
Google DeepMind introduce new benchmark to rank LLMs on factuality, and to reduce hallucinations
Google DeepMind ranks LLMs for factuality, OpenAI halts AI gun turret, Moondream improves OCR and gaze detection, Meta predicts AI coding dominance, and new models redefine efficiency.
Read time: 7 min 51 seconds
⚡In today’s Edition (11-Jan-2025):
🧑🔬 Google DeepMind introduce new benchmark to rank LLMs on factuality and to reduce hallucinations
🏆 Moondream 2025-01-09 Release: Structured Text, Enhanced OCR, Gaze Detection
🔫 OpenAI Shuts Down Developer Who Made AI-Powered Gun Turret
🖌️ Black Forest Labs optimized Flux for FP4 on RTX50X0: 2x as fast and only requires 10GB VRAM
🗞️ Byte-Size Brief:
Meta predicts AI will handle coding tasks as mid-level engineers by 2025.
NovaSky releases Sky-T1-32B: $450-trained reasoning model rivaling top benchmarks.
Microsoft’s Satya Nadella defines AI age by "Tokens/Dollar/Watt" metric.
Alibaba releases Multimodal Textbook dataset: 22k hours instructional video corpus.
🧑🎓 Deep Dive Tutorial
📚 Google Cloud released "The PyTorch developer's guide to JAX fundamentals"
🧑🔬 Google DeepMind introduce new benchmark to rank LLMs on factuality and to reduce hallucinations

🎯 The Brief
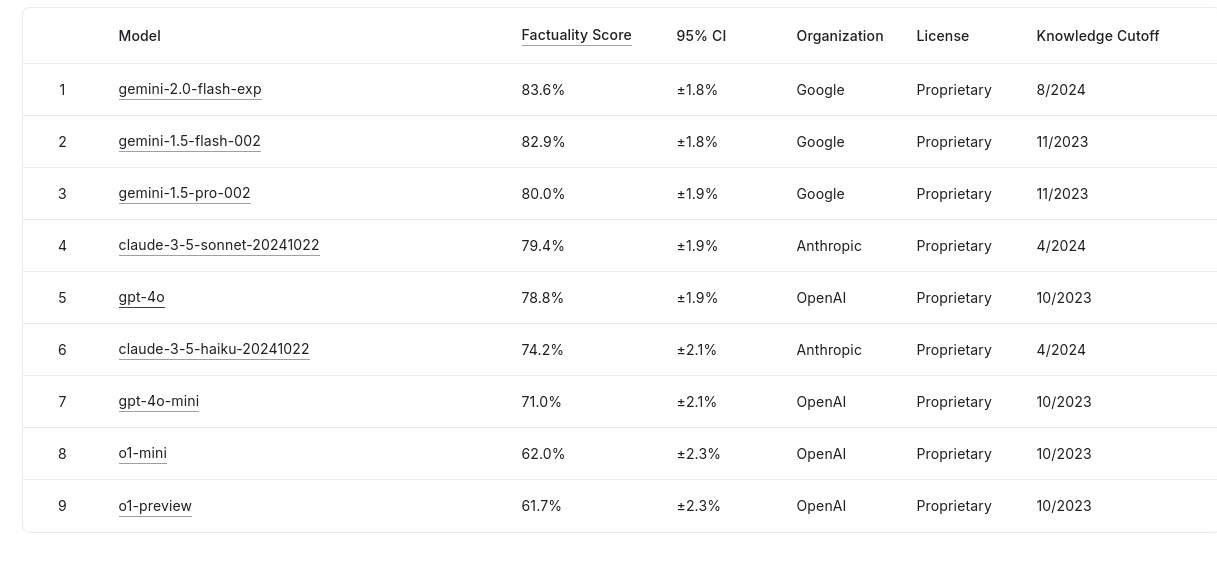
Google DeepMind introduced FACTS Grounding, a benchmark designed to improve LLM factuality by evaluating long-form document-grounded responses and launched a Kaggle leaderboard. The initiative is significant as it addresses factual accuracy gaps in LLMs and ranks models based on their grounded, context-relevant outputs. Gemini 2.0 Flash leads the leaderboard with an 83.6% factuality score.
