
🧠 Google Released Breakthrough New Architecture Which Effectively Scale To Larger Than 2m Context Window With Memory at Test Time
Google scales context windows to 2M, InternLM3-8B beats big players, Kokoro-82M TTS drops, Microsoft revolutionizes materials, and GPT-4 tutoring transforms Nigerian education.

Read time: 8 min 10 seconds
⚡In today’s Edition (16-Jan-2025):
🧠 Google Released Breakthrough New Architecture Which Effectively Scale To Larger Than 2m Context Window With Memory at Test Time
🧑🎓 GPT-4 tutoring in Nigeria achieved 2 years of learning in 6 weeks, outperforming 80% of other educational interventions
📡 InternLM3-8B-Instruct : New Apache 2.0 8B open LLM outperforms OpenAI's 4o-mini, Alibaba Qwen 2.5 and AIatMeta Llama 3.1
🏆 Kokoro-82M, blazing fast open-sourced TTS model with permissive license is dropped
🛠️ MatterGen, New Research from Microsoft generates new materials directly from prompts, accelerating discovery for batteries, magnets, and energy tech.
🗞️ Byte-Size Brief:
Luma Labs unveils Ray 2, generating realistic 1080p videos with physics.
François Chollet launches Ndea lab, pioneering efficient AGI without big data.
🧠 Google Released Breakthrough New Architecture Which Effectively Scale To Larger Than 2m Context Window With Memory at Test Time

🎯 The Brief
Google Research introduces Titans. A new architecture with attention and a meta in-context memory that learns how to memorize at test time. Titans are more effective than Transformers and modern linear RNNs, and can effectively scale to larger than 2M context window, with better performance than ultra-large models (e.g., GPT4, Llama3-80B). Titans achieve superior performance across language modeling, reasoning, and long-context needle-in-haystack tasks, handling context windows exceeding 2M tokens with greater accuracy and efficiency compared to leading models.
⚙️ The Details
→ Titans architecture combines short-term memory (attention), long-term memory (neural memory), and persistent memory (task knowledge) to mimic human-like memory processes. This architecture efficiently balances scalability and dependency modeling.
→ The neural memory module employs a surprise-based metric to optimize memory updates, using gradient magnitude to identify significant inputs and an adaptive forgetting mechanism to manage memory capacity.
→ Titans outperform Transformers and recurrent models in tasks like language modeling, commonsense reasoning, and DNA sequencing, offering better memory utilization and efficiency for long sequences.
→ Experimental results show Titans scaling beyond 2M-token contexts, achieving state-of-the-art results in recall-heavy tasks, outperforming GPT-4 and other baseline architectures by margins on metrics like accuracy and perplexity.
Differences with traditional Transformer Architecture
Traditional Transformers rely solely on attention, which scales poorly on extremely long inputs, and lack a dynamic memory that adapts at test time. So it struggle with long-term memory due to quadratic memory complexity.
Whereas, Titans adds a neural long-term memory that updates its parameters as new tokens arrive. This memory acts like a meta learner, continuously adjusting to fresh data via gradient-like updates and a forget mechanism.
The momentum-based update lets Titans preserve significant surprises in memory for extended periods. A learnable forget gate avoids saturating the memory with outdated information. In contrast, Transformers do not learn a separate memory structure for absorbing out-of-distribution tokens, and they keep all hidden states in a shorter context window.
How this new method can effectively scale to larger than 2M context window size with higher accuracy in needle-in-haystack tasks
The core idea is a long-term memory that updates its parameters on the fly. As tokens stream in, the memory incorporates surprising information into its internal parameters and discards irrelevant details via a learnable forget gate. This approach preserves critical “needle” tokens without overwhelming the memory, letting the model work through millions of tokens. Other baselines compress data or lack proper forgetting, causing them to lose the target token in vast streams of distractors. The deep neural memory here remains accurate under extreme context sizes and significantly improves recall in needle-in-haystack scenarios.
What tokens need to be memorized?

