
🤖 Google released new Gemini model that runs directly on robots locally
Google’s Gemini powers robots offline, China’s Meteor-1 optical AI chip debuts, new device-to-cloud AI scale research, ElevenLabs’ 11ai voice automation, Microsoft’s Mu for Copilot+ PCs.

Read time: 9 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (24-Jun-2025):
🤖 Google released new Gemini model that can run on robots locally without internet connection
📢 China unveils first parallel optical computing chip, ‘Meteor-1’
📡 New research from China bridges devices and the cloud for seamless, scalable AI
🗣️ ElevenLabs launches 11ai: 5000+ voices automate tasks via MCP.
🪟 Microsoft launches Mu, an ultra-fast on-device AI model for Copilot+ PCs
🤖 Google released new Gemini model that can run on robots locally without internet connection

The model runs entirely on the robot’s own GPU, so motions stay smooth even when Wi-Fi cuts out.
It stays within a few points of the cloud version on unseen multi-step tasks and beats every other edge model tested.
Fine-tuning with only 50-100 tele-op demos teaches new chores like pouring or zipping in minutes.
The same weights jump from ALOHA arms to Franka and Apollo robots after a quick calibration.
An SDK ships with simulators, tuning scripts, and flash-to-hardware tools so developers iterate fast.
Most robots depend on remote servers for planning, so a weak connection quickly freezes their arms.
🔧 Local Brains Instead of Cloud: Gemini Robotics On-Device runs the full vision-language-action model directly on a two-arm robot computer, not in the data center. This local setup removes round-trip delays and stops packet loss from derailing control loops .
⚙️ Model Design: The team trimmed Gemini Robotics for on-device use by pruning large layers, sharing weights across modalities, and batching perception and action inference into one lightweight graph. The final network fits on typical embedded GPUs yet keeps the reasoning blocks that let it parse images, text, and proprioception together .
🎯 Generalization Performance: When tested on unseen objects and multi-step instructions, the on-device variant stays close to the cloud flagship and beats older edge models on every benchmark. Success rates stay high even when viewpoints, lighting, or starting poses change.

As you can see in the chart compares three models on nine unseen tasks. Gemini Robotics On-Device reaches almost the same success rates as the flagship cloud version while staying well ahead of the earlier on-device baseline.
Across visual and semantic generalization, the new on-device model holds steady close to the flagship, showing it can parse new scenes and instructions without heavy servers.
In action generalization, the flagship still leads, yet the on-device version remains robust and keeps a wide margin over the previous edge model, proving that local inference does not cripple complex motor planning.
Taken together, the figure shows that shifting the full system onto the robot sacrifices little accuracy but gains self-reliance, making reliable performance possible even with no network.
🛠️ Few-Shot Task Adaptation: Fine-tuning with only 50–100 human tele-operation demonstrations lets the robot learn new chores like zipping a lunchbox or pouring dressing. This quick adjustment proves the base model’s broad priors transfer with minimal data .
🤖 Switching to New Robots: Although trained on ALOHA arms, the same weights adapt to a Franka FR3 and even the Apollo humanoid. After alignment calibration, both machines follow natural-language commands and handle unseen parts with the same policy graphs .
⚡ Low Latency and Robustness: Running everything onboard cuts reaction time and removes the single point of failure that appears when Wi-Fi drops. This design suits factory lines, home helpers, and field robots where cables or 5G are unreliable .
🧰 SDK for Builders: A companion SDK exposes simulation in MuJoCo, fine-tuning scripts, and evaluation tools, so developers can replay tasks, collect their own demos, and push the tweaked weights back onto hardware in minutes
📢 China unveils first parallel optical computing chip, ‘Meteor-1’

The breakthrough is that Meteor-1 shifts compute from electrons to light, hitting 2,560 TOPS (tera-operations per second) at 50 GHz by running 100 tasks in parallel on one chip.
