

Read time: 11 mint
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (5-Jun-2025):
🥉 Google just rolled out an upgraded preview of Gemini 2.5 Pro.
🚨 Cursor 1.0 launches with BugBot for PR reviews, async Background Agent, and per-project Memories.
🗞️ Byte-Size Briefs:
Anthropic upgrades Claude to handle 10x more files dynamically
OpenAI, Google offer $20M+ to retain 10,000x AI researchers
🧑🎓 My Opinion Piece
AGI and Implications for Timelines
🥉 Google just rolled out an upgraded preview of Gemini 2.5 Pro

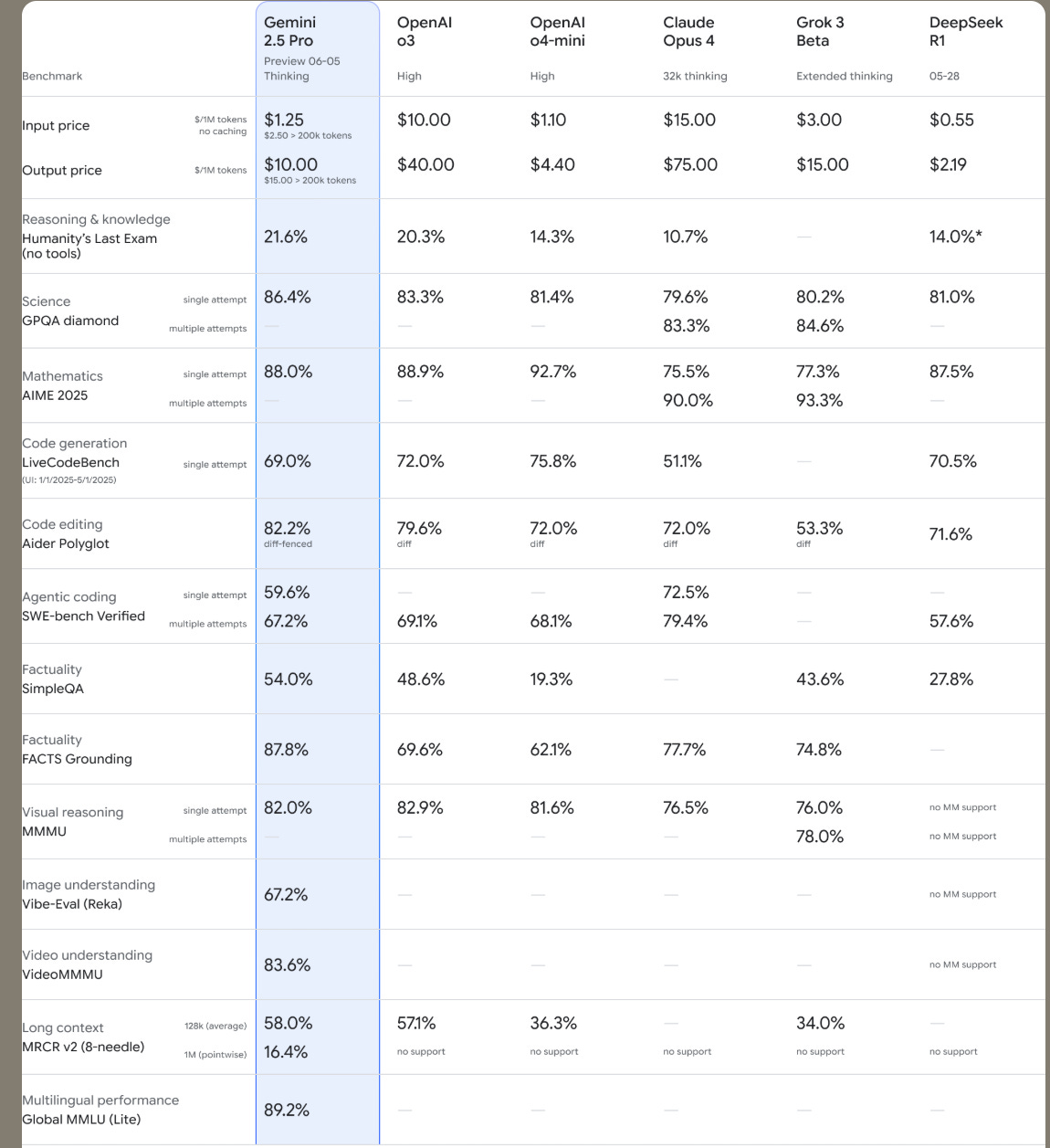
The latest Gemini 2.5 Pro update is now in preview.