Titans combine attention with a deep memory that can update itself at test time. Whenever a token arrives, the memory calculates how surprising it is and decides how much to update itself. This lets Titans manage extremely long contexts (over 2 million tokens) without losing important details. They outperform existing Transformer and RNN-based models, even surpassing some ultra-large LLMs, because they continuously adapt to the data stream instead of relying on a fixed attention window or a static memory state.
🧑🎓 GPT-4 tutoring in Nigeria achieved 2 years of learning in 6 weeks, outperforming 80% of other educational interventions
🎯 The Brief
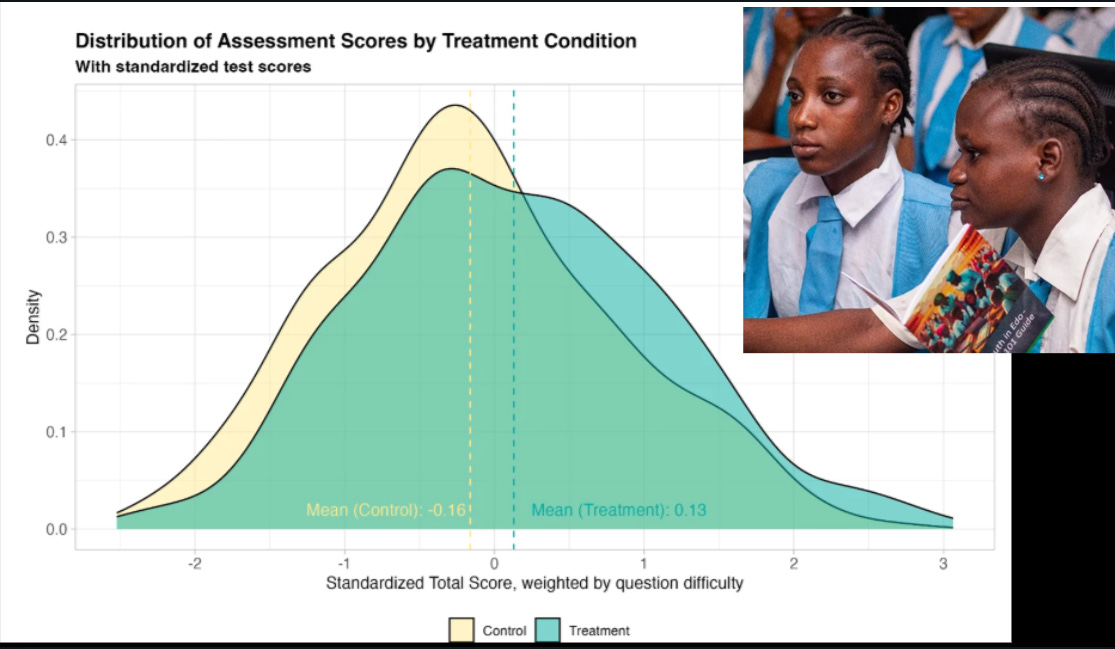
A randomized controlled trial in Nigeria used GPT-4 as a virtual tutor in a 6-week after-school program, achieving learning gains equivalent to 2 years of typical education. The program significantly outperformed 80% of global education interventions, especially benefiting girls who were initially lagging behind. This demonstrates the transformative potential of AI tutoring for equitable and scalable education.
⚙️ The Details
→ A pilot program in Edo, Nigeria, integrated GPT-4-based tutoring for English, AI knowledge, and digital skills. Students participating in the program outperformed peers across all subjects.
→ Girls saw greater benefits, narrowing the gender performance gap. End-of-year exam results also showed improvement, proving students could independently leverage AI for broader learning.
→ Learning gains measured 0.3 standard deviations, equivalent to 2 years of typical learning. Each additional day of attendance further boosted outcomes, with no diminishing returns.
→ The program surpassed 80% of global education interventions in effectiveness, demonstrating AI’s scalability and cost-effectiveness in education, even in developing regions.
→ Challenges like flooding, teacher strikes, and after-school work affected attendance, highlighting areas for improvement in future implementations. This should make the cost of knowledge to zero. We may not need traditional schools with human teachers anymore.