This is on par with Nvidia’s flagship GPUs and nearing the upcoming RTX 5090’s 3,352 TOPS. It sidesteps heat, power and quantum limits of silicon GPUs. Its integrated multi-wavelength comb replaces hundreds of lasers, slashing size and cost.
That makes it the first real-world optical accelerator matching top GPUs while dodging export bans and opening a new path for scaling AI compute. The light source uses a micro-cavity frequency comb over an 80nm spectrum, spanning 200 wavelengths.
This chip-scale multi-wavelength source cuts hundreds of lasers into one unit, trimming size, cost and power. The optical computing chip provides over 40nm transmission bandwidth for low-latency parallel processing. Its custom driver board supports more than 256 channels for precise optical signal modulation.
Meteor-1 not only sidesteps electronic bottlenecks like heat dissipation and quantum effects but also promises a cost-performance profile competitive with leading electronic chips, laying the groundwork for next-generation AI, 6G, and quantum-computing applications.
‘Optical computing … can meet AI’s ever-growing computational demands and unleash a wave of new applications’: Professor Xie Peng
📡 New research from China bridges devices and the cloud for seamless, scalable AI

New research led by Prof. Dr. Xuelong Li, the Director of the Institute of Artificial Intelligence (TeleAI) of China Telecom, unveils AI Flow framework to bridge devices and cloud for seamless, scalable intelligence.
Heavy AI models exceed everyday devices’ limits; latency creeps up when the cloud handles everything. 🤔
So this AI Flow paper proposes to link devices, edge servers, and cloud clusters into one inference pipeline. And uses feature compression to shrink visual data by up to 60%.
It spreads one model’s workload across devices, edge servers, and clouds, then lets many slimmed-down relatives of the same model talk to each other, keeping responses quick and accurate.
⚙️ The Core Concepts: AI Flow links three ideas.
The device-edge-cloud layout breaks down and distributes the inference process to the hierarchical hardware platform, so that it can be completed quickly.
Familial models give every tier a size-matched copy of the same network, all sharing compatible internal features. Strong network links then let these copies pool their partial answers so the final reply is better than any one copy could give.
What this paper proposes is a transformative paradigm at the intersection of AI and communication networks that can have big impact on embodied AI systems, wearable devices, and smart cities.
The system uses speculative decoding to start responses early, boosting speed by 1.25 times and cutting latency in half. It adapts model size on the fly using familial models to match device limits.
Familial models range from 2.38 to 6.3 billion parameters with low-rank factorization and exit branches. They keep accuracy steady on benchmarks like MMLU and GSM8K. Read the PAPER.
🗣️ ElevenLabs launches 11ai: 5000+ voices automate tasks via MCP.

ElevenLabs launched 11ai alpha, a voice-first assistant built on its Conversational AI. It taps Anthropic’s Model Context Protocol to connect to tools and execute workflows.
It offers out-of-the-box integrations with Perplexity, Linear, Slack and Notion for research, project tasks, team updates and planning via voice commands.
Developers can plug in custom MCP servers to link internal tools or specialized software. Each integration uses permission controls to ensure secure, scoped access.
The platform delivers ultra-low latency voice chat, multimodal voice and text sessions, integrated RAG, automatic language detection and enterprise-grade security.
Users pick from over 5,000 voices or create a custom clone. 11ai is available as a proof of concept in alpha starting today. During this experimental phase, they're offering free access to help us gather feedback and demonstrate the potential of voice-first AI assistants.
So what Anthropic’s Model Context Protocol connection with ElevenLabs means?
So the MCP turns your ElevenLabs voice assistant into an active helper. You speak a task, it runs the right tool, and then reports back—no manual clicks needed.
The Model Context Protocol (MCP) is a simple open standard that lets your ElevenLabs agents talk to external tools in real time over Server-Sent Events. As a user, you gain a voice assistant that can fetch data, run workflows and update your apps—all with natural speech .
To get started you first sign up at 11.ai and pick your voice. Then in the Conversational AI dashboard you click Integrations and select “Add Custom MCP Server.” This launches a form where you give your server a name, paste its URL (often with a secret key), and, if needed, add a token or extra HTTP headers.
