
🏆 Google has taken the AI lead again with Gemini 3.1 Pro.
Lyria 3 generates music in-Gemini, new CEO survey exposes AI’s productivity paradox, Microsoft advances durable data-center storage, and researchers rethink reward-only AI learning.
Read time: 10 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (19-Feb-2026):
🏆 Google has taken the AI lead again with Gemini 3.1 Pro.
🎵 Google Lyria 3: Make 30-sec AI music tracks right inside Gemini
🗞️ A new international survey by the National Bureau of Economic of nearly 6,000 CEOs & executives finds that AI is widely adopted but barely shows up in jobs or productivity yet, echoing Robert Solow’s old “productivity paradox” from the early computer era.
🗞️ Breakthrough research by Microsoft, the most durable archival storage for data centers.
🗞️ New paper shows how LLMs can learn like human, with experience, reflect, and then learn.
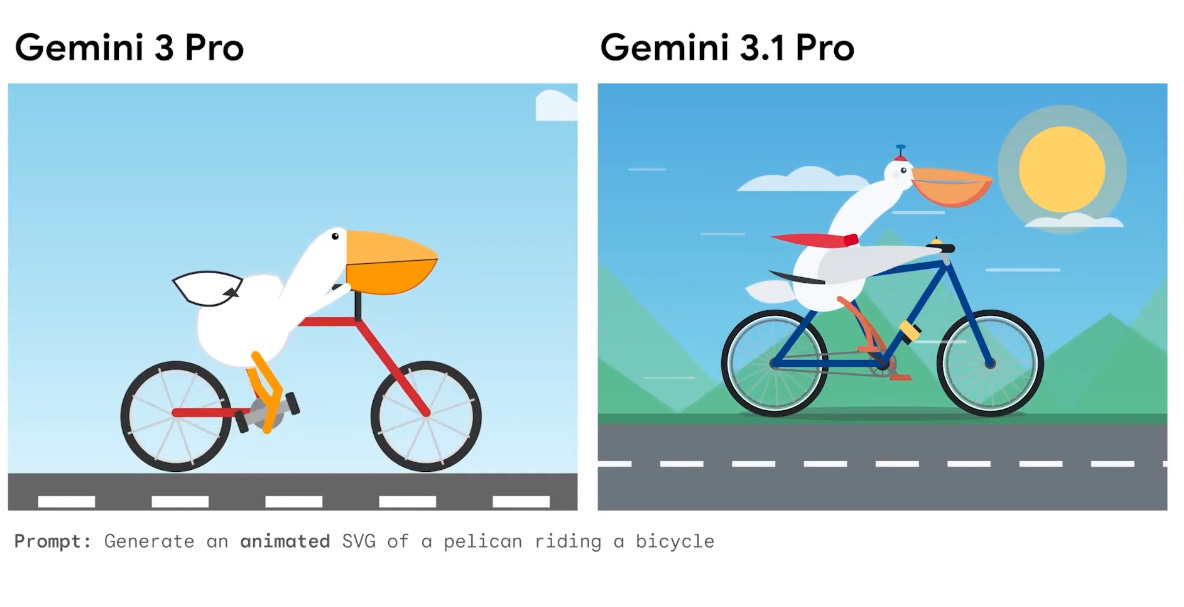
🏆 Google has taken the AI lead again with Gemini 3.1 Pro

