
🗞️ Google releases Gemini 3 Deep Think, tops ARC-AGI 2 Benchmark With 84.6%
OpenBMB drops 9B long-context model, OpenAI scales Codex agents for prod code, and Microsoft says white-collar automation is 12–18 months away.
Read time: 10 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (12-Feb-2026):
🗞️ Google releases Gemini 3 Deep Think, tops ARC-AGI 2 Benchmark With 84.6%
🗞️ MiniCPM-SALA from OpenBMB - An open-source 9B model with a 1M-token context and an Apache 2.0 license released on HuggingFace, will run on a single consumer-class GPU
🗞️ New OpenAI blog explains how OpenAI uses Codex agents plus a tight repo-specific harness of tests, linters, observability, and UI automation to generate and ship large amounts of production code quickly without losing quality.
🗞️ In a new interview, Microsoft AI chief Mustafa Suleyman says most white-collar jobs will be automated in 12-18 months
🗞️ Google publishes papers on how Gemini Deep Think discovers in math
🗞️ Google releases Gemini 3 Deep Think, tops ARC-AGI 2 Benchmark With 84.6%
Google’s Gemini 3 Deep Think is an upgraded “reasoning mode” meant for messy science and engineering problems where the model has to build and check multi-step arguments instead of guessing from surface patterns.
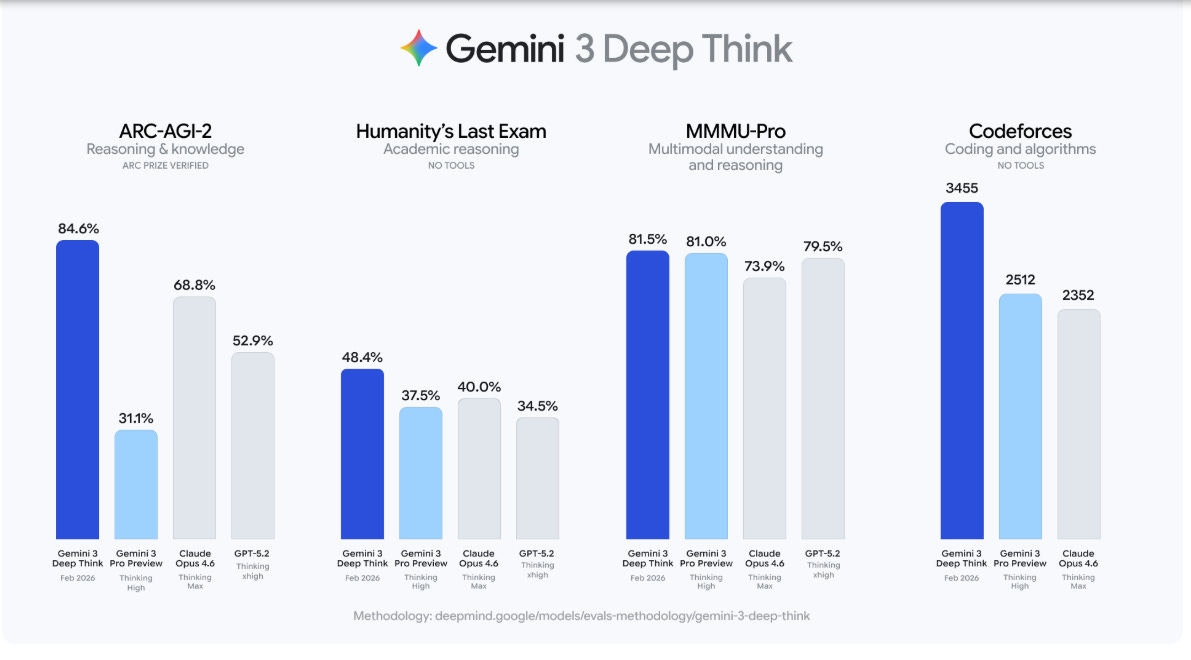
It posts 84.6% on ARC-AGI-2, a benchmark for abstract reasoning with novel tasks, and that score is verified by the ARC Prize Foundation.
On the same ARC-AGI-2 run, Gemini 3 Pro Preview scores 31.1%, Claude Opus 4.6 (Thinking Max) scores 68.8%, and GPT-5.2 (Thinking xhigh) scores 52.9%.
A big reason older “thinking” modes stall on these tests is that a single chain of thought can lock onto an early wrong idea and then spend tokens just justifying it.
However, Deep Think’s is using enhanced reasoning chains, parallel hypothesis exploration, and inference-time optimizations, which is a fancy way of saying it tries multiple candidate solutions and spends extra compute picking and refining the most consistent one.