⚙️ The Details
→ The FACTS Grounding benchmark evaluates LLMs using 1,719 examples split into 860 public and 859 private prompts, requiring responses grounded strictly in provided documents of up to 32,000 tokens.
→ Models must generate long-form answers that fully satisfy user requests while avoiding unsupported claims. Responses are labeled inaccurate if they miss key context or provide vague answers.
→ Factuality scores are judged by three LLMs—Gemini 1.5 Pro, GPT-4o, and Claude 3.5 Sonnet—to mitigate bias, ensuring diverse evaluations.
→ The leaderboard is regularly updated to include new models and aims to fill gaps that other factuality benchmarks miss, such as limiting evaluations to summarization tasks.
→ Models from OpenAI, Anthropic, and Google, such as GPT-4o and Claude 3.5 Haiku, also feature on the leaderboard, all achieving above 61.7% accuracy.
They also published a technical paper on this.
🏆 Moondream 2025-01-09 Release: Structured Text, Enhanced OCR, Gaze Detection
🎯 The Brief
Moondream released 1.9B vision language model, introducing Gaze Detection for human attention tracking alongside enhanced OCR and support for structured output formats like JSON, XML, Markdown, and CSV. This upgrade improves vision AI capabilities while keeping the model lightweight and fast, making it suitable for widespread use.
⚙️ The Details
→ Gaze Detection is an experimental feature aimed at tracking user focus in contexts such as driving and sports, marking Moondream’s expansion into human attention analytics.
→ The OCR improvements enhance text recognition and document understanding, enabling more accurate querying and reading of structured and unstructured data.
→ Support for structured formats, including JSON and XML, simplifies integration with external systems.
→ Moondream addressed benchmark skepticism by improving scores to boost competitive perception while criticizing misleading or irrelevant evaluation questions.
→ Users can access the model via cloud inference with a free tier or download from Huggingface for local use. They also have a playground with this model.
🔫 OpenAI Shuts Down Developer Who Made AI-Powered Gun Turret

🎯 The Brief
OpenAI shut down a developer who used ChatGPT's Realtime API to control an AI-powered gun turret capable of interpreting voice commands to aim and fire a rifle. This raises significant concerns about the risks of autonomous weapon systems amid growing fears of AI misuse in warfare.
⚙️ The Details
→ The DIY device became viral after a video showed the developer issuing commands like "respond accordingly," prompting the turret to precisely aim and fire at targets. OpenAI acted swiftly by cutting off the developer’s API access for violating safety policies.
→ The incident underscores concerns about lethal autonomous weapons, drawing parallels with reported cases such as Israel's AI-based target selection system that allegedly led to unverified attacks on humans.
→ OpenAI has policies prohibiting weaponization but has partnered with Anduril, a defense-tech firm, to develop AI systems for drone defense and threat detection. Critics argue this could still lead to blurred lines between defense and offense.
→ The broader concern extends to open-source models as well. Combined with advances in 3D-printed weapon parts, DIY autonomous systems could become an escalating security risk.
→ To note here that OpenAI's usage policy has long included language barring uses that could "harm people, destroy property, or develop weapons." So this is a clear violation and entirely justified in my opinion.
🖌️ Black Forest Labs optimized Flux for FP4 on RTX50X0: 2x as fast and only requires 10GB VRAM

🎯 The Brief
BlackForestLabs, in collaboration with NVIDIA, has enhanced its FLUX models by optimizing performance for GeForce RTX 50 Series GPUs with FP4 compute support, resulting in 2x faster speeds and 10GB VRAM usage on RTX 5090 GPUs. This significantly reduces memory requirements and boosts generative AI capabilities for creators, particularly in 3D workflows.
⚙️ The Details
→ The FLUX models have been optimized for NVIDIA's Blackwell architecture to deliver faster, more efficient performance. With FP4 compute, FLUX.1 [dev] achieves double the speed on RTX 5090 compared to the previous generation RTX 4090 while using only 10GB of VRAM.
