
🗞️ Google just launched Gemini 3.1 Flash TTS, a text-to-speech model that takes scene direction, speaker notes

Read time: 9 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (15-Apr-2026):
🗞️ Google just launched Gemini 3.1 Flash TTS, a text-to-speech model that takes scene direction, speaker notes
🗞️ Today’s Sponsor: webAI just open-sourced a vision-language retrieval model (ColVec1) that’s now at #1 on ViDoRe V3 by searching document pages directly instead of reading them through OCR first.
🗞️ OpenAI just turned the Agents SDK into a long-running agent runtime with sandbox execution and direct control over memory and state.
🗞️ OpenAI unveils GPT-5.4-Cyber a week after Anthropic’s announcement of AI model
🗞️ Fortune published a piece. From Molotov cocktails to data center shutdowns, the AI backlash is turning revolutionary
🗞️ Google just turned Gemini in Chrome prompts into reusable one-click tools called Skills.
🗞️ Google just launched Gemini 3.1 Flash TTS, a text-to-speech model that takes scene direction, speaker notes, and inline audio tags, so speech can be steered like a performance instead of read like a script.
Rolling out from today
For developers in preview via the Gemini API and Google AI Studio
For enterprises in preview on Vertex AI
For Workspace users via Google Vids
Traditional TTS systems mostly convert words into sound, but this model also follows instructions about pace, tone, accent, and delivery, which means the prompt can shape how a line lands, not only how it is pronounced.
Flat speech breaks dialogue systems fast, so speaker-level specificity matters because 2 voices can stay distinct, react differently, and even shift emotion mid-sentence without switching models.
The model supports 70+ languages, native multi-speaker dialogue, reusable voice settings through the API, and an Artificial Analysis Elo of 1211.
🗞️ Today’s Sponsor: webAI just open-sourced a vision-language retrieval model (ColVec1) that’s now at #1 on ViDoRe V3 by searching document pages directly instead of reading them through OCR first.

Finally we have “Frontier-level retrieval. No OCR. No preprocessing. Built for real documents.”
The real problem with document retrieval was never just reading more text, it was losing the page before the search even began.
ViDoRe V3 benchmark is one of the gold standard for evaluating multimodal document retrieval in enterprise settings.
The models (ColVec1) come in 4B and 9B variants (both are on Huggingface), with Qwen 3.5 vision-language as the backbone, and trained on a dataset of ~2M question-image pairs. Can be easily run on consumer level GPUs
The AI world usually goes chasing size first. webAI has long believed that being smarter matters more than being bigger. This release clearly shows that page layout is part of meaning, not just formatting noise.
Multimodal RAG has looked like a scale problem for a while, but this release makes a strong case that the real gap was retrieval. OCR-first systems flatten a page into text and often damage the very clues that carry meaning, like table alignment, chart context, columns, spacing, and scanned layouts.
ColVec1 keeps the page as an image, so retrieval starts from the full visual document rather than a lossy text extraction step.
The model uses one shared VLM for text queries and page images, then turns each token into many vectors instead of one pooled embedding. That multi-vector late interaction setup lets a query match the best local regions of a page, which helps on manuals, filings, papers, and dense tables where one global vector misses detail.
webAI says it trained on about 2M question-image pairs across DocVQA, PubTables, TAT-QA, ViDoRe-style data, multilingual sets, and synthetic document queries.
Check out ColVec1 models on HuggingFace. The 9B is here and the 4B is here.
And read their official technical blog on this model.
🗞️ OpenAI just turned the Agents SDK into a long-running agent runtime with sandbox execution and direct control over memory and state.

Before this, developers often had to stitch together 3 separate pieces themselves: the model loop, the machine where code runs, and the memory or state that lets a task continue later.
That sounds small, but it is usually where agents fail, because a model may know what to do yet still lose files, lose progress, leak secrets, crash mid-task, or restart from scratch.
The new SDK gives one standard setup for that missing layer: a harness that manages the agent loop, plus a sandbox where the risky work happens, plus control over when memory is created and where it is stored.
Runs can now survive pauses and failures through snapshotting and rehydration.
Developers can inspect the open-source harness, choose when memories are written and where they live, and use Cloudflare, Vercel, Modal, E2B, or their own environment.
This image explains the single biggest architecture change in the new Agents SDK.