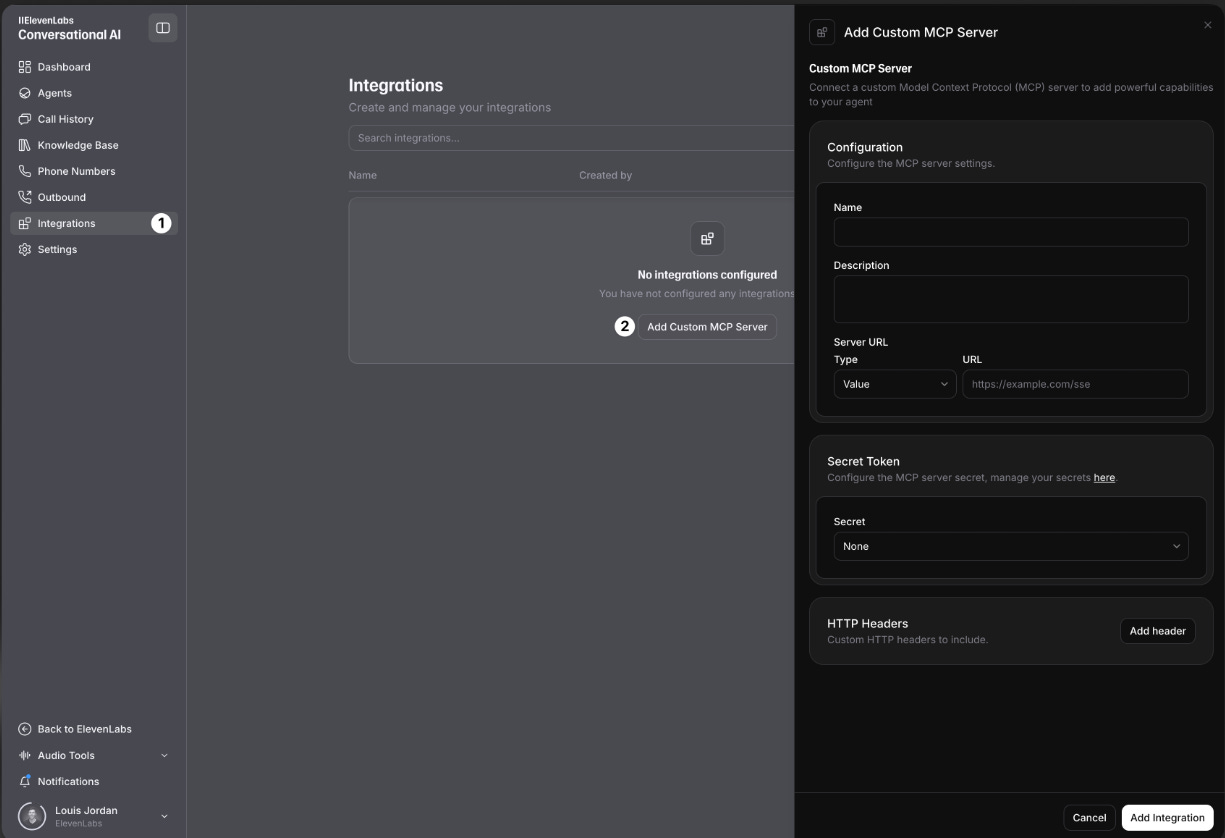
Once saved and tested, your agent will stream the server’s tool schema. You enable authentication in Security settings so only approved tools can run. You choose between Always Ask, Fine-Grained or No Approval to control which actions need your permission .
With MCP in place, your agent can tap into built-in integrations like Perplexity for research, Linear for tickets, Slack for messages, Notion for docs—and any custom tool you expose via MCP . When you issue a voice command, the model emits a JSON call to the right API, streams back the result, and continues the conversation—all in under a second .
