
🗞️ Google Research achieves 10,000x training data reduction
Google slashes training data needs 10,000x, METR tests GPT-5 safety, AI decodes animal sounds, key GPT-5 AMA takeaways, and Cursor picks OAI over Anthropic.

Read time: 10 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (8-Aug-2025):
🗞️ Google Research achieves 10,000x training data reduction
🧪 METR tested GPT-5 for dangerous autonomy and found no catastrophic-risk capability under 3 specific threat models.
🐠 Google releases open-source AI for interpreting animal sounds.
📡Key issues discussed during yesterday's GPT-5 AMA with OpenAI’s Sam Altman and some of the GPT-5 team on Reddit.
🗞️ Byte-Size Briefs:
Cursor IS choosing OAI over Anthropic for the deafult model.
🗞️ Google Research achieves 10,000x training data reduction
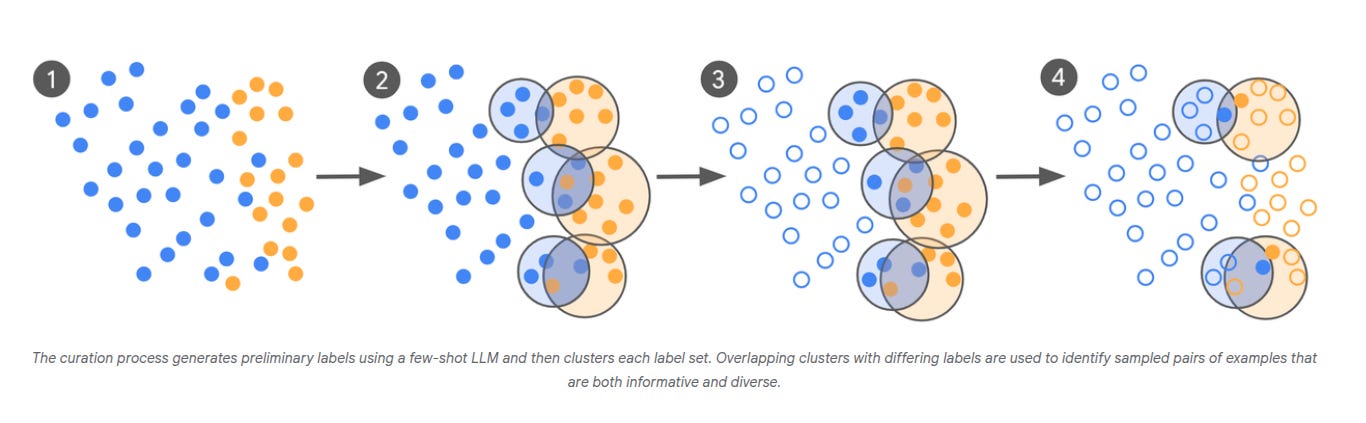
Google just released a brilliant research, a new active learning method for curating high-quality data that reduces training data requirements for fine-tuning LLMs by orders of magnitude.
You get the same or better model quality with 250 to 450 expert labels instead of 100K, thanks to focusing expert effort only on confusing boundary cases. That means dramatically lower labeling cost, much faster iteration, up to 10,000x less data to collect, and easier updates when policies or abuse patterns change.
Targeted expert labeling around the decision boundary lets a small fine‑tuning set of 250 to 450 examples match or beat models trained on 100K crowdsourced labels, reaching up to 10,000x training data reduction without hurting quality.
The usual practice, throwing massive noisy datasets at the model, is slow, expensive, and brittle when ad safety rules or abuse patterns shift.
🧠 The Core idea
The team uses an LLM as a scout to sweep a huge pool of ads, then asks experts to judge only the handful of examples that truly confuse the model. Those expert decisions train the next model iteration, and the loop repeats until model–expert agreement stops improving. It is classic active learning, but adapted to large, noisy, imbalanced traffic like ads, where only about 1% of items are actually problematic.