The left box is the trusted control layer, where the harness, the agent loop, the tools, and the secrets live. The right box is the untrusted work layer, where the agent can run code, inspect files, search through data, and write outputs inside a sandbox.
The point is that the agent can still do real computer work without putting your credentials, databases, and internal services inside the same environment as model-generated code.
That separation lowers risk, because the server talks to databases and the web from a trusted place, while the sandbox gets only the files and actions it needs for the task. It also makes long jobs more practical, because the harness can keep track of the run even if the sandbox is replaced, paused, or restarted.
So overall, OpenAI is defining a cleaner boundary between thinking, control, and execution.
🗞️ Anthropic adds routines to run workflows via API and GitHub

Anthropic just turned Claude Code routines into always-on software jobs that can start on a schedule, from an API call, or from GitHub events, and they keep running on Anthropic-managed infrastructure even when your computer is off.
Routines now act like hosted workflow runners: you save a prompt, attach repositories, secrets, network rules, and connectors, and each trigger spins up a fresh Claude session that can inspect code, edit files, review changes, and create a PR.
The useful part is the trigger design, because the API path gives each routine a protected HTTP endpoint with an optional text payload, while GitHub triggers launch separate sessions for matching repo events, with no shared session state across later events.
I think this is a solid product move because it packages cron jobs, webhooks, and repo automation into one LLM workflow layer that teams can plug into tools they already use.
🗞️ OpenAI unveils GPT-5.4-Cyber a week after Anthropic’s announcement of AI model

