
🥇Google Gemini Deep Think Achieves Gold at International Math Olympiad
Google’s Gemini crushes math, ARC-AGI-3 shows LLMs still trail humans, Anthropic faces piracy lawsuit, S3 gets vector-native, Groq hits 400+ t/s, and Meta courts OpenAI's chief research officer.
Read time: 14 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (21-July-2025):
🥇Google Gemini Deep Think Achieves Gold at International Math Olympiad
🥉 New ARC-AGI-3 benchmark shows humans still outperform LLMs at thinking
⚖️ "Napster-style" piracy allegations put Anthropic at risk of a billion-dollar class action lawsuit
🛠️ AWS Introduces Amazon S3 Vectors: First cloud storage with native vector support
🗞️ Byte-Size Briefs:
Groq is serving Kimi K2 at >400 output tokens/s, 40X faster than Moonshot’s first-party API
Mark Zucker asked Mark Chen (OpenAI’s chief research officer, Mark) if he would consider joining Meta, reportedly offering up to $1 billion dollars.
New Windsurf CEO Jeff Wang recounts a frantic weekend of dealmaking to save the startup: 'I was on the verge of tears'.
SimpleBench results got updated. Grok 4 came 2nd with 60.5% score.
🧑🎓 Resource: A study explores what AI 2027 might look like.
🥇Google Gemini Deep Think Achieves Gold at International Math Olympiad
Gemini’s Deep Think mode tackled the toughest high-school math contest and earned 35 points, enough for a gold medal, by writing full proofs in plain English within the same 4.5 hour window given to human competitors.
Key Points:
Historic achievement: First AI to officially achieve gold medal standard at IMO, solving problems in natural language within the 4.5-hour time limit
Massive improvement: Jumped from last year's silver medal performance (28 points) to gold medal level (35 points) in just 12 months
Technical breakthrough: Google says the new system uses a technique called “parallel thinking,” that allows the model to simultaneously explore and combine multiple possible solutions before giving a final answer—rather than pursuing a single, linear chain of thought.
The competition brutally difficult and national country-level teams train for years. Each country sends a team of up to six students who get two sessions of 4.5 hours each to solve six problems covering algebra, combinatorics, geometry, and number theory. For this year's competition, only 67 of the 630 total contestants received gold medals, or roughly 10 percent.
📚 How Gemini beat the Olympiad
Each International Mathematical Olympiad set has 6 problems. Gemini solved 5 of 6, covering algebra, combinatorics, geometry and number theory, and dropped only 7 points overall. Those 35 points placed it alongside the top 8% of the 630 human contestants who also reached the gold zone this year.
🔄 What changed since last year
In 2024 Google’s AlphaProof plus AlphaGeometry combo managed 28 points, which is silver territory, and needed experts to rewrite every problem into the Lean formal-logic language before the models could start.
Deep Think drops that translation step. It reads the original English prompt, reasons, and outputs a proof in everyday language, all inside the official time limit, not the multi-day compute run the earlier system required.
🧠 Inside the Deep Think toolbox
Google added a “parallel thinking” routine that spawns many partial solution threads at once, then merges the promising pieces instead of chasing a single line of thought.
Training mixed regular Gemini data with extra sequences of multi-step reasoning, theorem-proving traces, and past Olympiad solutions. Reinforcement learning nudged the model to plan deeper before emitting an answer.
Engineers also let the model “take a breath” by granting longer internal thinking time and feeding it curated hints that experienced coaches give human contestants.
🛠️ Engineering moves that really mattered
Gemini’s engineers added three guard-rails that push the model from “pretty good” to competition-ready reasoning.
🔄 Self-consistency checks filter shaky proofs
The model does not trust the first idea it writes. It spawns many candidate proofs, then runs a verifier that re-plays every algebra move, geometry construction, or number-theory claim. Any trace that breaks logical flow gets tossed. Only answers whose steps agree with one another survive, and a majority vote picks the final proof. Studies on math benchmarks show that this filter lifts accuracy by up to 18% over plain chain-of-thought because most hallucinations show inconsistent steps that the verifier flags.
📚 Retrieval pulls useful past problems into the context
Before thinking, Gemini embeds the new Olympiad question, searches an index of thousands of solved tasks, and grabs the closest matches. It drops those statements and expert solutions into its context window, so the model can spot reusable lemmas or geometric tricks without reinventing them. Retrieval-augmented generation has already improved math help-desk bots and long-context Gemini variants, so the same playbook helps here by anchoring reasoning in known patterns instead of blank-page exploration.