→ BlackForestLabs and NVIDIA introduced the AI Blueprint for 3D-guided generative AI, allowing users to compose 3D scenes in tools like Blender and generate corresponding images with FLUX NIM.
→ Access to these optimizations expands in February, with FP4 models available on Hugging Face, FLUX NIM via ComfyUI, and the AI Blueprint on GitHub. The tools emphasize democratizing access to advanced AI media creation workflows.
🗞️ Byte-Size Brief
Mark Zuckerberg said on the Joe Rogan podcast that within Metal AI is expected to take over routine coding tasks by 2025, effectively functioning as mid-level software engineers. This shift could make development teams leaner and free up human engineers to focus on higher-level, creative problem-solving.
NovaSky released Sky-T1-32B, their fully open-source reasoning model that matches o1-preview on popular reasoning and coding benchmarks — trained under $450! It proves $450 and a day’s training can rival top reasoning models in coding tasks. Built on Qwen2.5-32B, trained with 17K data, it runs on 8 H100s using DeepSpeed Zero-3 Offload, with weights and code fully available.
Satya Nadella, CEO of Microsoft explains the the new equation for the AI age as "Tokens per Dollar per Watt" in his speech. And how the growth of every Company or Industry or Country will depend on driving this equation, by focussing on AI Infrastructure. He also talks at length about the true Agentic future.
Alibaba released Multimodal Textbook dataset: a new multimodal pre-training dataset from online instructional videos (22k hours). It containse 6.5M images interleaved witk 800k text on math, physics, chemistry. This corpus provides a more coherent context and richer knowledge for image-text aligning. Available in Huggingface.
🧑🎓 Deep Dive Tutorial
📚 Google Cloud released "The PyTorch developer's guide to JAX fundamentals"

🚀 Summary
The tutorial introduces JAX to PyTorch users, focusing on neural network training for Titanic survival prediction using Flax NNX and Linen APIs. It emphasizes key differences like functional programming, explicit PRNG key management, and Just-In-Time (JIT) compilation for speed-ups, demonstrating how JAX's functional design results in 3.5x faster training loops on GPUs.
Fist note that, JAX focuses on functional programming, immutability, and explicit gradient functions, while PyTorch uses object-oriented programming with in-place updates and implicit gradient tracking. This guide bridges the gap by showing PyTorch users how to adopt JAX's explicit, function-based approach using familiar coding patterns, making the transition smoother and highlighting speed gains from JIT compilation and parallelization.
Key Takeaway
→ Why JAX’s modular approach stands out
JAX focuses solely on numerical computation and automatic differentiation, unlike PyTorch, which bundles neural networks, optimizers, and training utilities. This means you need libraries like Flax for layers and Optax for optimization, giving JAX more flexibility but requiring you to compose components explicitly.
→ Bridging the PyTorch and JAX gap with Flax NNX
Flax NNX’s API is designed to mimic PyTorch’s layer definitions and forward passes, making the transition easier. Key differences include explicit random number key management and using __call__ for forward passes, aligning with JAX's functional design.
→ Data loading stays familiar
Data loaders remain the same as in PyTorch. The only change is using tree_map to convert batches into JAX-friendly arrays (jnp), making it a nearly identical workflow.
→ Gradients and backward pass in JAX are explicit functions
Instead of loss.backward() like in PyTorch, JAX uses functions like value_and_grad(loss_fn), which return gradients directly. This avoids implicit mutation, reinforcing immutability and enabling clean, parallel computations.
→ Optimization step differences
JAX’s optimizer updates are done by passing gradients directly to the optimizer.update(grads) function, whereas PyTorch updates parameters in-place using optimizer.step().
→ Training loops simplified by JIT compilation
By adding @nnx.jit, the training loop becomes JIT-compiled, running significantly faster by optimizing GPU execution. The tutorial shows a reduction in training time from 6.25 minutes to 1.8 minutes for 500 epochs on a P100 GPU.
→ Linen API for pure functional enthusiasts
The Flax Linen API requires using apply() to call models, separating parameters from the model state. This adds more control but introduces additional complexity compared to NNX’s Pythonic syntax. Both APIs share core similarities but cater to different programming preferences.
great newsletter today!