
🛠️ Google just published a deep dive on how they pushed Gemini 3 Pro’s vision capabilities across document, spatial, screen and video understanding.
Google flexes Gemini 3 Pro’s vision upgrades, OpenAI drops GPT-5.2 next week, China’s labs publish 300+ pages on coding LLMs, and TPUv7 enters the Nvidia fight.

Read time: 10 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (6-Dec-2025):
🛠️ Google just published a deep dive on how they pushed Gemini 3 Pro’s vision capabilities across document, spatial, screen and video understanding.
🏆 OpenAI is rushing out GPT-5.2 next week to answer Google’s Gemini 3
👨🔧 Alibaba, ByteDance, Tencent and a few other Chinese labs published a fantastic 304 page overview paper on training LLMs for coding
🧠 Future of Life Institute that aims to steer AI into a safer direction released an AI Safety Index, and all top models get very bad score
📚Google released a solid guide on context engineering for working with multi-agent systems.
🧠 Google is finally selling TPUv7 as a true Nvidia alternative - Semi Analysis published a detailed report.
🛠️ Google just published a deep dive on how they pushed Gemini 3 Pro’s vision capabilities across document, spatial, screen and video understanding.

They upgraded the whole vision pipeline, from perception to reasoning.
The model now “derenders” messy scans into structured code like HTML or Markdown, so text, tables, charts, and figures are reconstructed cleanly. On long reports it traces evidence across pages and tables, shown by the 62-page Census example and an 80.5% score on the CharXiv reasoning benchmark.
This is how document answers become grounded, accurate, and explainable. They added spatial grounding.
The model can output pixel-precise coordinates, string points into paths over time, and reference objects by open vocabulary. That lets it plan steps on real scenes, helpful for robotics or AR where you can say “point to the screw” and get actionable, localized output.
They hardened screen understanding. It reliably reads desktop and mobile UIs, keeps track of widgets, and clicks with precision. The demo shows it completing a spreadsheet task by creating a pivot table and summarizing revenue, which is the kind of repeatable flow agents need.
They boosted video comprehension. Sampling at 10 FPS, 10x the default speed, it captures fast actions like a golf swing. An upgraded “thinking” mode models cause and effect over time, and the system can extract knowledge from long videos then emit working app code or structured outputs.
They also added fidelity controls. Inputs keep native aspect ratio for better quality, and a media_resolution parameter lets developers trade detail for cost and latency, choosing high resolution for dense OCR or low resolution for quick scene reads. Real uses span education, law, finance, and medical imaging, with strong public benchmark results.
🏆 OpenAI is rushing out GPT-5.2 next week to answer Google’s Gemini 3

OpenAI Rushes GPT-5.2 After Google’s Gemini Surge
The update aims to close the performance gap and push ChatGPT toward better reasoning speed, reliability, and customizability. Expect changes that cut response latency, reduce tool call failures, and make system behavior easier to steer with instructions or profiles, since those are the knobs that most users actually feel day to day.
👨🔧 Alibaba, ByteDance, Tencent and a few other Chinese labs published a fantastic 304 page overview paper on training LLMs for coding

A MASSIVE 303 page study from the very best Chinese Labs.
The paper explains how code focused language models are built, trained, and turned into software agents that help run parts of development.
These models read natural language instructions, like a bug report or feature request, and try to output working code that matches the intent.
The authors first walk through the training pipeline, from collecting and cleaning large code datasets to pretraining, meaning letting the model absorb coding patterns at scale.
They then describe supervised fine tuning and reinforcement learning, which are extra training stages that reward the model for following instructions, passing tests, and avoiding obvious mistakes.
On top of these models, the paper surveys software engineering agents, which wrap a model in a loop that reads issues, plans steps, edits files, runs tests, and retries when things fail.
Across the survey, they point out gaps like handling huge repositories, keeping generated code secure, and evaluating agents reliably, and they share practical tricks that current teams can reuse.
