
👨🔧 Google Releases MLE-STAR: A 'Self-improving’ Machine Learning Engineer
Google launches MLE-STAR for AI task automation, OpenAI restores GPT-4o, gpt-oss tutorial drops, and Cloudflare clashes with Perplexity over web scraping.

Read time: 10 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (9-Aug-2025):
👨🔧 Google AI Releases MLE-STAR: A Machine Learning Engineering Agent Capable of Automating Various AI Tasks.
🧩 OpenAI is restoring GPT-4o as a switchable model in ChatGPT after 1 day of GPT-5-only default
📡 Tutorial: Running gpt-oss, the new open-source model family from OpenAI with Huggingface transformer lib
⚔️ Cloudflare vs Perplexity: The Battle Over AI Web Scraping Heats Up
👨🔧 Google AI Releases MLE-STAR: A Machine Learning Engineering Agent Capable of Automating Various AI Tasks.

MLE‑STAR nails 63% medal wins on Kaggle’s MLE‑Bench‑Lite by mixing web‑sourced ideas with laser‑focused code tweaks. It tackles the grind of trial‑and‑error ML engineering, where today’s agents cling to generic libraries and reshuffle whole scripts instead of fixing the piece that actually hurts.
Its key abilities
Pulls in task-focused models from web search, then keeps editing its key code section until results stop improving, all without human input.
Merges the best runs into a single solution, then uses built-in checks to catch bugs, data leaks, and licensing issues.
Tested on 22 Kaggle contests, with each tried 3 times.
Using Gemini-2.5-Pro, it won medals in almost two-thirds of runs, tripling the earlier benchmark; even the smaller Gemini-Flash version managed to double it.
🛠️ The pain points before MLE‑STAR
Building a solid model usually means scrolling through old Kaggle notebooks, guessing which feature trick matters, then rewriting everything when a run flops. Current agents copy that pattern, so they stay stuck on scikit‑learn defaults and never probe a single block deeply. That leads to shallow pipelines and slow progress.
🔍 Web search as a starting gun
MLE‑STAR begins by pinging the web for code and papers that match the task. The agent turns each hit into a short “model card,” grabs example code, and stitches a first script. Pulling fresh snippets keeps it off the beaten path, so image jobs might start with EfficientNet or ViT instead of 2015’s ResNet.
The big picture of MLE-STAR

After the first score comes in, the agent runs an ablation test: flip off each pipeline part and watch the metric drop. The part that hurts the most becomes the target for the next round.
An LLM writes 3‑5 tweak plans for that exact code block, the agent tests them, keeps the best, then loops. This tight focus avoids the “rewrite everything” chaos and digs until returns flatten.
🤝 Smarter ensembles
Instead of a lazy average, MLE‑STAR asks the LLM to draft an ensemble recipe, tests it, then rewrites that recipe if the lift is small. Over a few cycles, separate scripts converge into one blended model that usually beats every single candidate. The diagram on page 4 shows this inner loop of propose‑evaluate‑refine.

🧩 OpenAI is restoring GPT-4o as a switchable model in ChatGPT after 1 day of GPT-5-only default