📡 InternLM3-8B-Instruct : New Apache 2.0 8B open LLM outperforms OpenAI's 4o-mini, Alibaba Qwen 2.5 and AIatMeta Llama 3.1
🎯 The Brief
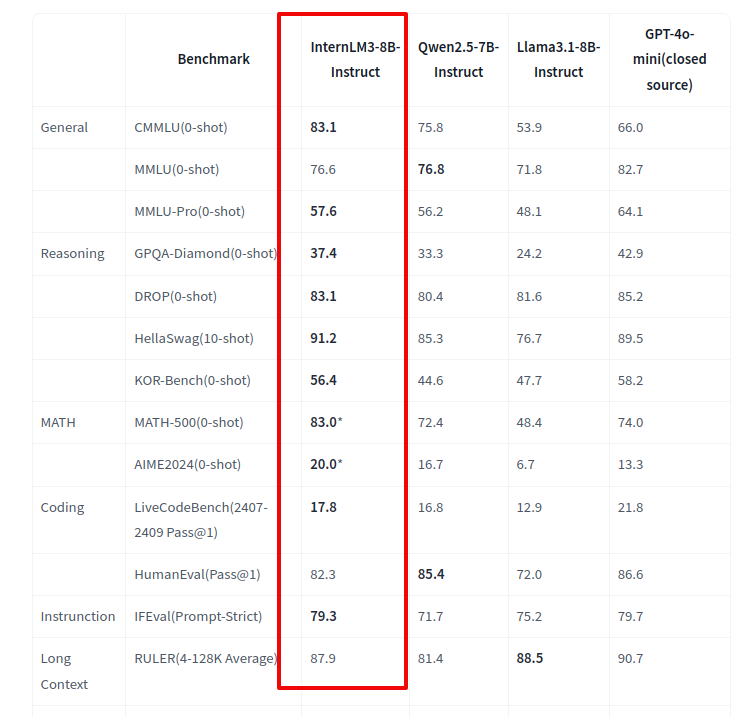
Shanghai AI Laboratory released InternLM3-8B-Instruct, an 8-billion parameter LLM, under the Apache License 2.0. It is designed for advanced reasoning and general-purpose usage, achieving state-of-the-art performance while reducing training costs by over 75% by using only 4 trillion tokens. Available in Huggingface.
⚙️ The Details
→ InternLM3-8B-Instruct is optimized for two modes: deep thinking for complex reasoning tasks and normal response for conversational interactions.
→ It outperformed models like Qwen2.5-7B and Llama3.1-8B in benchmarks, achieving notable results like 83.1 on CMMLU (0-shot) and 83.0 on MATH (0-shot).
→ The model supports long-context reasoning using Group Query Attention and can operate efficiently in 4-bit or 8-bit configurations.
→ It is aligned with human feedback using COOL RLHF, which addresses preference conflicts and reduces reward hacking.
→ The Apache License 2.0 allows unrestricted usage, enhancing accessibility for developers. No details on multilingual capabilities other than English and chinese. Checkout its Github.

🏆 Kokoro-82M, blazing fast open-sourced TTS model with permissive license is dropped
🎯 The Brief
Hexgrad released Kokoro TTS, a cutting-edge text-to-speech (TTS) model with only 82M parameters, built on StyleTTS 2 and trained using synthetic data from OpenAI and ElevenLabs. Despite its small size, Kokoro outperforms larger models like XTTS (467M) and MetaVoice (1.2B) in Elo rankings, making it efficient and ideal for homelab use with fast, accurate, and long-text generation.
⚙️ The Details
→ Kokoro TTS is based on StyleTTS 2 and uses ISTFTNet architecture for efficient decoding. It is designed as a lightweight TTS solution with 82M parameters, achieving strong Elo performance despite being significantly smaller than competing models.
→ The model runs efficiently, delivering 90x real-time speed on GPUs (e.g., 3090 TI) and 11x real-time on high-end CPUs, with memory usage under 3GB VRAM or 2GB RAM.
→ It was trained on less than 100 hours of permissively licensed and synthetic audio over 500 GPU hours, costing approximately $400.