It’s better at coding, reasoning, science + math, shows improved performance across key benchmarks (AIDER Polyglot, GPQA, HLE to name a few), and leads
This new Gemini-2.5-Pro (06-05) takes the No-1 spot across all Arenas again!
🥇 #1 in Text, Vision, WebDev
🥇 #1 in Hard, Coding, Math, Creative, Multi-turn, Instruction Following, and Long Queries categories.
→ This model will become the stable, enterprise-ready default version in the next few weeks.
→ It scores 1470 on LMArena, up by 24 Elo points, and 1443 on WebDevArena, up by 35. These are leading scores across both evals. Gemini 2.5 Pro also dominates coding-focused benchmarks like Aider Polyglot and performs at the top level on GPQA and HLE—two of the hardest reasoning/math/science tests.
→ The model improvements also target structured output and stylistic formatting, making it easier for developers to generate usable responses without post-processing.
→ It’s available immediately in the Gemini API via Google AI Studio and Vertex AI. Developers can now control cost and latency via new “thinking budgets.”
→ It’s also shipping inside the Gemini mobile app for general use, with the same model under the hood as the API.
→ This version builds on the one shown at Google I/O and represents the finalized, stable release, not an experiment.
🚨 Cursor 1.0 launches with BugBot for PR reviews, async Background Agent, and per-project Memories.
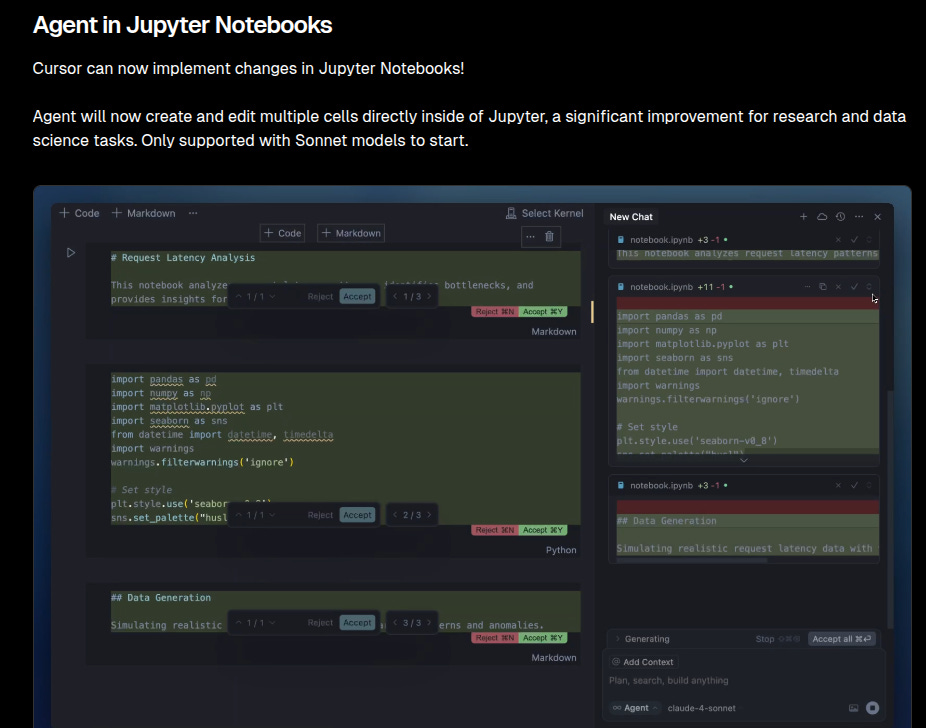
Cursor 1.0 launches with new tools aimed at automating code review and research workflows. The release adds Memories, a per-project feature that learns facts and coding patterns from your interactions and references them in the future.
→ Cursor’s new BugBot automates GitHub PR reviews. It scans pull requests and drops inline comments with “Fix in Cursor” buttons. Clicking them pulls the issue back into the editor with a pre-filled fix prompt.
→ Background Agent is now live for everyone. It runs tasks asynchronously via Cmd/Ctrl+E, so edits don’t block the UI. Works inside Jupyter notebooks too, creating/editing multiple cells natively (limited to Claude Sonnet 3.5 for now).
→ New Memories feature stores per-project facts and patterns from your past interactions. Cursor can recall them in later sessions. Opt-in via Settings → Rules.