ChatGPT is bringing back GPT 4o as an option because many users preferred 4o’s style. Plus users can pick 4o again, while GPT-5 stays the default.
To activate it: Log in via ChatGPT web, go to Settings, toggle Show legacy model. Once it appears in your model list, you’ll be able to select GPT-4o again, and it should also appear in the iOS app.
OpenAI removed the model picker and auto-routed prompts to GPT-5 sub-flavors, which cut direct control many depended on.
But they figured, power users split work by model, 4o for creative and multimodal work, which means text, audio, and images together, o3 for strict reasoning, o3 Pro for research, and 4.5 for long writing. Some chained 8 models, so losing the switch broke habits and, for support use, the tone change hurt.
GPT-5 promises stronger writing and coding, yet early reports said replies felt slower, shorter, and less accurate. OpenAI says it is tuning GPT-5, adding clearer model labels, and raising Plus limits. Restoring GPT-4o gives paid users control now while GPT-5 improves, and usage will guide how long 4o stays.
Yesterday OpenAI and the whole world really realized how strong a bonding could be between a specific AI model and humans. Many users had co-created a voice and rhythm with it over months, so removing it felt like losing a partner
The SimpleBench score is out for GPT-5 and its at 5th pace with 56.7%
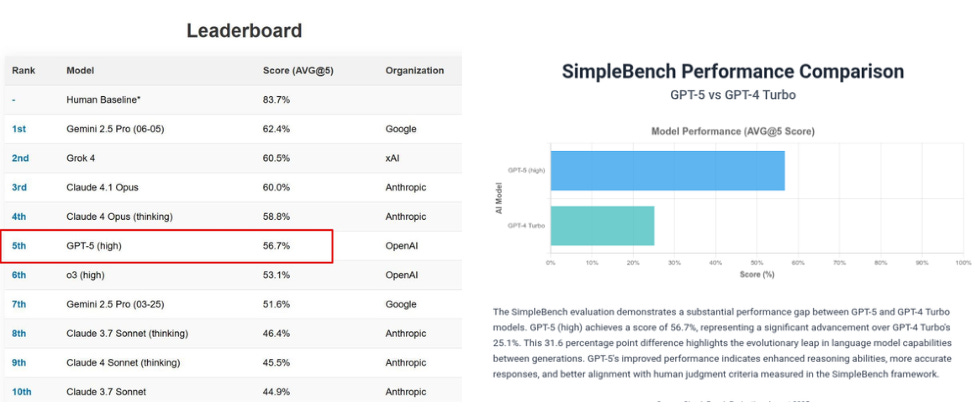
Its actually a little strange as to why GPT-5 is behind on SimpleBench with 56.7% , because otherwise GPT 5 is coming at the top of pretty much every other benchmark.
SimpleBench is a 213‑question, 6‑option multiple‑choice test of spatio‑temporal reasoning, social intelligence, and linguistic adversarial robustness.
A non‑specialist human baseline is 83.7%, well above all models. Most questions are private to reduce contamination. This benchmark is intentionally aimed at gaps where humans still beat LLMs.
A possible reason for GPT-5’s underperformance is that, earlier, the SimpleBench team explicitly argued that models optimized for industrial coding or math can underperform on everyday-reasoning questions—a pattern they had already observed with GPT-4o, which also lagged in this area.
📡 Tutorial: Running gpt-oss, the new open-source model family from OpenAI with Huggingface transformer lib