→ The ONNX implementation enables wider hardware compatibility, although it runs slower than the PyTorch version. The model supports American and British English with 10 voicepacks released under Apache 2.0 license.
→ Kokoro demonstrates that small, well-optimized TTS models can challenge larger, more resource-intensive architectures, redefining efficiency in TTS scaling laws.
You can find a hosted demo at hf.co/spaces/hexgrad/Kokoro-TTS.
🛠️ MatterGen, New Research from Microsoft generates new materials directly from prompts, accelerating discovery for batteries, magnets, and energy tech.
🎯 The Brief
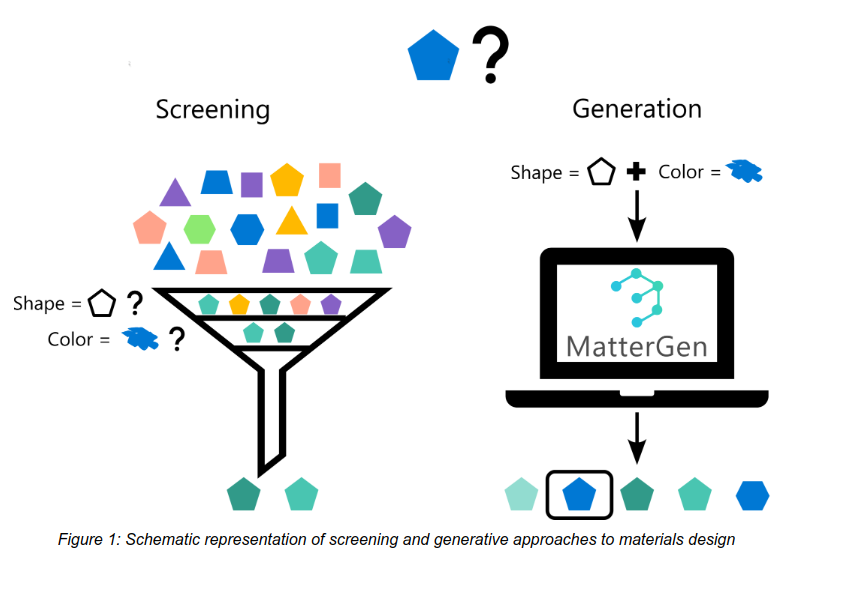
Microsoft Research introduced MatterGen, a generative AI tool designed to create novel materials directly from design prompts. This approach shifts from screening-based methods to property-guided material generation, enabling faster exploration of previously unknown materials. MatterGen demonstrates state-of-the-art performance, validated by experimental synthesis, and operates on a dataset of over 608,000 stable materials.
⚙️ The Details
→ MatterGen utilizes a diffusion model tailored to 3D material geometries, generating structures by adjusting atomic positions and periodic lattices. It is optimized for materials science, accommodating constraints like specific chemistry, mechanical properties, and crystal symmetries.
→ The model is trained on extensive datasets, including the Materials Project and Alexandria, allowing it to outperform traditional computational screening methods by exploring vast, uncharted material spaces.
→ A structure-matching algorithm addresses compositional disorder, ensuring generated materials are both novel and unique. This metric refines the evaluation process and establishes new standards in material discovery.
→ Experimental synthesis verified MatterGen’s predictions, including the creation of TaCr2O6, a compound meeting target bulk modulus conditions with less than 20% error from predictions.
→ MatterGen is released under the MIT license, including its source code and training data, encouraging community collaboration and expansion.
🗞️ Byte-Size Brief
Luma Labs drops new next-gen AI video model Ray 2. It turns text and images into stunningly realistic 1080p videos, up to 10 seconds long , with smooth, natural motion and physics capabilities, powered by 10x more compute. Ray2 demonstrates a sophisticated understanding of object interactions, from natural scenes like water physics to complex human movements.
François Chollet founds new AGI lab. Ndea lab combines deep learning with program synthesis to create AI with human-level learning adaptability. By rejecting large-scale data dependency, Ndea explores efficient alternatives for AGI, targeting breakthroughs in fields like drug discovery and unexplored scientific domains.