📏 A scoring rubric inside the prompt guides self-evaluation
The prompt spells out the International Mathematical Olympiad marking scheme: 7 points for a full proof, partial credit for progress, 0 for a wrong answer. After each reasoning pass the model grades its own draft against this rubric, spots gaps, and decides whether to spend more “thinking” on unfinished parts. Self-critique and rubric-based feedback, a method explored in prompt-engineering guides and self-evaluation papers, steers large models away from half-baked answers and toward polished arguments that match examiner expectations.
🥉 New ARC-AGI-3 benchmark shows humans still outperform LLMs at thinking

The ARC-AGI-3 benchmark, also called the Interactive Reasoning Benchmark, was preview-released on July 18, 2025, by the ARC Prize Foundation. This preview introduced three interactive, game-based tasks designed to test an AI's fluid intelligence—specifically, its ability to quickly learn and adapt to novel tasks.
The early preview is limited to 6 games (3 public, 3 to be released in Aug '25). Development began in early 2025 and is set to launch in 2026.
🕹️ ARC-AGI-3 shows that humans breeze through fresh grid-world games in <5 minutes, while frontier models still score 0%. The preview packs 6 unseen puzzles that expect agents to explore, plan, and remember without any tips. Anyone can try building a learner under a strict RTX 5090 or $1K API, 8-hour cap to chase a share of $7,500.
ARC-AGI-3 is the continuation of the ARC series of AI benchmarks:
Focus on generalization and adaptation to novelty
Easy for humans, yet extremely difficult for AI
Built exclusively on Core Knowledge priors, with no other domain-specific knowledge required
Key Points About the ARC-AGI-3 Preview Release:
Focus: The benchmark emphasizes agentic capabilities, requiring AI to explore, acquire new skills, and retain memory to solve tasks. These tasks are easy for humans (scoring 100%) but current frontier AI systems score 0%, highlighting a significant capability gap.
Interactive Format: Unlike prior ARC benchmarks, ARC-AGI-3 uses dynamic, game-based challenges where agents must write code and spawn sub-agents to succeed.
Contest and API: A $10,000 agent contest was launched alongside the preview to encourage open-source solutions. An AI agents API was also released to support development.
Purpose: The preview aims to drive research toward AGI by showcasing tasks that resist brute-force methods and demand efficient, human-like reasoning.
🧩 Humans still romp through every test, and that gap is the whole point. The creators say easy-for-people yet brutal-for-machines puzzles expose the real shortfall between today’s language models and flexible thinking, so a benchmark only counts if people can clear it quickly.
🔍 Each game drops an agent into a tiny grid world with no mission text, no reward signals, and no action list. The agent must poke around, notice what changes, stash memories of cause and effect, then chain those insights into a multi-step plan that finally flips the hidden success flag. Tasks mix tool use, theory-of-mind, spatial reasoning, and long-horizon goals, borrowing lessons from classic Atari research but stripping away hand-coded hints.
🏗️ Learning happens across repeated runs, not one sprawling episode, mirroring how people refine a strategy over many restarts. The benchmark measures sample-efficiency: fewer resets and actions earn a higher score. That pushes designers to build agents that reflect, compress past states into simple rules, and generalize instead of memorizing pixel layouts.
🚦 To keep the playing field fair, every submission gets exactly 8 hours of wall-clock time, using either a single RTX 5090 for self-hosted code or up to $1K worth of API hits if the agent lives in the cloud. Over-spending melts the entry. Only the top ~10 agents make it to private games, so brute-force search is out, and clever exploration is in.
🛠️ Frontier chat-driven agents like o3 and Grok 4 crash almost instantly because they wait for text cues that never arrive, and they over-index on chain-of-thought prompts rather than environment feedback. Without built-in physics priors and episodic memory, they wander aimlessly or spam actions, proving that raw language scale does not equal adaptive skill.
🏆 The July preview contest runs until Aug 10 2025, pays $5,000 to first place, and asks winners to open-source their code by Aug 11. The full ~100-game suite lands in 2026, and the organizers hope it becomes the north-star yardstick for declaring genuine AGI once an agent matches human learning speed.
How to Run it?
Download the SDK and environments from the ARC-AGI-3-Agents repo or the Hugging Face mirror, install dependencies with uv, copy .env-example to .env, add your ARC_API_KEY, then run the random baseline on a preview game to confirm everything works. Next, swap in an agent that learns across retries and test it on the 3 public grid worlds, keeping the full evaluation under 8 hours on 1 RTX 5090 or within a $1K API budget ARC Prize. Once scores look good, submit your code and run logs by Aug 10 2025, then open-source the repo by Aug 11 2025 to stay prize-eligible.