OpenAI’s gpt-oss comprises two models: a big one with 117B parameters (gpt-oss-120b), and a smaller one with 21B parameters (gpt-oss-20b). Both are mixture-of-experts (MoEs) and use a 4-bit quantization scheme (MXFP4), enabling fast inference (thanks to fewer active parameters, see details below) while keeping resource usage low.
The large model fits on a single 80GB H100 GPU, while the small one runs within 16GB of memory and is perfect for consumer hardware and on-device applications.
Overview of Capabilities and Architecture
21B and 117B total parameters, with 3.6B and 5.1B active parameters, respectively.
4-bit quantization scheme using mxfp4 format. Only applied on the MoE weights. As stated, the 120B fits in a single 80 GB GPU and the 20B fits in a single 16GB GPU.
Reasoning, text-only models; with chain-of-thought and adjustable reasoning effort levels.
Instruction following and tool use support.
Inference implementations using transformers, vLLM, llama.cpp, and ollama.
Responses API is recommended for inference.
License: Apache 2.0, with a small complementary use policy.
GPT-OSS with Transformers is super simple.
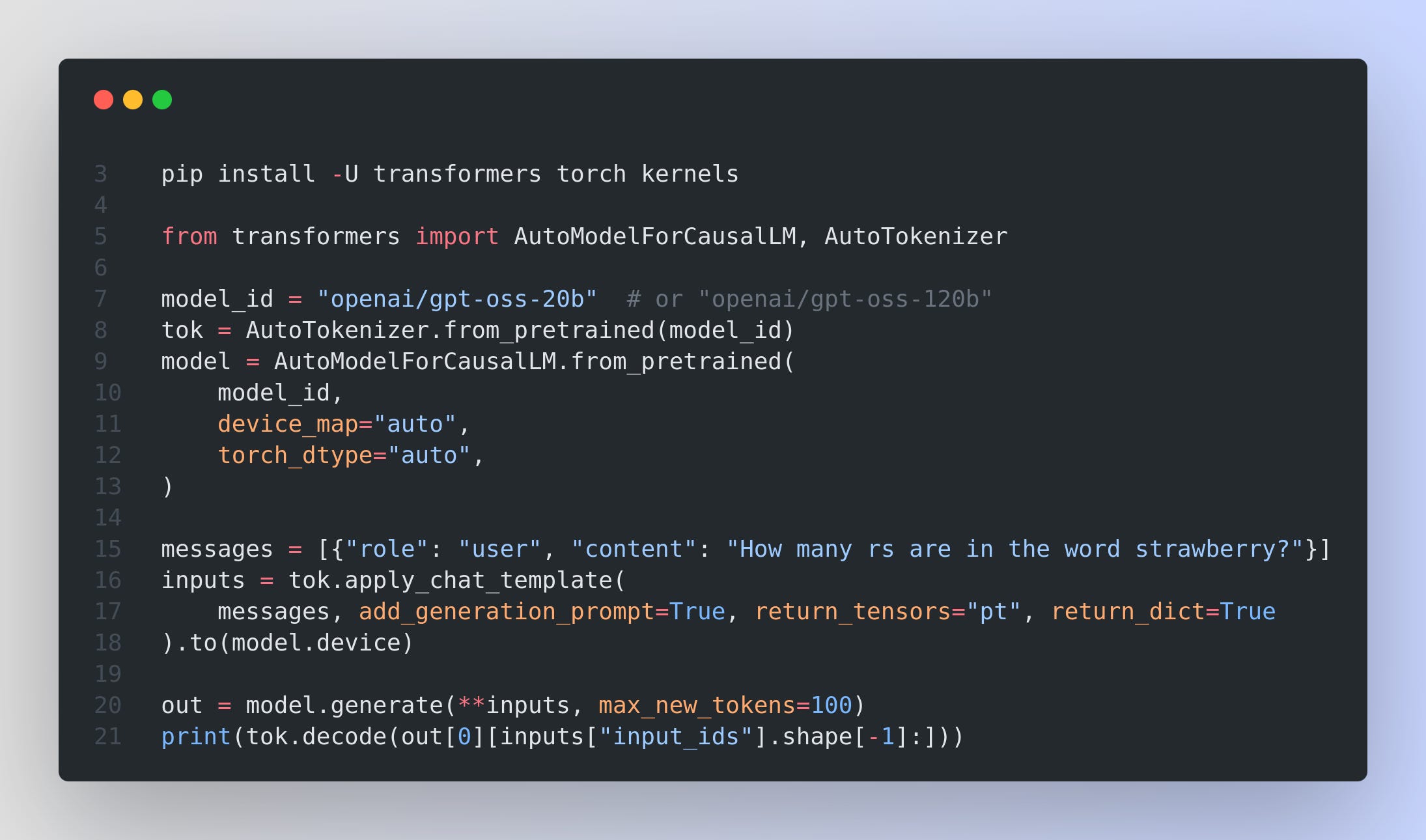
When you run `pip install -U transformers kernels torch` the “kernels” package contains the Flash Attention 3 implementation that supports “attention sinks,” which GPT-OSS uses.
If you have H100 or H200, enable Flash Attention 3 with attention sinks by adding one argument when loading the model, attn_implementation="kernels-community/vllm-flash-attn3". If your GPU cannot use MXFP4, enable MegaBlocks MoE kernels with use_kernels=True, this switches MoE layers to a Triton path that runs in bfloat16, so memory rises compared to MXFP4.