🪟 Microsoft launches Mu, an ultra-fast on-device AI model for Copilot+ PCs
Microsoft has unveiled Mu, a compact AI language model designed to operate entirely on a PC’s Neural Processing Unit (NPU). Built for speed and privacy, Mu enables users to perform natural language-based tasks on Copilot+ PCs without relying on cloud connectivity. Its a very efficient 330M encoder–decoder language model optimized for small-scale deployment.
The optimization steps result in highly efficient inferences on edge devices, producing outputs at more than 200 tokens/second on a Surface Laptop 7.
It addresses scenarios that require inferring complex input-output, delivering high performance while running locally. Finding the right Windows toggle usually means hunting through menus; Mu will shrinks that hunt now.
Mu is fully offloaded onto the Neural Processing Unit (NPU) and responds at over 100 tokens per second, meeting the demanding UX requirements of the agent in Settings scenario.
They used Post-Training Quantization (PTQ) to convert the model weights and activations from floating point to integer representations – primarily 8-bit and 16-bit. PTQ allowed us to take a fully trained model and quantize it without requiring retraining, significantly accelerating our deployment timeline and optimizing for efficiently running on Copilot+ devices.
⚙️ The Core Concepts - Why its fast
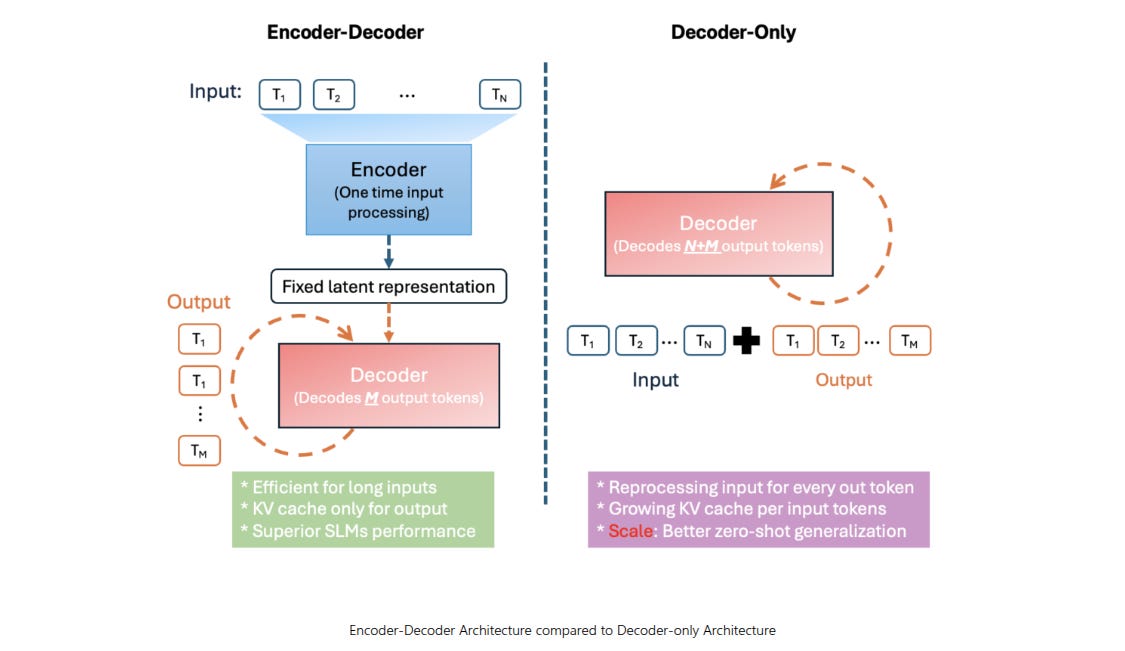
Mu follows an encoder–decoder Transformer design, so the encoder turns the user request into one fixed vector once, and the decoder then generates the answer from that vector.
A decoder-only model has to reprocess the full input plus every generated token each step, so it wastes compute and memory. By separating the stages, Mu needs far fewer operations, which matters on a Neural Processing Unit that has tight power limits.
That’s a wrap for today, see you all tomorrow.