OpenAI just widened its Trusted Access for Cyber program and introduced GPT-5.4-Cyber, a more cyber-permissive model built to help verified defenders do harder security work.
What changed is not mainly “the base intelligence,” but the permission settings, tuning, and access policy for cybersecurity work.
Normal models often refuse or heavily restrict cyber-related requests because those requests can look dangerous even when a defender is doing legitimate work like malware analysis, vulnerability research, or reverse engineering.
OpenAI is saying: for verified security defenders, it will provide a version of GPT-5.4 that is less likely to refuse legitimate cyber tasks and is better tuned for defensive security workflows.
The problem is that modern AI can help both attackers and defenders, so OpenAI is trying to separate ordinary access from higher-trust access instead of treating every cyber request the same.
Its answer is a tiered system built on identity checks, trust signals, and tighter deployment controls, so more capable security features go to people and teams that can show they are doing legitimate defensive work.
The new part is GPT-5.4-Cyber, a version of GPT-5.4 with a lower refusal boundary for approved security tasks, including binary reverse engineering, which matters because defenders often need to inspect compiled software without source code to judge malware risk, find bugs, or test robustness.
OpenAI is pairing that with a broader rollout of Trusted Access, expanding from a small program to thousands of verified individual defenders and hundreds of teams, while keeping the most permissive access limited and more closely monitored.
The bigger technical bet is that cyber safety should scale with model capability, so OpenAI is mixing stronger safeguards for general users with more freedom for authenticated defenders instead of using one flat policy for everyone.
My read is that this is a serious shift from “AI for coding” toward AI for operational security work, and the real test is whether verification stays strict enough to block abuse without slowing down the defenders it is supposed to help.
🗞️ Fortune published a piece. From Molotov cocktails to data center shutdowns, the AI backlash is turning revolutionary
The story is less about 1 attacker than a wider pileup of anger around jobs, trust, and the feeling that AI firms promised relief while many people got more risk, more uncertainty, and fewer clear benefits.
Young people sit at the center because they use AI a lot yet often see it as something that can flatten entry-level work, flood the internet with synthetic slop, and give abusive people cheap tools for manipulation at personal scale.
The same backlash now shows up far from social media, because towns fighting new data centers are reacting to higher power demand, water use, noise, and land pressure rather than abstract fears about superintelligence.
The deeper split is between the industry story, where AI soon expands abundance, and the public story, where AI already acts like a bargaining chip for layoffs, a source of everyday fraud, and a machine that keeps asking society to absorb the costs first.
🗞️ Google just turned Gemini in Chrome prompts into reusable one-click tools called Skills.
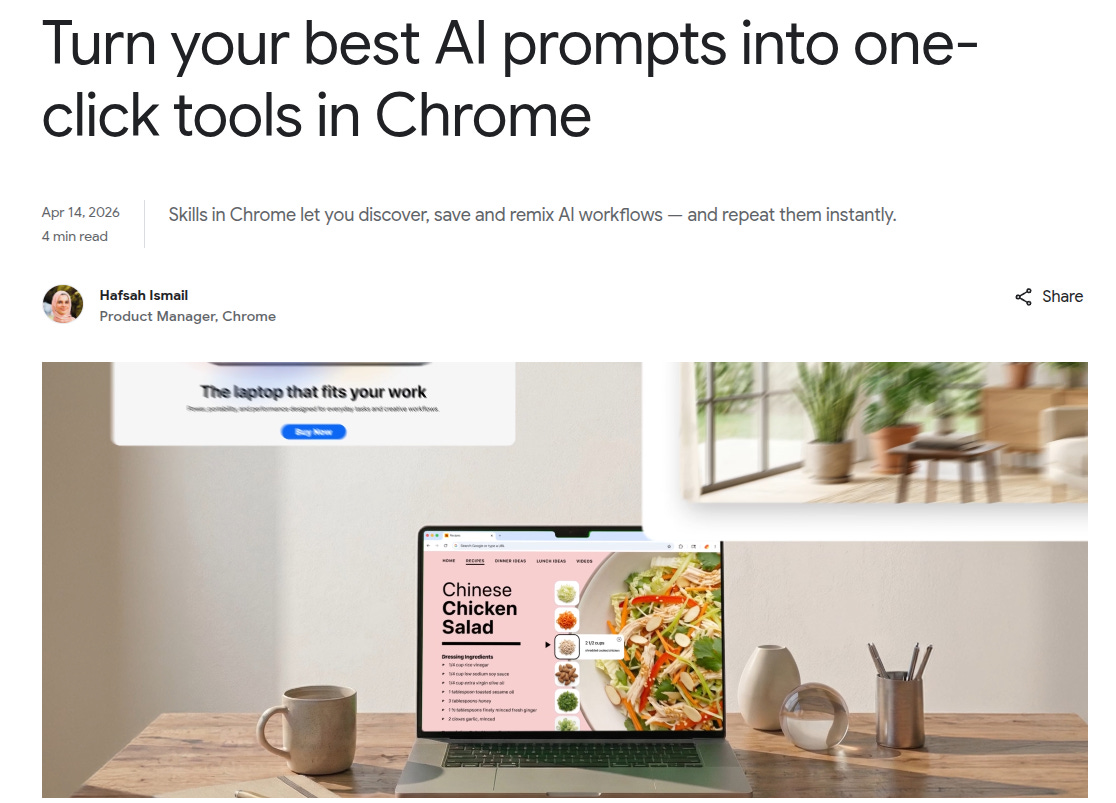
That changes AI in the browser from one-off chat to a lightweight workflow system, where one saved prompt can compare products across tabs, scan long pages for facts, or rewrite a recipe around a food rule.
Chrome also adds a Skills library, so people can start from ready-made prompts, save them, and then edit the wording instead of building every workflow from scratch.
Google says Skills use the same safeguards as Gemini in Chrome, including confirmation before actions like sending email or adding calendar events, which keeps the prompt useful without giving it silent control.
My view is that this is a small product change with a real behavior shift, because the useful unit stops being the chatbot and becomes the repeatable prompt workflow.
That’s a wrap for today, see you all tomorrow.