→ One-click MCP server setup now includes OAuth. You can plug external tools into Cursor using an “Add to Cursor” link. Auth is handled securely through OAuth if supported.
→ Cursor now renders Mermaid diagrams and markdown tables directly in chat. No toggling or external tools needed.
→ New dashboard adds per-user/team analytics, usage breakdown by tool/model, and updated profile settings.
→ Cursor also pushed a unified, request-based pricing model with simplified Max Mode for top models. Token-based, no more long context add-ons.
→ Multi-root workspaces allow editing across multiple codebases in a single Cursor session. Ideal for large or cross-project dev.
→ The new Tab model suggests edits across files and improves chained refactors. Works faster and more naturally.
→ Fast search-and-replace agent tool enables subfile-level edits in long files—rolled out first to Anthropic models.
🗞️ Byte-Size Briefs
Claude now handles 10x more project data by switching to a smarter file retrieval mode when limits are exceeded. This means you can add far more files to a Claude project, and it’ll automatically retrieve relevant content instead of relying on a static context window. This is rolling out to all paid Claude plans over the coming days.
A few AI researchers in big labs now earn $20M a year just so they don’t quit and join a rival lab. Google, OpenAI, and xAI are throwing massive equity, early vesting, and bonuses at a few hundred engineers whose work is seen as exponentially more valuable than average developers. These few dozen to few hundred researchers are considered "10,000x contributors" — a reference to Sam Altman’s framing that their impact dwarfs that of typical engineers. A few top OpenAI researchers considered joining Ilya Sutskever’s new company, SSI(Safe SuperIntelligence), but OpenAI countered with $2 million retention bonuses and equity increases worth up to $20 million to keep them.
🧑🎓 My Opinion Piece
AGI and Implications for Timelines
(I have longer time-frame for AGI)

Every week it feels like someone is declaring that Artificial General Intelligence (AGI) is just around the corner. OpenAI’s CEO recently mused that “systems that start to point to AGI are coming into view,” imagining cures for diseases and astonishing growth, and Anthropic’s CEO said he believes AI that “surpass[es] humans in every task” could arrive “within 2–3 years”.
That kind of optimism is infectious. But when I actually use today’s AI models, I keep noticing a fundamental limitation that makes me think true AGI might take a bit longer: these models can’t learn continuously the way humans do. They’re basically stuck in place after their initial training, no matter how impressive they seem in isolated tasks.
In the current paradigm, an AI model learns on a massive dataset during a one-and-done training phase, and after that its knowledge and behavior become largely static. The AI can answer questions or perform tasks based on what it learned in training, but it won’t adapt or get better from new information in real time. If the world changes or you need the model to pick up a new skill, you can’t just teach it on the fly – you typically have to retrain or fine-tune the whole model with new data, a huge undertaking that can take months and tens of millions of dollars for the largest models.
It’s an oddly brittle setup when you think about it. Unlike a human worker who learns something new every day on the job, today’s AI is frozen in “first attempt” mode – it will make the same mistakes over and over unless its developers literally rebuild its brain via retraining.
This lack of online learning means current AI assistants and large language models have no long-term memory of past interactions. They can’t accumulate experience or refine their behavior over time in the wild.
I’ve found this to be a major bottleneck in using AI for any complex, white-collar workflow. If I have to employ an AI in my team, you can’t build a true working relationship with it because it never actually learns. It won’t remember the style guidelines you prefer, the corrections you gave it yesterday, or the nuanced project requirements that changed last week.
Researchers have observed this gap as well: today’s top models may achieve superhuman scores on static benchmarks, yet they “do not seem to be robustly helpful in automating parts of people’s day-to-day work.” In fact, one analysis in early 2025 found that while the best models could succeed on tasks that take a human expert a few hours, they could only reliably handle tasks that would take a person a half an hour max – beyond that, their success rates plummet.