Using apply_chat_template in the above code, is the key step that keeps prompts compatible with GPT-OSS.
When your GPU cannot use MXFP4
If your GPU cannot use MXFP4, enable MegaBlocks MoE kernels. This switches MoE layers to a Triton implementation and runs them in bfloat16, which increases memory use but can speed up execution on non-Hopper hardware.
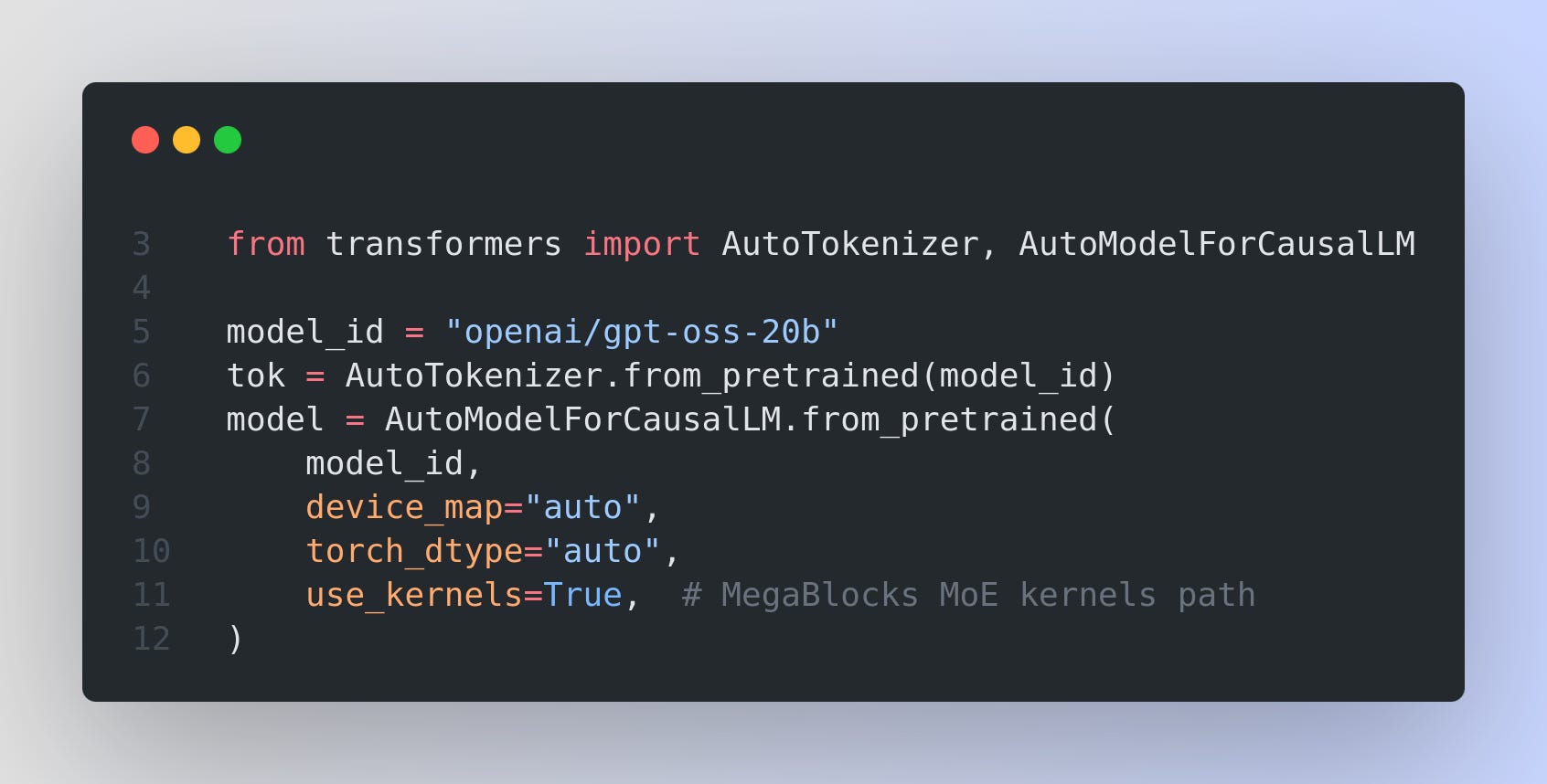
MegaBlocks optimized MoE kernels require the model to run on bfloat16, so memory consumption will be higher than running on mxfp4. So the recommendation is that you use mxfp4 if you can, otherwise opt in to MegaBlocks via use_kernels=True.
Reasoning controls and safe output handling
GPT-OSS supports “reasoning effort” controls. You can set this by writing a short instruction in the system message, for example Reasoning: high.
High effort increases depth at higher latency. The model cards also note that full chain-of-thought is available for debugging, but you should not surface it to end users. Keep outputs to the final answer channel when you build products.
Why these models fit on modest hardware
GPT-OSS uses a token-choice MoE with SwiGLU. Only a small set of experts runs per token, which cuts the active parameter count. The attention stack uses RoPE with 128K context, alternates full attention with a 128-token sliding window, and adds a learned attention sink term per head. The MoE weights are stored in 4-bit MXFP4, which reduces memory further while keeping accuracy. This combination is why 120B can sit on 80GB and 20B on 16GB.
⚔️ Cloudflare vs Perplexity: The Battle Over AI Web Scraping Heats Up