Gemini 3.1 Pro just dropped by GoogleDeepMind with better coding and long context support.
Massive improvement on ARC AGI-2 (the logic puzzle benchmark), with 77.1% up from 31.1% for its predecessor, Gemini 3 Pro.
Great for super complex tasks like visualizing difficult concepts, synthesizing data into a single view and agentic tasks.
Gemini 3.1 Pro Preview leads the Artificial Analysis Intelligence Index, 4 points ahead of Claude Opus 4.6 while costing less than half as much to run.
You can access it in public preview via Google AI Studio, and with Gemini API, plus Gemini CLI, Google Antigravity, and Android Studio.
On Vertex AI, the listed version is gemini-3.1-pro-preview, marked Public preview
🎵 Google Lyria 3: Make 30-sec AI music tracks right inside Gemini
Lyria 3 just dropped by GoogleDeepMind, their latest and most advanced music model, and they put it into the Gemini app. So anyone can make a 30s song from text or an uploaded image or video in a beta rollout.
Go from idea, image, or video to music in seconds! It also generates vocals and lyrics automatically, and adds steering knobs like tempo, vocal style, and precise lyrics, which earlier music tools often left to the user or made hard to control.
Under the hood, this is a multimodal conditioning setup, where the same music model is guided by a text description plus optional visual context, then decodes audio that is meant to stay coherent while matching the prompt’s mood and story. Google is claiming higher audio quality and clearer words, including 48kHz stereo output in its Lyria line, which matters because artifacts and garbled lyrics are a common failure mode for music generation.
Every Gemini-generated track is watermarked with SynthID, and Gemini can also check uploads for that watermark as part of its audio verification flow. The official blog said “Music generation with Lyria 3 is designed for original expression, not for mimicking existing artists. If your prompt names a specific artist, Gemini will take this as broad creative inspiration and create a track that shares a similar style or mood.”
The beta launch is global for 18+ users in 8 languages, with higher limits for paid tiers, and Lyria 3 is also being used in YouTube’s Dream Track for Shorts soundtracks. This looks most useful for fast, shareable “soundtrack for a moment” creation, not careful music production, because the output is capped at 30s and the tool is tuned for speed and vibe matching.
🗞️ A new international survey by the National Bureau of Economic of nearly 6,000 CEOs & executives finds that AI is widely adopted but barely shows up in jobs or productivity yet, echoing Robert Solow’s old “productivity paradox” from the early computer era.

Despite that, executives predict over the next 3 years that AI will raise productivity by about +1.44%, lift output by about +0.76%, and cut employment by about -0.68%, while employees predict about +0.45% employment and about +0.92% productivity. This NBER study was conducted across the US, UK, Germany, and Australia, about 69% of firms say they use some AI, but more than 80% report no effect on employment or productivity over the last 3 years.
The paradox angle comes from 1987, when Robert Solow showed that despite major computing advances in the 1960s, productivity growth slowed instead of rising, falling from 2.9% in 1948 to 1973, to 1.1% after 1973. This was partly because firms first had to reorganize work to make the tech pay off.
Past evidence on AI has been messy because different surveys ask different questions, sample different kinds of firms, and often do not reach real decision makers, so adoption rates can swing by nearly 10x depending on design. This work changes the measurement by asking the same AI questions in 4 large, economy-wide business panels, and those panels recruit and verify senior executives rather than anonymous online respondents.
It also measures intensity, not just “does the firm use AI,” by asking executives how many hours per week they personally use AI, which averages 1.5 hours and includes 25% who report none. On the firm side, the most common reported use is text generation with LLMs at 41% of firms, followed by machine learning for data processing and visual content creation at about 30% each.
🗞️ Breakthrough research by Microsoft, the most durable archival storage for data centers.
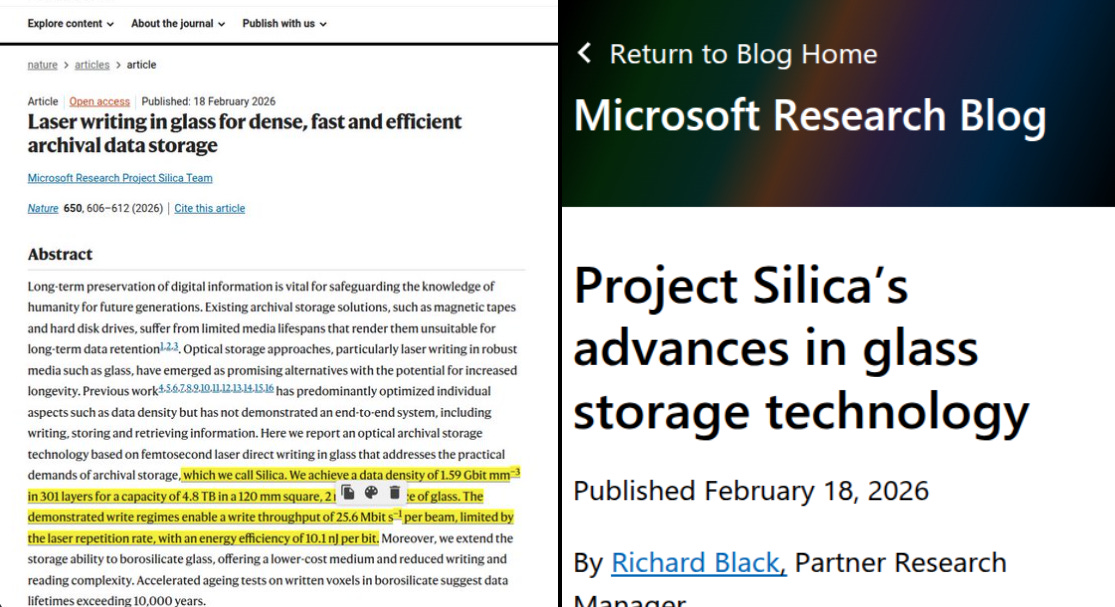
4.8TB inside a glass platter that could last 10,000 years.
In this work the platter is about 120mm by 120mm and about 2mm thick. Archives today usually use magnetic tape or disks, and those slowly degrade, so big organizations have to keep copying data forward to new media every few years to avoid losing it.
Glass is different story because the written marks are physical changes inside the material, and glass is naturally resistant to water, heat, dust, and electromagnetic interference. Those marks are stacked through the depth of the glass in hundreds of layers, like a 3D barcode.
Earlier versions mostly used fused silica, a purer and more expensive glass. The newer approach works in cheaper borosilicate glass, like kitchen cookware, and a “phase voxel” needs 1 pulse per stored spot. The big deal in this new work is a possible “write once, store for generations” layer that could cut migration work for data centers and cultural archives.
🗞️ New paper shows how LLMs can learn like human, with experience, reflect, and then learn.