🧠 Future of Life Institute that aims to steer AI into a safer direction released an AI Safety Index, and all top models get very bad score
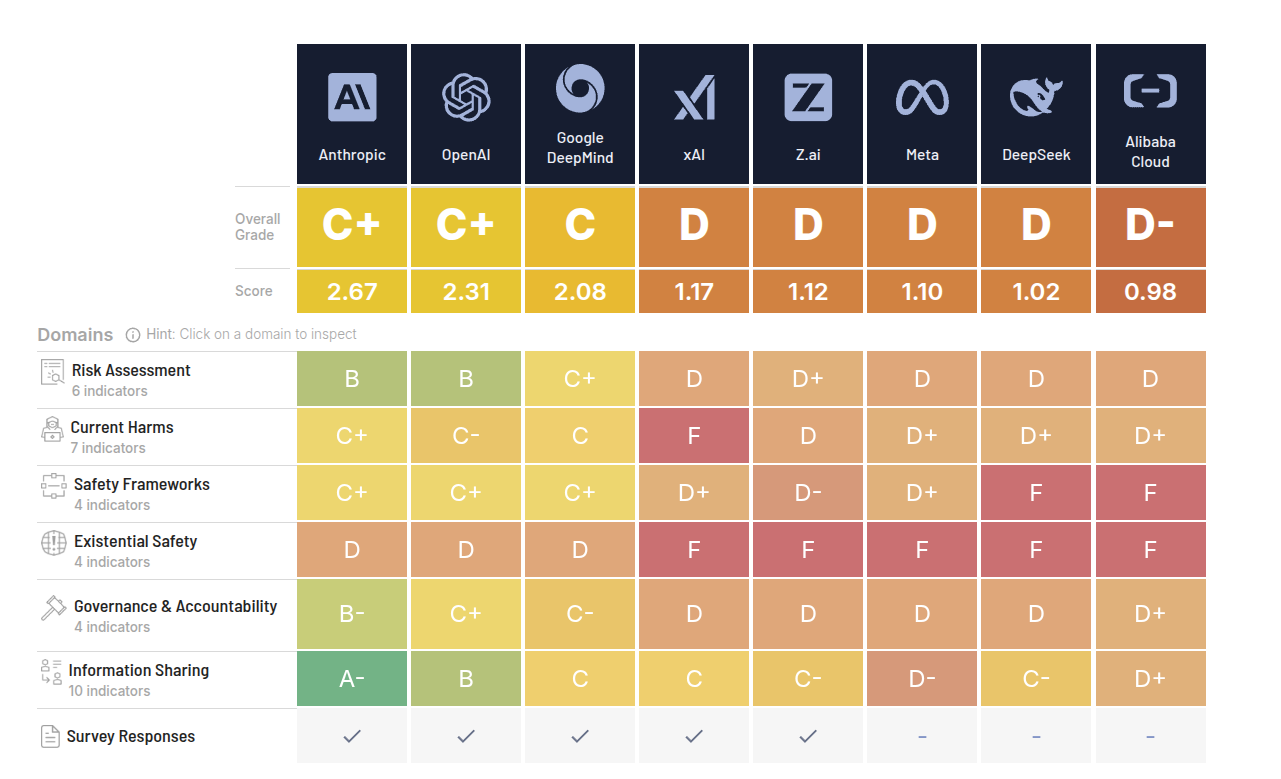
A safety report card ranks AI company efforts to protect humanity, and gave C-range grades to the best labs and failed every company on existential risk.
The index scores 8 labs on 35 indicators across 6 dimensions, and even the top labs only get C-level grades while the rest sit in D range.
These benchmarks measure how seriously AI labs are treating safety in practice, not how smart their models are.
They look at things like whether a company has a clear safety plan, does systematic risk assessments, stress tests its models against dangerous uses, shares information with regulators and other labs, and has internal governance that can actually pause or stop risky deployments.
They also score whether there is real investment in safety research, red teaming, incident response processes, and whether the company is transparent about failures and known risks.
They measure existential risk from AI, meaning scenarios where AI helps cause civilization-level damage, like enabling large scale bioweapons, breaking key infrastructure, or powerful systems slipping out of effective human control.
📚Google released a solid guide on context engineering for working with multi-agent systems.
The guide replaces giant prompts with a compiled view over state that splits information across Working Context, Session, Memory, and Artifacts.
Every call rebuilds Working Context from instructions, selected Session events, memory results, and artifact references, using ordered flows and processors.
A contents processor walks the Session log, drops noise, formats the remaining events as chat history, and writes that into the model request.
ADK controls growth with context compaction, filtering, and context caching, summarizing old spans, dropping useless events, and reusing a stable prefix across calls.
Large payloads become Artifacts outside the prompt, and long lived knowledge goes into Memory, whose MemoryService tools search and inject only relevant snippets into the window.
ADK handles multiagent setups with agents as tools and Agent Transfer, scoping which parts of Working Context each subagent sees so specialists get only needed history and do not hallucinate actions.
Overall, this guide pushes agent builders to treat context engineering as shared infrastructure on the same level as storage and compute, instead of blind prompt stuffing.
🧠 Google is finally selling TPUv7 as a true Nvidia alternative - Semi Analysis published a detailed report.