Cloudflare accuses Perplexity of ignoring robots.txt and scraping blocked sites. Perplexity says it is a user-driven agent that fetches pages per query, not a bulk crawler.
The fight is about who sets the rules for web access. robots.txt is the long standing do not crawl sign. Search crawlers usually respect it because they prebuild giant indexes.
Cloudflare says Perplexity kept pulling content from test sites that were marked off limits, then used rotating identities. That is why Cloudflare removed Perplexity from its verified list and started blocking undeclared crawlers.
Perplexity rejects the label. It describes its system as a user-driven agent, meaning it fetches pages only when a user asks. The claim is that it is not building an index, it is doing on demand retrieval. It also says Cloudflare mixed up traffic from another cloud browser and wrongly pinned 3 to 6M daily requests on Perplexity.
This matters because control over the pipe can shape who gets information. If infrastructure vendors decide which bots or agents are acceptable, access could tilt toward whitelisted players. Perplexity warns this can harden into a two tier internet, where the gate, not the user, decides what gets fetched.
Real time agents versus crawl era rules. The outcome sets how AI tools touch the public web.
🗞️ Byte-Size Briefs
Anthropic is now making $4.5B in annualized revenue, becoming the fastest growing software company ever. They’ve just passed OpenAI in LLM API pricing to take the top spot.

Midjourney added a new HD video mode to Pro and Mega subscribers. It's ~3.2x more expensive with ~4x more pixels than their default SD video outputs. This is for professionals that need the absolute highest quality footage possible out of Midjourney and we hope you enjoy it.
OpenAI is talking with investors about a secondary share sale and possible valuation at $500B, up from $300B just 4 months ago. The deal would let staff cash out while the company gears up for GPT-5 and hardware moves.
This is a secondary sale, so cash goes to staff, not the treasury. Employees will be happy with this secondary sale, as Meta waves 9-figure pay to lure researchers. Turning options into liquid cash helps keep core architects focused on ChatGPT instead of rewriting resumes.

That’s a wrap for today, see you all tomorrow.