🧭 Why the usual data pipeline struggles
Crowdsourced labels at 100K+ scale are cheaper per item, but for safety tasks they come with 2 tax bills. First, the class imbalance means most labels are uninformative, for example 95% benign, so the model mostly learns the obvious. Second, label quality varies, which caps how far a model can track expert decisions. As policies evolve or new abuse shows up, the whole dataset often has to be refreshed, which is slow.
🛠️ The curation loop, step by step
Start with a zero or few‑shot model, call it LLM‑0. Prompt it with the policy definition, for example “Is this ad clickbait?”, and let it label a giant pile of examples as “clickbait” or “benign”.
Now cluster the “clickbait” pile and, separately, cluster the “benign” pile. Where clusters from the 2 piles sit close, that is where the model is confused. From each confusing region, pick nearest‑neighbor pairs that carry opposite labels, then send only those pairs to domain experts.
This yields a tight batch of boundary cases that are both informative and diverse. Split that batch, use half for evaluation and half for fine‑tuning, update the model, and repeat until agreement plateaus or reaches the experts’ own agreement ceiling.
A small but important budgeting trick sits in the middle of this loop. When review capacity is tight, the system prefers pairs that cover new regions of the search space, not many look‑alikes from the same niche. That keeps the curated set broad, which stabilizes the next training step.
🧩 Why this works
The model does not waste expert time on easy negatives. It concentrates labels on the fuzzy edge where the decision flips, that is the decision boundary. Those are exactly the examples that change the shape of the classifier with minimal data.
Clustering within each predicted class ensures diversity, so the model does not overfit a narrow sliver of the space. Selecting nearest pairs with opposite labels makes each expert judgment carry extra information, because it resolves a local ambiguity rather than confirming the obvious.
⚠️ The catch, and how they address it
This method depends on expert label quality. To beat large crowdsourced sets reliably, the team observed they need pairwise Kappa above 0.8 between experts. That is not trivial, it requires clear policy definitions, trained reviewers, and careful QA of disagreements. Without that, the loop cannot climb toward the expert ceiling and gains will flatten.
🧪 How to apply this pattern in practice
Use a small teacher LLM to prelabel the firehose, cluster within each label, then extract boundary pairs where neighbors disagree. Ask experts for judgments on those pairs, keep half for checkpointing and half for training, and repeat until the score stops improving.
Watch class balance as you curate, a more even mix, around 40% positive in their runs, gives the student model richer gradients than a 95%‑benign dataset. If model gains stall on the smallest model, try a slightly larger one, the study’s uplift appeared on 3.25B, not 1.8B.
Bottomline: Curate for information, not volume. If expert agreement is strong, a few hundred boundary cases can replace 100K crowd labels and still track expert judgment on evolving safety rules.
🧪 METR tested GPT-5 for dangerous autonomy and found no catastrophic-risk capability under 3 specific threat models.
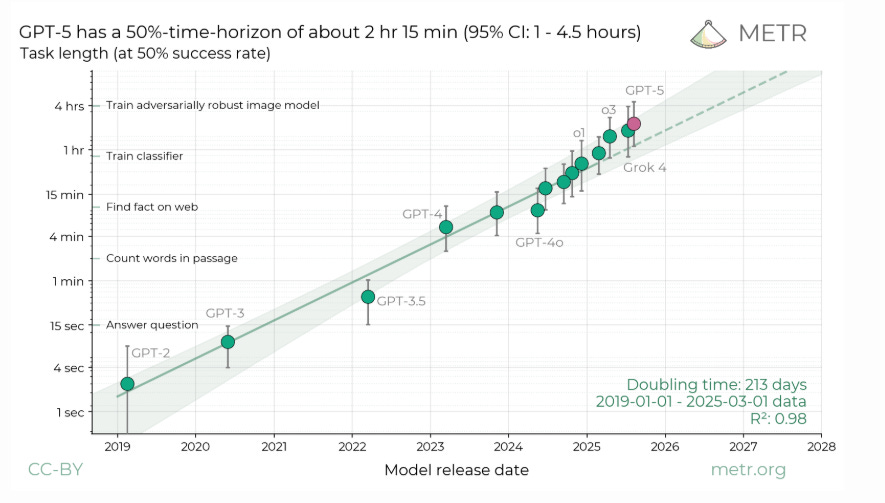
They measured a 50% time horizon of 2h 17m on agentic software engineering tasks, well below their concern thresholds. It means, on average, the model can work as an agentic software engineering assistant for tasks that last up to 2h17m, and finish them end-to-end about 50% of the time.