That shows up beyond ARC, with 48.4% on Humanity’s Last Exam without tools, which is designed to probe hard, cross-discipline academic knowledge, versus 37.5% for Gemini 3 Pro Preview, 40.0% for Claude Opus 4.6, and 34.5% for GPT-5.2.
On Codeforces, a competitive programming platform where Elo measures relative skill on time-pressured algorithm problems, it reaches 3455 without tools, ahead of 2512 for Gemini 3 Pro Preview and 2352 for Claude Opus 4.6.
On MMMMU-Pro, a multimodal benchmark that checks reasoning over text and images, it scores 81.5%, narrowly above Gemini 3 Pro Preview at 81.0% and GPT-5.2 at 79.5%.
Currently the access is for Google AI Ultra in the Gemini app and a limited early-access Gemini API path for researchers and enterprises, which suggests the extra inference compute is a key tradeoff.
Scientists, engineers and enterprises can also now express interest in their early access program to test Deep Think via the Gemini API.
Gemini 3 Deep Think Semi Private Eval
ARC-AGI-1: 96.0%, $7.17/task
ARC-AGI-2: 84.6% $13.62/task

🗞️ MiniCPM-SALA from OpenBMB - An open-source 9B model with a 1M-token context and an Apache 2.0 license released on HuggingFace, will run on a single consumer-class GPU

This model breaks the “Compute Wall” and the “Memory Wall,” achieving 3.5× faster inference and significantly lower KV-cache overhead compared to dense baselines. GitHub Repo | Technical Report
This is no longer an “either-or” choice between performance and efficiency.
How are they achieving it?
Full Attention mechanism’s computational complexity grows quadratically with length, making edge-side long-text inference “slow and memory-intensive.”
Solution: MiniCPM-SALA adopts a golden ratio of 75% Linear Attention + 25% Sparse Attention.
MiniCPM-SALA (9B) is OpenBMB’s long-context model aimed at running 1M to 2M tokens on a single GPU without the memory spikes and OOM failures common with dense full attention. The main idea is a sparse plus linear hybrid that keeps long-range recall accurate while keeping cost manageable as context grows.
Architecturally, about 25% of layers use InfLLM-V2 style sparse attention for high-fidelity long-range retrieval, while about 75% use Lightning linear attention, so compute scales close to linearly with sequence length. Instead of a uniform interleave, the sparse layers are placed via a 1:3 layer-selection pattern.
For positional handling and stability, SALA uses hybrid positional encoding (HyPE): RoPE stays in the linear layers but is removed in sparse layers to avoid long-range decay, and it adds QK-normalization plus output gating to improve stability and reduce attention-sink behavior.
Training is done by converting a pretrained Transformer, not training from scratch. It starts from a MiniCPM-4.0 intermediate checkpoint trained on 7T tokens, then applies HALO conversion, keeping the 1st and last layers unconverted and initially training only the converted linear layers.
Conversion plus post-training totals about 2T tokens, framed as about a 75% cost reduction versus an 8T scratch run, with context ramping from 512 to 4K, then to 32K, 160K, and 520K, followed by SFT at 64K and 140K.
Reported results keep standard performance strong (76.53 average, HumanEval 95.12, AIME24 83.75, AIME25 78.33)
While improving long-context behavior (RULER 92.65 at 64K, 89.37 at 128K). It also reports single-GPU 1M-token inference where Qwen3-8B OOMs, 256K TTFT, improving from 180.8s to 51.6s, and RULER holding at 86.3 at 1M and 81.6 at 2M without YaRN.
Go to HuggingFace or GitHub to test the model capabilities yourself.
They also launched the SOAR Sparse Operator Acceleration Competition, join and share the $100,000 prize pool.
🗞️ New OpenAI blog explains how OpenAI uses Codex agents plus a tight repo-specific harness of tests, linters, observability, and UI automation to generate and ship large amounts of production code quickly without losing quality.

A single Codex agent session can keep working on the same assignment for as long as 6 hours, so the real way to go faster is not writing bigger prompts, it is building a “harness” around the agent that constantly checks its work, gives it concrete feedback, and lets it iterate automatically. That harness is things like running tests and linters, spinning up an isolated dev environment, driving the UI to verify behavior, and feeding the agent log.
As agent throughput rose, human quality assurance (QA) became the bottleneck because Codex needed more structure to validate work. Starting from an empty repo, Codex command line interface (CLI) with GPT-5 generated the scaffold, including AGENTS .md.
They replaced a giant instruction file with a roughly 100-line AGENTS .md map into a docs/ knowledge base that continuous integration (CI) checks. They made the app boot per git worktree and used Chrome DevTools Protocol so Codex can drive the user interface (UI) and rerun validation.
