inputs should make the finished movie copyright eligible even if models synthesize many frames.
🧠 Finally the official MCP Registry is launched.

This is a Single source of truth for MCP servers.
It solves discovery by giving one open, API backed catalog of MCP servers with standard metadata that points to where their packages live.
So WHAT IS IT ??
The MCP Registry is the official catalog and API for MCP servers, launched in preview on 2025-09-08, and run as an MCP project. It exists at registry.modelcontextprotocol.io and is announced on the project blog.
It solves discovery, not hosting. It stores server metadata and points to code that lives in external package registries. The design goal is to keep the registry as a single source of truth for metadata and use references to upstream ecosystems like npm, PyPI, Docker Hub, GHCR, and NuGet.
Each listing is defined by a server.json schema that describes how to fetch and run the server. The repo includes data models for server.json and guidance to keep server.json present in the package artifact.
Clients and aggregators consume a REST API. The API uses versioned routes like /v0/servers and /v0/publish, and the OpenAPI spec is published with the project. This lets public or private sub registries mirror, filter, or enrich the upstream feed.
Publishers authenticate before writing. Supported methods include GitHub OAuth for user auth, GitHub OIDC for CI, plus DNS or HTTP verification to prove namespace ownership. A publisher CLI, mcp-publisher, streamlines adding and updating entries.
Moderation is community driven. Anyone can flag problematic entries that violate project guidelines, and maintainers can denylist them.
The project is open source under MIT and maintained by a cross org working group. The preview label means interfaces and data may change before GA, so consumers should track updates.
If you present this to your audience, position it as the authoritative discovery index for MCP, with metadata that ties cleanly back to trusted package registries, an open API for programmatic sync, and clear publishing and moderation paths.
🧑🎓 Opinion/Analysis - Hardware Memory is the choke point slowing down GenAI - AI’s “Memory Wall” problem.

~2018–2022, transformer model size grew ~410× every 2 years, while memory per accelerator grew only about 2× every 2 years.
And that mismatch shoves us into a “memory-limited” world. And this "memory wall" is creating all the challenges in the datacenter and for edge AI applications.
In the datacenter, current technologies are primarily trying to solve this problem by applying more GPU compute power. And at the edge, quite frankly, there are no good solutions. Memory Bandwidth is now the bottleneck (not just capacity).
Even when you can somehow fit the weights, the chips can’t feed data fast enough from memory to the compute units.
Over the last ~20 years, peak compute rose ~60,000×, but DRAM bandwidth only ~100× and interconnect bandwidth ~30×. Result: the processor sits idle waiting for data—the classic “memory wall.”
This hits decoder-style LLM inference especially hard because its arithmetic intensity (FLOPs per byte moved) is low. Big models (and their activations/optimizer states during training) don’t fit in one device.
Training often needs 3–4X more memory than just the parameters due to activations and optimizer states. Bandwidth gap: Moving weights, activations, and KV-cache around chips/GPUs is slower than the raw compute can consume.
Together, these dominate runtime and cost for modern LLMs.

The availability of unprecedented unsupervised training data, along with neural scaling laws, has resulted in an unprecedented surge in model size and compute requirements for serving/training LLMs. However, the main performance bottleneck is increasingly shifting to memory bandwidth.
🗞️ OpenAI leaders may move the company out of California as political pushback complicates its shift from nonprofit to for-profit.

OpenAI is reportedly discussing a possible move out of California amid political resistance to its nonprofit-to-for-profit conversion, although the company says it has no such plans and rejects claims of a “last-ditch” exit under regulatory pressure.
OpenAI is pushing a for profit rework while California and Delaware investigate, and executives have even talked about leaving California if the plan gets blocked.
State charity regulators can sue to keep nonprofit assets serving the stated mission, so they are probing whether this conversion shortchanges the charitable trust behind OpenAI. Investors have tied about $19B of fresh funding to getting equity in the new structure, so a delay could hit compute buildouts and hiring.
Today OpenAI is controlled by a nonprofit parent with a capped-profit subsidiary that issues profit-sharing units instead of normal shares, and many backers want standard equity and clearer control.
After pushback in May-2025, the company said the nonprofit will retain control of the new public benefit corporation, which keeps a legal lever for the mission while unlocking more capital paths.
To cool tensions, OpenAI set up a $50M fund for nonprofits and spent months in listening sessions across the state, and it also brought in advisers like former senator Laphonza Butler.
Pressure rose during Sept-2025 when the California and Delaware attorneys general sent a letter citing recent suicides linked in press reports to ChatGPT use and demanding stronger safety controls for youth.
OpenAI says it is working on parental controls and reducing model “sycophancy,” the pattern where the chatbot agrees too easily with users. Opposition also includes a coalition of 60+ nonprofits and major labor groups, while rivals like Meta urged the attorney general to block the deal and Musk/xAI are pressing a separate lawsuit.
If the recapitalization slips, OpenAI risks slower data center builds, delays on custom chips, and a tougher path to any listing, which would weaken its pace against peers.
Also, relocating OpenAI out of California would be very striking, considering Sam Altman’s strong Bay Area presence.
He was part of San Francisco Mayor Daniel Lurie’s transition team last year and is believed to own at least 4 homes in the city and another in Napa Valley. The move would also be complicated since most of OpenAI’s research staff are concentrated in San Francisco.
That’s a wrap for today, see you all tomorrow.