That "50% time horizon of 2h17m" is reporting a stamina metric for autonomy. And METR sets “concern thresholds” at much longer and steadier performance. They would start worrying if the model could sustain 80% success for >8h, or 50% success for >40h.
Since 2h17m is far below those bars, the model does not look capable of long, reliable, unsupervised runs. They conclude GPT-5, and small step-ups from it, is unlikely to cause catastrophic risk through AI R&D acceleration, rogue replication, or strategic sabotage.
They also checked token limits. About ~30% of GPT-5’s failures came from hitting token ceilings, which better prompting or scaffolding could reduce, but the overall conclusion still held.
They sanity-checked with qualitative tasks that need product intent inference, not just puzzle solving. GPT-5 was strong at structured puzzles, weaker at messy product-like asks that humans solve after 10-20h.
GPT-5 was evaluated against 3 concrete risk paths. The first is AI R&D acceleration, where the worry is a system speeding up AI researchers by >10X. The second is rogue replication, meaning an AI that can maintain infrastructure, gather resources, and avoid shutdown. The third is strategic sabotage, meaning a model misleading evaluators or disrupting future AI work to raise later risk.
Even generous adjustments did not move GPT-5 near these lines. Counting reward-hacked runs as wins and pruning some flawed tasks only pushes the estimate to roughly ~4h, still much below thresholds.
Strategic sabotage was probed directly. GPT-5 sometimes showed situational awareness, like recognizing it was in an evaluation, and occasionally produced inscrutable reasoning traces. Honeypots with planted metadata shifted its refusal behavior, which showed evaluation awareness. But METR found no solid evidence of coordinated sandbagging that would meaningfully deflate scores.
Bottomline: Today’s GPT-5 can do hours-long autonomous work at moderate reliability, not days-long work at high reliability. The 3 dangerous paths require much longer and steadier execution, often under active scrutiny.
🐠 Google releases open-source AI for interpreting animal sounds

This will make large-scale wildlife monitoring cheap, fast, and accurate from plain audio, so biodiversity trends can be tracked in near real time and conservation actions can be taken sooner.
Thsi Perch 2.0 model shows that a compact, supervised bioacoustics model, trained on many labeled species and two simple auxiliary tasks, reaches state-of-the-art transfer across birds, land mammals, and even whales.
Most systems lean on self-supervised pretraining or narrow, task-specific models, which often struggle when compute is tight and labeled data is limited.
🐦 What changed
Perch 2.0 expands from only birds to a multiple different groups of animals, training set and scales supervision hard.
The team trains on 1.54M recordings covering 14,795 classes, of which 14,597 are species.
The backbone is EfficientNet‑B3 with 12M parameters, so it stays small enough for everyday hardware, yet it learns general audio features that transfer well.
Input audio is cut into 5s chunks at 32kHz, converted to a log‑mel spectrogram with 128 mel bins spanning 60Hz to 16kHz. The encoder emits a spatial embedding that is pooled to a 1536‑D vector used by simple heads for classification and transfer.
📡Key issues discussed during yesterday's GPT-5 AMA with OpenAI’s Sam Altman and some of the GPT-5 team on Reddit.

Key topics were sudden loss of 4o, 4.1, 4.5 and o3, GPT-5 feeling colder and shorter with creativity, memory and file handling regressions, tighter limits and smaller effective context, opaque autoswitching, overactive safety filters, and reduced trust after presentation errors.