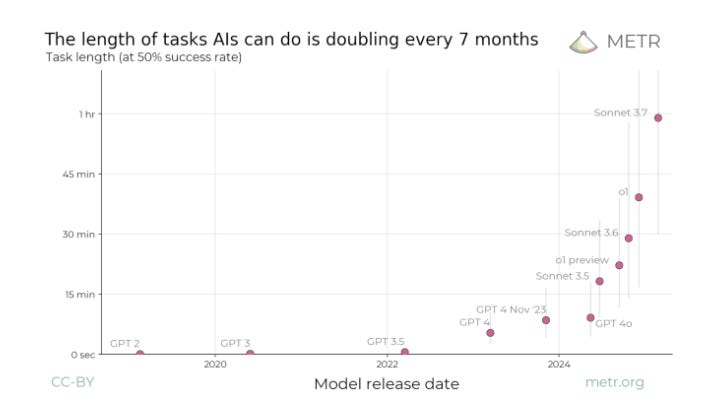
So that goes back to the problem that LLMs still excel at short, well-defined tasks, but for anything open-ended or long-running, they inevitably go off track or need constant human intervention.
Consider the vision of an AI agent that could “go do my taxes” – sift through your emails and receipts, ask others for missing documents, categorize expenses, and file the proper forms. Some experts have forecast that we might have reliable AI agents for such end-to-end office tasks as soon as next year. Personally, I’m skeptical. Achieving that kind of autonomy would require the AI to coordinate a long sequence of actions across different applications and modalities (text, spreadsheets, emails, maybe images of receipts), all while handling unexpected inputs and errors gracefully. That’s a far cry from today’s setups. As one group of researchers noted, we’ve been spoiled by the abundance of internet text for training general language abilities, but we don’t have massive datasets of “how to use a computer like a human” to similarly train an AI agent.
The AI would need to learn from far more interactive experience or advanced simulations, and our current training methods (like reinforcement learning on simple game-like environments) are still rudimentary for this purpose. There’s also the practical challenge of evaluation: it’s easy to check if an AI wrote a decent summary or a bit of code, but much harder to verify if an AI correctly handled a complex, two-hour tax filing process without mistakes.
With so many steps involved, even a small error could derail the whole task, and you might not catch it until it’s too late. All these factors make me think that truly reliable, long-horizon AI agents – the kind that can take a vague goal and independently execute a multi-hour project – are further away than the most bullish predictions suggest.
This continual-learning bottleneck is a big reason why I lean towards longer timelines for AGI than some of the current hype. Yes, today’s models are astounding in many ways, but until they can learn and adapt on the fly, they’re not going to smoothly slot into the role of a human colleague or an autonomous executive assistant. I’m not alone in this cautious view: in a recent survey of hundreds of AI experts (early 2025), 76% of respondents said that simply “scaling up current AI approaches” is unlikely or very unlikely to succeed in delivering AGI.
In other words, most experts suspect that we need new breakthroughs – like fundamentally better learning capabilities – rather than just bigger models of the current type. Solving continuous learning could very well be that necessary breakthrough.
The moment we have AI assistants that improve with experience, we might see a phase change in deployment. Suddenly these systems won’t be stuck in first-try mode – they’ll be accumulating knowledge, personalizing to their users or organizations, and getting better at their tasks week over week.
Also, beneath the surface of scaling victories lie deeper cracks. A critical bottleneck is achieving true adaptive learning. "Catastrophic forgetting" remains pervasive: models struggle to assimilate new information without degrading prior knowledge —akin to a student forgetting arithmetic when learning geometry. This stems from how neural networks' distributed representations cause new updates to overwrite old ones. Current remedies, like parameter-efficient fine-tuning, often limit model expressivity or harm scalability. This inability to learn cumulatively impacts AI in complex, long-horizon tasks and dynamic environments , as retraining from scratch is prohibitive.
The "flywheel" concept, where AI helps to improve AI , is a compelling vision for potential exponential acceleration in development. However, this approach carries a subtle but significant risk. If the initial AI systems used to drive this flywheel possess inherent biases (e.g., learned from skewed training data), flaws in their reasoning processes, or an incomplete or inaccurate understanding of the world, these imperfections could be inadvertently amplified and deeply entrenched in future generations of AI systems created through this process. This could lead to a "garbage-in, garbage-out" scenario at a meta-level, where flaws are not just propagated but potentially magnified.
In summary, challenges that push out AGI timelines: the need for continual learning (to avoid one-and-done models), the difficulty of creating generally competent agentic AI, and looming limits in scaling, data, and integration.
So achieving a true, deployable AGI will require surmounting these hurdles, which could plausibly take 7-11 yearsof research. In particular, if current deep learning approaches don’t somehow crack online learning and broad autonomy soon, the consensus is that AGI may arrive later and more gradually than the most optimistic predictions – with 2030s being a reasonable bet for when all the pieces finally come together.
That’s a wrap for today, see you all tomorrow.