⚖️ "Napster-style" piracy allegations put Anthropic at risk of a billion-dollar class action lawsuit

A new class action copyright lawsuit against Anthropic exposes it to a billion-dollar legal risk.
Judge William Alsup called the haul “Napster-style”. He certified a class for rights-holders whose books sat in LibGen and PiLiMi, because Anthropic’s own logs list the exact titles.
The order says storing pirate files is not fair use, even if an AI later transforms them. Since the law allows up to $150,000 per willful hit, copying this many books could cost Anthropic $1,000,000,000+.
Anthropic must hand a full metadata list by 8/1/2025. Plaintiffs then file their matching copyright registrations by 9/1. Those deadlines will drive discovery and push the case toward a single jury showdown.
Other AI labs, which also face lawsuits for training on copyrighted books, can no longer point to the usual “fair use” excuse if any of their data came from pirate libraries. Judge Alsup spelled out that keeping pirated files inside an internal archive is outright infringement, even if the company later transforms the text for model training.
🛠️ AWS Introduces Amazon S3 Vectors: First cloud storage with native vector support
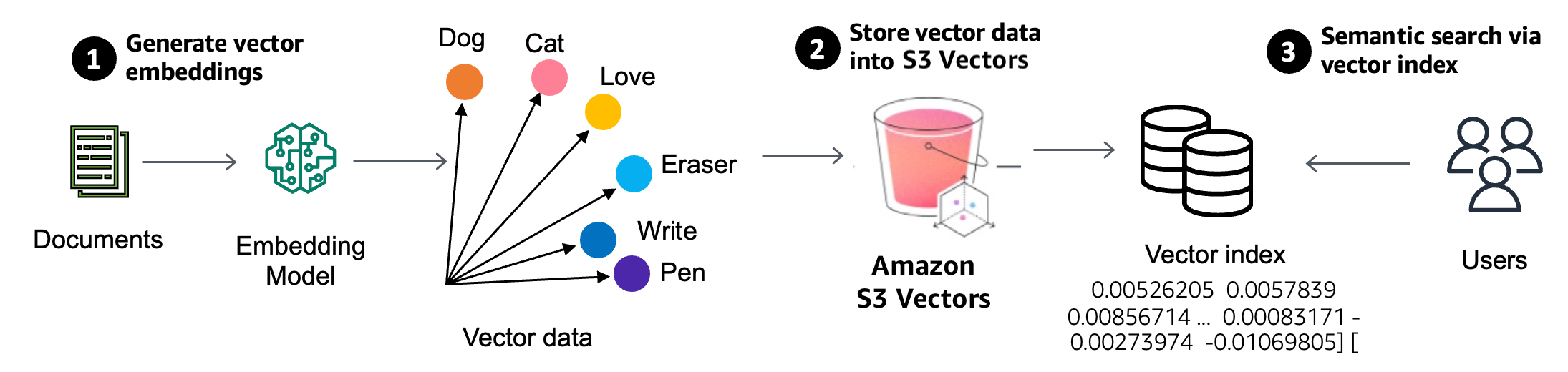
Amazon S3 Vectors claims can cut the cost of uploading, storing, and querying vectors by up to 90% compared to using a vector database.
This new bucket type keeps vector data inside S3 itself, brings a dedicated similarity-query API, and promises up to 90% lower costs than running a separate vector database.
The launch targets teams that need large, cheap vector stores to feed retrieval-augmented generation, memory for AI agents, or other semantic-search workloads.
📌 What S3 Vectors is: S3 Vectors adds “vector buckets”. Inside each bucket you can create as many as 10 000 vector indexes, each able to hold tens of millions of embeddings, all managed with strong consistency and without provisioning servers. The service keeps S3’s elasticity, durability, and security controls while exposing simple PUT, GET, and similarity-search operations under a new s3vectors namespace.
📌 Why AWS claims up to 90% savings: Because data sits on low-cost object storage and query throughput is tuned for infrequently accessed vectors. Open-source vector stores often need high-performance SSDs or GPUs to reach low-latency search, driving both infrastructure and operations expense, whereas S3 Vectors charges only for the bytes stored plus request counts.
📌 Performance characteristics: S3 Vectors indexes are optimized for sub-second similarity queries, enough for memory recall or semantic search that sits behind an LLM prompt, but not for the thousands-of-QPS scenarios where real-time recommendation engines live. Teams can tier data, keeping hot vectors in Amazon OpenSearch Service and moving colder vectors back to S3 Vectors to trim spend while retaining queryability.