For decades, we’ve trained AI to chase rewards. But humans don’t just optimize outcomes. We experience, reflect, then learn.
Experiential Reinforcement Learning (ERL) trains a model by letting it fail once, reflect on why, retry, and then learn the retry. ERL keeps the usual reward score, but adds a written self-reflection from feedback that guides a 2nd attempt.
On Qwen3-4B, Sokoban reward rose from 0.06 to 0.87, and HotpotQA rose from 0.45 to 0.56 token-level F1, a match score for the answer text. In standard reinforcement learning with verifiable rewards (RLVR), learning mostly sees a single reward number for a full multi-step attempt, so figuring out what to change can be slow.
ERL inserts an extra step that turns feedback into a specific correction, and reinforces the full sequence of 1st attempt, reflection, and improved 2nd attempt. It then distills the successful 2nd attempts back into the base model so it can act from the original input without reflection at deployment. Reflection is mainly triggered on failures to avoid instability and reward hacking, and a cross-episode memory can reuse good reflections but can also spread bad ones.
The picture compares 2 ways an AI learns in a new game-like world when it starts with no clue what works.

In the top row, reinforcement learning with verifiable rewards (RLVR) mostly just tries moves, gets no reward, and then repeats similar bad attempts because it does not store a clear lesson from the failure. The “forget” and “back and forth” idea means the agent keeps exploring without locking in a specific correction, since the only signal is a single reward number at the end.
In the bottom row, Experiential Reinforcement Learning (ERL) still does trial and error, but after failing it writes a short reflection like “walls block me” or “I can push boxes,” then uses that to guide a better 2nd attempt. The “experience internalization” idea means ERL turns the failure into an explicit rule or hint, then trains the model to behave like it remembered that rule next time. The big deal is that the model learns a reusable fix from feedback, instead of just learning that the whole attempt was good or bad, which helps a lot when rewards are rare and only show up at the end.
Overview of Experiential Reinforcement Learning (ERL)

Step 1 is the first attempt, where the policy takes the task input x and produces an answer y(1), then the environment returns feedback f, like success or failure plus hints. Step 2 is self-reflection, where the same policy reads the first attempt and the feedback and writes a short correction note Δ, and it can also pull useful notes from a cross-episode memory that stores past corrections.
Step 3 is the second attempt, where the policy uses the task plus the reflection note Δ to produce a better answer y(2), and reinforcement learning updates the policy using how well these attempts did. The bottom “internalization” path is the main trick, which takes successful second attempts and trains the model with supervised fine-tuning (SFT), meaning it learns to output y(2) directly from x without needing to write Δ at test time. The big deal is that the model practices a fix immediately, then gets trained to act like it remembered the fix, so improvement is more stable than just rewarding or punishing whole attempts.
That’s a wrap for today, see you all tomorrow.