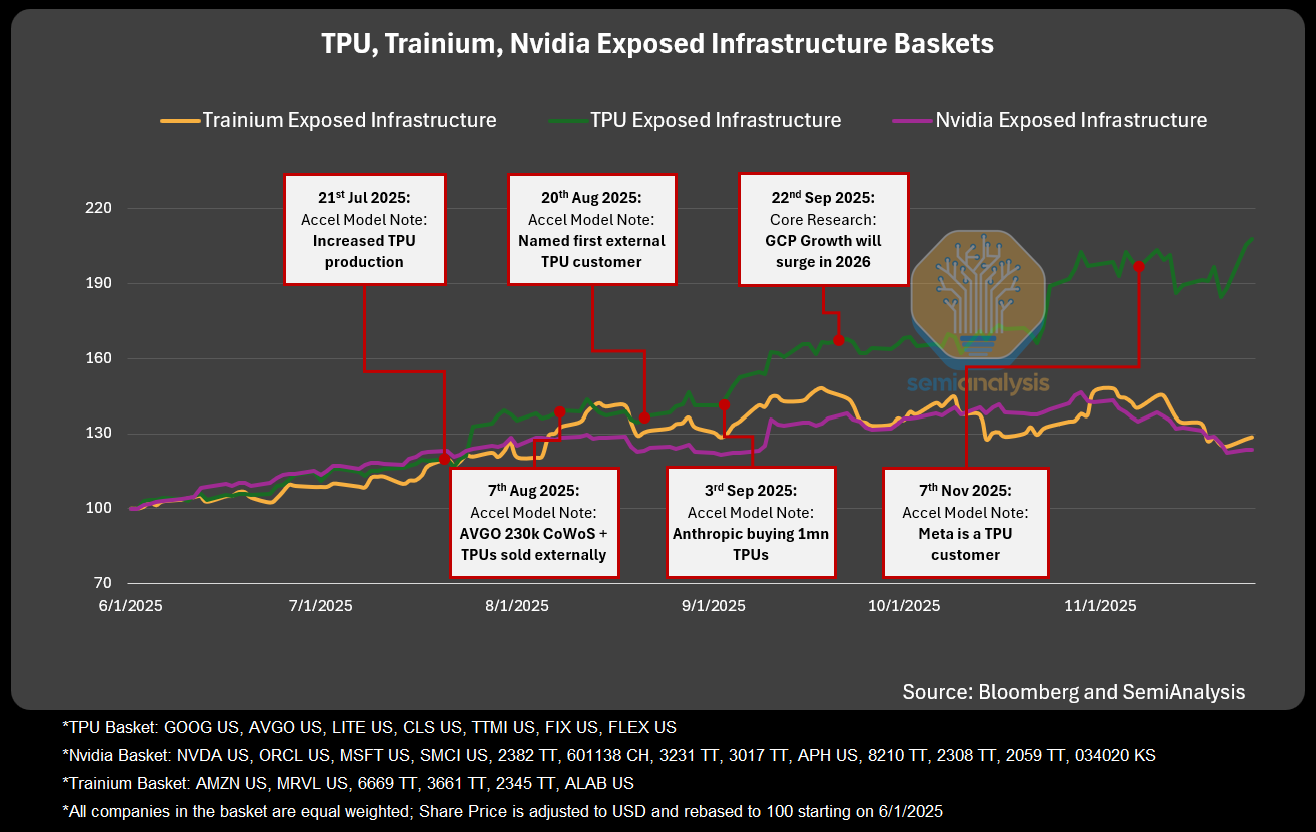
Anthropic will own part of the TPUv7 fleet and rent the rest from Google Cloud, so a big slice of future training budget flows to Google instead of Nvidia.
The big deal is that TPUv7 is close to Nvidia Blackwell performance but cuts training cost per useful flop by around 30% to 50%, thanks to lower chip margins and tightly packed liquid cooled racks.
TPUv7 pods link up to 9,216 chips in a 3D torus, and light based circuit switches connect pods into pools near 147K chips, so communication stays short and large models run efficiently.
Google is also fixing the software story by building a native PyTorch backend, plugging TPUs into vLLM, and letting experts write fast custom kernels, but the XLA compiler and runtime remain closed and harder to debug than CUDA.
Overall, this is the 1st real full stack rival to Nvidia, and labs that do the extra engineering can reach Blackwell level models with cheaper training flops, cheaper memory bandwidth, and stronger bargaining power.
OpenAI used the threat of switching to TPUs to negotiate cheaper Nvidia prices, even before they actually ran a single training job on TPUs.
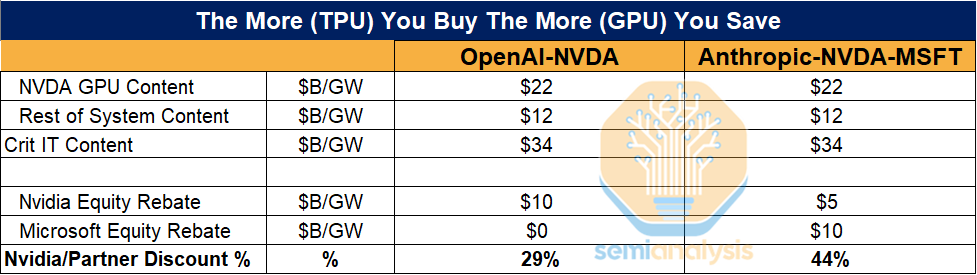
Once Google started offering serious TPU capacity to labs like Anthropic and talking to others, Nvidia suddenly had a real competitor for big AI deals, so Nvidia could either lose huge orders or lower effective pricing for key customers.
OpenAI can now tell Nvidia something like: “Google will sell us X PFLOPs of TPUv7 at an effective cost of Y dollars per PFLOP, so if you want us to stay on your GPUs at scale, you need to move closer to that,” and Nvidia has to respond because the risk of losing OpenAI is massive.
The result is Nvidia quietly giving OpenAI better commercial terms on the whole GPU fleet, such as bigger discounts, better credits, or improved bundle pricing on GB200 and related systems, which the report estimates is roughly a 30% lab wide cost reduction.
That’s a wrap for today, see you all tomorrow.