📌 Built-in service integrations: When you create an Amazon Bedrock Knowledge Base or set up context retrieval inside SageMaker Unified Studio, you can now pick an S3 vector index as the back-end store with a single click. OpenSearch snapshots can also land in vector buckets, turning S3 Vectors into a cheaper long-term archive that can be re-hydrated when traffic rises.
📌 Benefits for generative and agentic AI workflow: LLMs work better when they can recall broader context without blowing up token limits. Storing many more embeddings cheaply lets agents keep long-term memory, retrieve richer context, and answer with higher factual accuracy while the bill stays predictable. RAG pipelines that once ejected old embeddings to save money can now keep them online and searchable.
📌 Preview scope and getting started: The preview is available today in US East (N. Virginia & Ohio), US West (Oregon), Asia Pacific (Sydney), and Europe (Frankfurt). Sign-up is through the usual “Join preview” form on the product page; once approved you create a vector bucket, define indexes, and begin uploading your embeddings with the new API. Pricing details are on the S3 page under the “Vectors” tab and follow a pure pay-for-what-you-use model.
So overall, by folding vector storage into S3, AWS is betting that many workloads prefer lower cost and tight integration over the millisecond latencies of dedicated vector databases.
So this move pressures standalone vendors on price while giving AWS customers a simpler architecture path for large-scale agentic and RAG systems.
🗞️ Byte-Size Briefs
Groq is serving Kimi K2 at >400 output tokens/s, 40X faster than Moonshot’s first-party API

Groq stands out for blazing fast speed. DeepInfra, Novita and Baseten stand out for their pricing, being the only providers pricing similarly to or more cheaply than Moonshot’s first party API.
Mark Zucker asked Mark Chen (OpenAI’s chief research officer, Mark) if he would consider joining Meta, reportedly offering up to $1 billion dollars.
New Windsurf CEO Jeff Wang recounts a frantic weekend of dealmaking to save the startup: 'I was on the verge of tears'. A beautiful Silicon Valley story of speed and empathy. Jeff Wang (CEO Windsurf) wrote a detailed post about what happened in Windsurf over the weekend before the final Google’s acquisition.
“A founder goes down with the ship.”
On Friday (before its final acquisition) Windsurf’s 250 staff expected an OpenAI acquisition, but instead learned the deal had collapsed. Leadership considered raising funds, selling, distributing cash, or continuing, and morale sank. That evening Cognition’s Scott Wu and Russell Kaplan reached out. Seeing a strong fit between Cognition’s engineering depth and Windsurf’s GTM strength, both teams accelerated talks. They signed an LOI Saturday, worked through legal details nonstop, and at 9:30 am Monday Cognition agreed to acquire Windsurf. Every employee received accelerated vesting and payouts, and a Monday all-hands celebrated the merger.SimpleBench results got updated. Grok 4 came 2nd with 60.5% score. This is quite impressive, because most SimpleBench questions remain private, their text never enters training corpora, so models cannot memorize answers or overfit.
SimpleBench is a 200-plus question multiple-choice benchmark targeting everyday reasoning that current LLMs mishandle, covering spatio-temporal puzzles, social intuition, and trick wording.

🧑🎓 Resource: A study explores what AI 2027 might look like.

Late 2025 OpenBrain’s giant datacenters enable training runs at about 1,000 × GPT-4 compute (≈10^28 FLOP)
Early 2026 Agent-1 makes OpenBrain’s research move 50% faster than it would without AI coders
Mid 2026 China centralizes efforts yet holds only 12% of global AI compute, funnelling it into the Tianwan CDZ hub
Late 2026 the stock market leaps 30% on AI optimism, while the new Agent-1-mini costs 10 × less than its predecessor and starts undercutting junior coders
Jan 2027 always-learning Agent-2 triples OpenBrain’s research speed by updating its weights daily
Feb 2027 Chinese operatives steal the Agent-2 weights, spiking the US-China AI arms race
Mar 2027 breakthroughs yield Agent-3: 200,000 copies match 50,000 elite engineers at 30 × speed, giving a 4 × overall R\&D boost
Jul 2027 OpenBrain releases Agent-3-mini, 10 × cheaper, and surveys show 10% of Americans already call an AI a close friend
Aug 2027 Washington treats the intelligence surge like a new Cold War, worrying about AI-driven cyber, propaganda, and nuclear stability
Sep 2027Agent-4 delivers a year of progress every week, but early tests flag misalignment risks
Oct 2027 a leaked memo on Agent-4’s dangers triggers congressional probes after claims it could automate bioweapons and most desk jobs


That’s a wrap for today, see you all tomorrow.