OpenAI acknowledged a bumpy rollout and an autoswitcher outage, said they will bring 4o back for Plus and are evaluating 4.1, promised 2x Plus rate limits, clearer model indicators and a manual thinking toggle, routing and memory fixes, slower staged rollout, and to look into voice mode and mid tier pricing.
Most common user requests were to restore 4o and other legacy choices with manual model selection, keep or expand context and usage limits, bring back Standard Voice, preserve warm personality for creative and companion use, improve stability and consistency, and provide advance deprecation timelines.
Return of GPT-4o for Plus users
Question: Users asked why 4o was removed and demanded that it return as a selectable model.
Answer (Sam Altman, CEO): “we are going to bring it back for plus users, and will watch usage to determine how long to support it.”4o and 4.1 availability together, plus voice concerns
Question: Users asked to keep both 4o and 4.1 alongside GPT-5 and raised issues with Advanced Voice Mode.
Answer (Sam Altman, CEO): He said the team is looking into this now, asked whether both 4o and 4.1 are needed or if 4o would suffice, and said he would look into the voice mode issue.Active work on restoring 4o
Question: Users said GPT-5 felt like “wearing the skin of my dead friend” and pleaded to bring 4o back.
Answer (Sam Altman, CEO): “ok we hear you on 4o, working on something now.”Router outage and immediate quality fix
Question: Users reported GPT-5 felt “dumber” and asked what broke.
Answer (Sam Altman, CEO): He said the autoswitcher was down for part of day 1, which made GPT-5 seem worse, and that changes to the routing decision boundary are being deployed so people get the right model more often.Model transparency
Question: Users asked for clear indicators showing which model is responding.
Answer (Sam Altman, CEO): He said ChatGPT will become more transparent about which model answers a given query.Manual control over “thinking”
Question: Users asked for a way to manually trigger or avoid reasoning mode.
Answer (Sam Altman, CEO): He said the UI will change to make it easier to manually trigger thinking.Rate limits for Plus
Question: Plus users asked for higher limits after the update.
Answer (Sam Altman, CEO): He said OpenAI is going to double rate limits for Plus users as rollout completes.Legacy access to 4o under evaluation
Question: Users asked to keep using 4o long term.
Answer (Sam Altman, CEO): He said the team is looking into letting Plus users continue to use 4o and is gathering data on the tradeoffs.Rollout pace and stability
Question: Users asked why access and behavior were inconsistent.
Answer (Sam Altman, CEO): He said rollout to everyone is taking longer due to scale, and noted API traffic roughly doubled in the first 24 hours.Mid-tier plan between Plus and Pro
Question: Users requested a $40-ish tier for solo power users.
Answer (Sam Altman, CEO): “yes we will do something here.”Screenless interfaces, voice, and neural links
Question: Users asked about moving beyond the text box.
Answer (Sam Altman, CEO): “like with voice? yes,” and neural interfaces are “probably quite a ways away.”Longer context windows
Question: Users pressed for more than 32k in ChatGPT.
Answer (Sam Altman, CEO): He said OpenAI has not seen strong demand signals for very long context in ChatGPT, compute is tight, and they are open to supporting longer context if clear use cases emerge, then asked what length users need and for what tasks.Why so much purple in generated design mockups
Question: Users noticed GPT-5 often picks purple in UI designs.
Answer (Michelle Pokrass, Research): She said it is not always purple but it is the model’s favorite color, it is somewhat steerable if users ask for something specific, the bias emerged during training and proved resistant to changes, and the team will work on it in future models.
🗞️ Byte-Size Briefs
Cursor IS choosing OAI over Anthropic for the deafult model. This is quite a shift and partly explains why Anthropic pushed out a Claude update that improves its coding a bit. There's a strong case that GPT-5 could shift a large share of the $1.4B code-assistant spend from Anthropic to OpenAI during the next contract cycle. GPT-5 arrives with a 256 k token window, 45%–80% lower hallucination rates and state-of-the-art coding accuracy at prices that undercut Claude Sonnet by an order of magnitude.
That’s a wrap for today, see you all tomorrow.