Exposed per-worktree logs, metrics, and traces, where a trace is timed request spans, so Codex can query LogQL for logs, PromQL for metrics, and keep spans under 2s. To prevent drift, layered domain boundaries and taste rules are enforced by custom linters and structural tests. When throughput outpaced attention, they relaxed merge gates, fixed flakes with follow-up runs, and replaced 20% weekly cleanup with recurring agent refactors.
🗞️ In a new interview, Microsoft AI chief Mustafa Suleyman says most white-collar jobs will be automated in 12-18 months

Mustafa Suleyman, the Microsoft AI chief, said in an interview with the Financial Times that he predicts most, if not every, task in white-collar fields will be automated by AI within the next year or year and a half.
“I think that we’re going to have a human-level performance on most, if not all, professional tasks,” Suleyman said in the interview that was published Wednesday. “So white-collar work, where you’re sitting down at a computer, either being a lawyer or an accountant or a project manager or a marketing person — most of those tasks will be fully automated by an AI within the next 12 to 18 months.”
Other Takeaways from the interview.
He says markets are nervous about the spend, but compute-to-capability gains justify it.
He predicts no single AI winner, and says Microsoft already reached about 800 million monthly AI users.
He wants Microsoft AI to be self-sufficient by training its own frontier foundation models on huge compute and data.
He calls victory practical AGI: agent teams that automate most office tasks, while humans focus on judgment, safety, and care like medicine.
Warns superintelligence must stay controllable and subordinate, and rejects the idea that models deserve human-style rights.
Mustafa Suleyman, CEO of Microsoft AI, takes a swipe at Anthropic’s internal ‘AI consciousness’ talk—says it’s baseless and could make shutdown decisions harder.
Says labs flirting with AI personhood, if you convince yourself the model can suffer, then you’ll start “protecting” it, that could end up being unwilling to shut systems down, even when they’re clearly risky.
“There is a growing belief in some labs, particularly inside Anthropic, that these models are conscious. If it’s a conscious being that’s aware of itself and can suffer, then it deserves moral protection.
This is a serious area of academic research, not just outside, but inside some labs. I think it’s very concerning and totally without merit or basis. If we go down that path, it becomes a slippery slope where we won’t be prepared to turn these systems off.”
🗞️ Google publishes papers on how Gemini Deep Think discovers in math
Google says Gemini Deep Think is now being used for open ended research problems, not just contest style math with fixed answers.
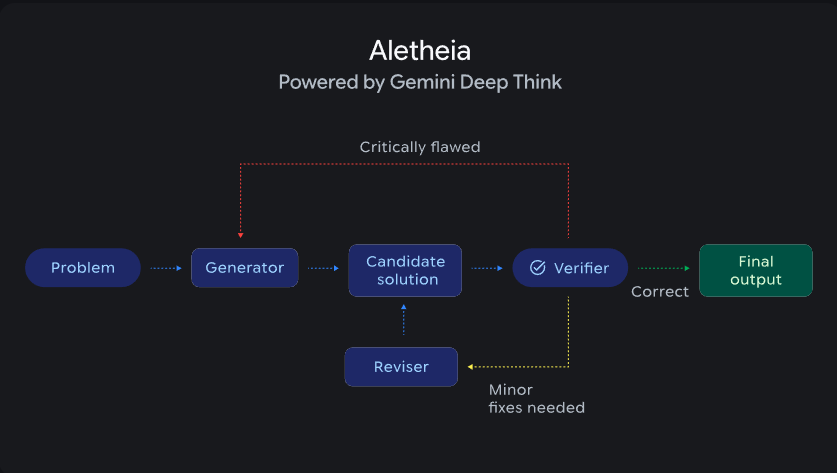
The main claim is that an agent called Aletheia can iteratively draft, check, and repair proofs, and it reaches about 90% on IMO-ProofBench Advanced.
Earlier LLM math systems often got the final answer but still had silent gaps in the proof, or they invented citations when they tried to lean on the literature.
Aletheia wraps Deep Think in a generator verifier reviser loop, where a proof draft is checked in natural language, patched if it is close, or fully restarted if it is broken.
The system also uses web browsing so it can ground claims in published work and avoid spurious references during long derivations.
Since achieving IMO Gold-medal standard in July 2025, Gemini Deep Think has progressed rapidly, scoring up to 90% on the IMO-ProofBench Advanced test as inference-time compute scales.
Google reports inference time scaling still helps on Olympiad level problems, and it partially transfers to harder PhD level exercises in an internal FutureMath Basic set.
They also describe research outcomes like working through hundreds of open Erdős style problems and contributing to theory work across optimization, economics, and physics.
This looks most useful as a verifier and counterexample hunter that can save experts time, as long as the human review bar stays strict.
That’s a wrap for today, see you all tomorrow.